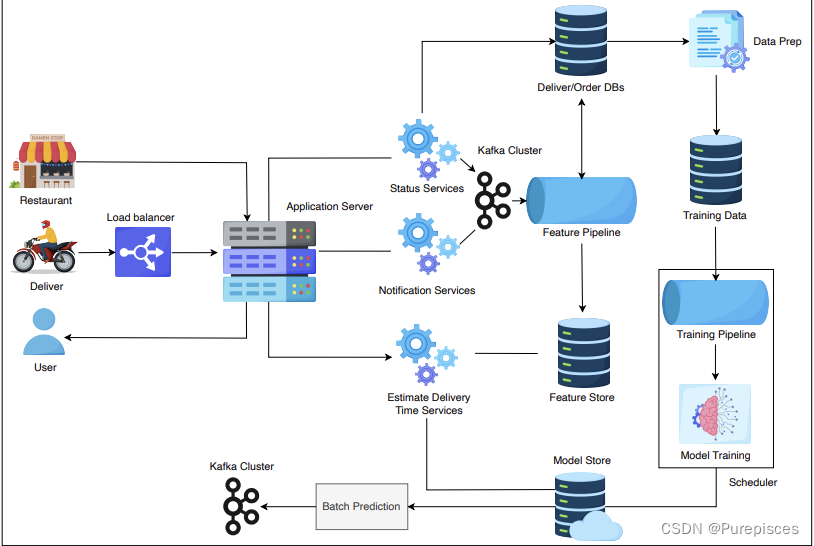
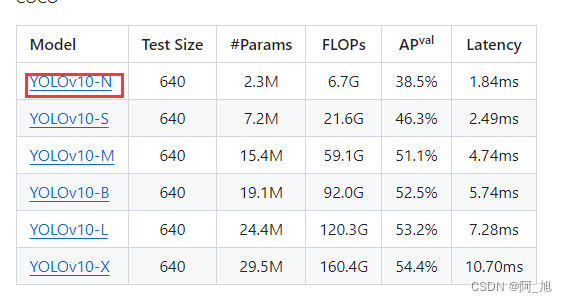
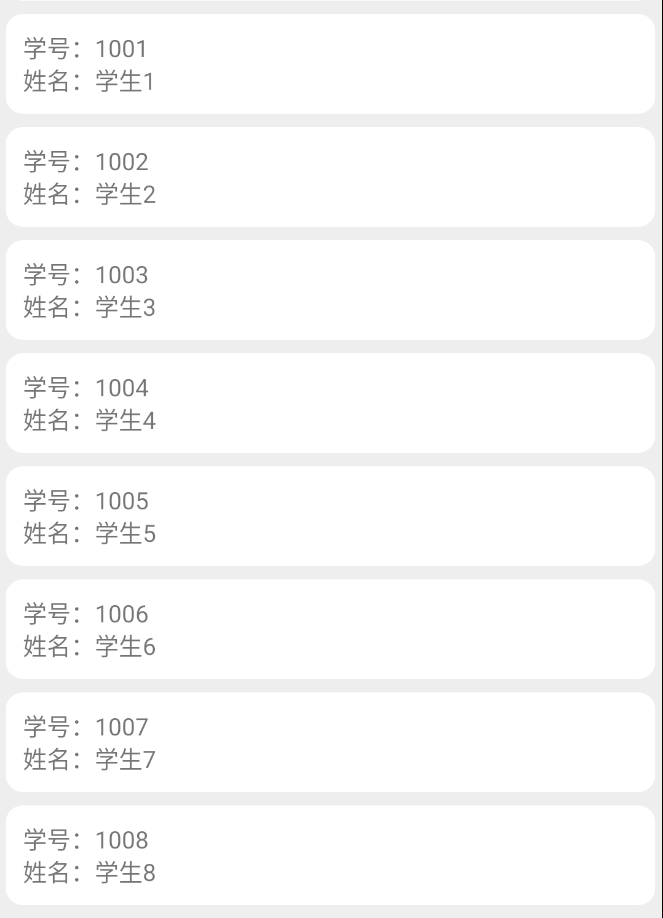
为了完成布置的作业,需要用到spark的本地模式,根本用不到集群,就不想搭建虚拟机,hadoop集群啥的,很繁琐,最后写作业还用不到集群(感觉搭建集群对于我完成作业来说没有什么意义),所以才想办法在windows环境下,直接安装jdk、scala、spark等,使用spark的本地模式来写作业
步骤:
1. 安装jdk
检查了,发现我自己电脑(windows)上已经安装过jdk了,环境变量也配置好了,
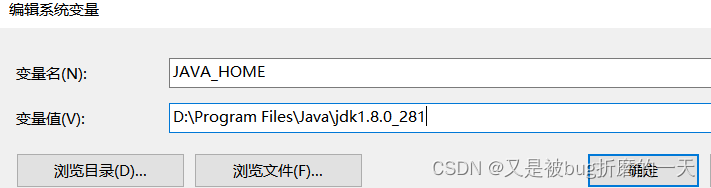
path路径中也设置好了jdk的路径
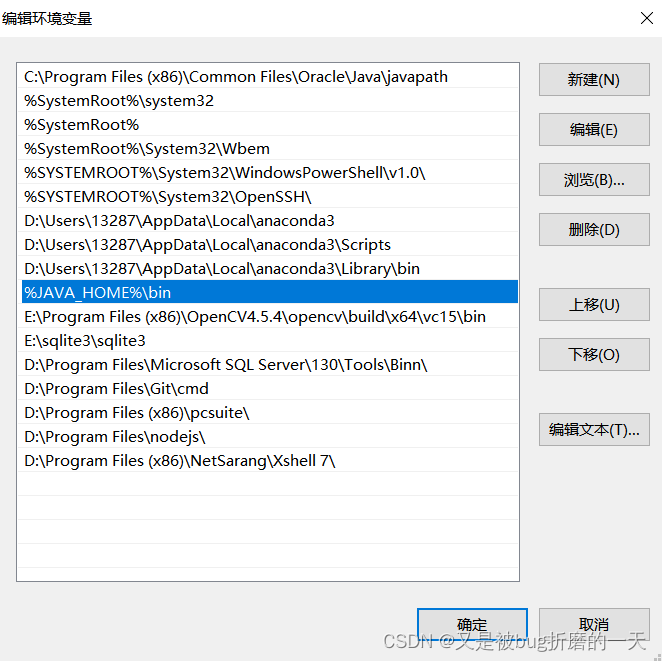
2. 下载安装scala
检查自己电脑上有没有安装scala

很好,没有安装scala,那就从官网上下载2.11.12版本,官网:
The Scala Programming Language (scala-lang.org)


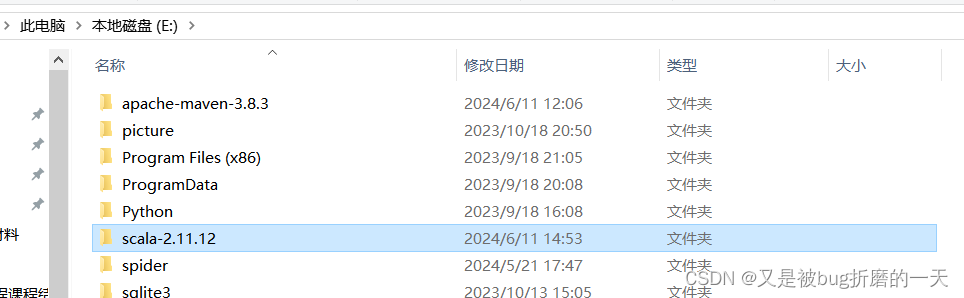
路径是在E盘下:
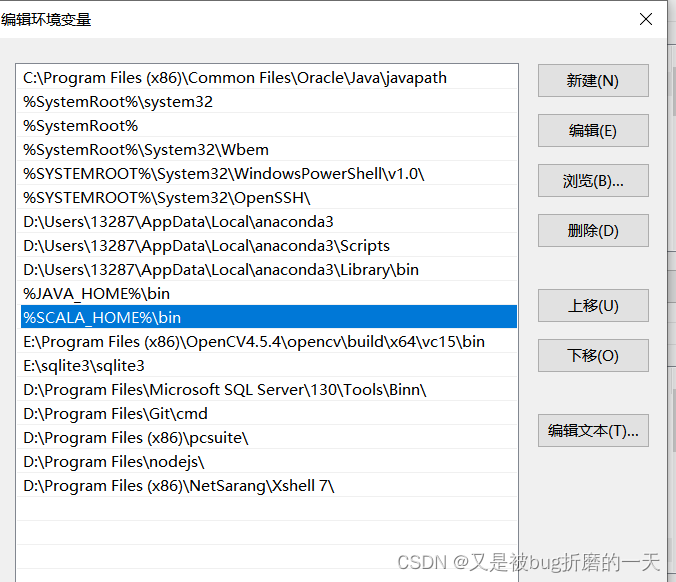
配置环境变量:

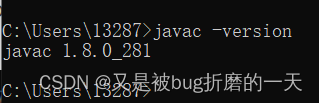
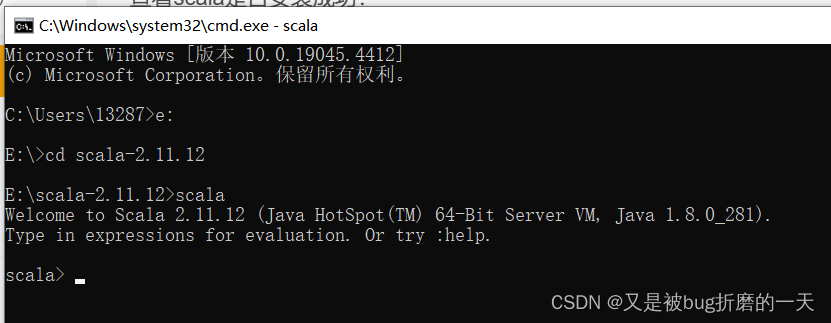
进入cmd,scala的路径下,输入scala,如下图所示,即为成功安装scala
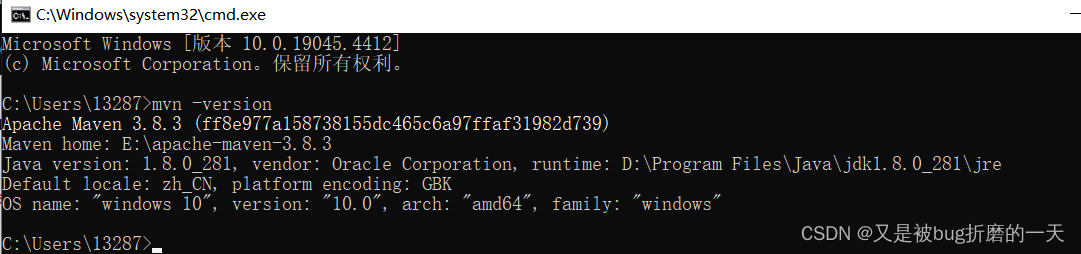
3. 下载maven
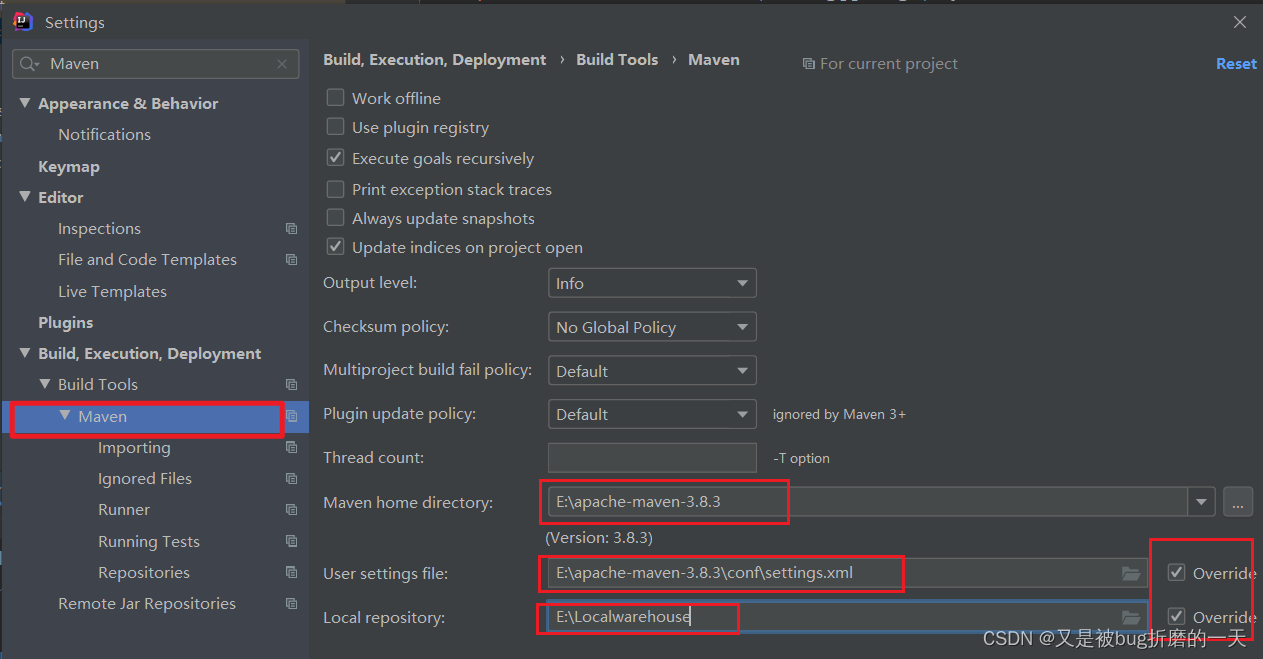
maven已经下载好了,新建一个文件夹Localwarehouse,用来保存下载的依赖文件
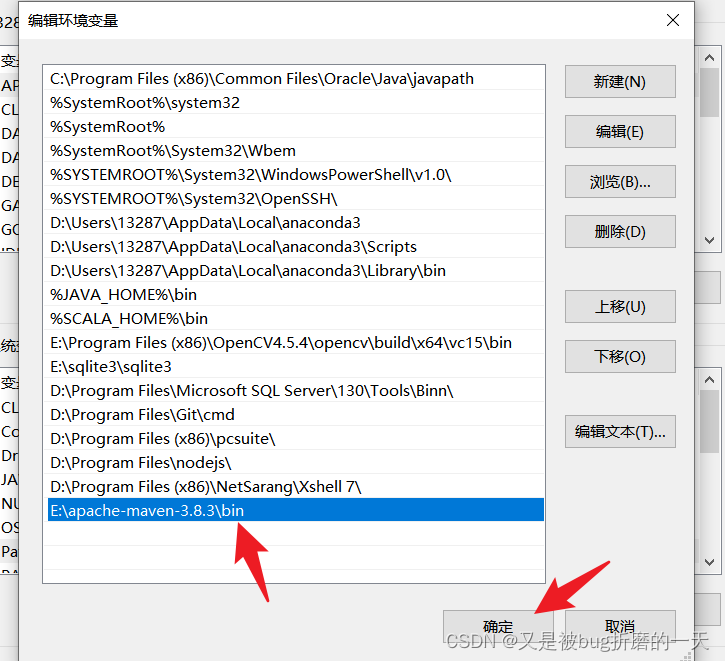
配置maven的系统环境配置
cmd下验证,已经成功
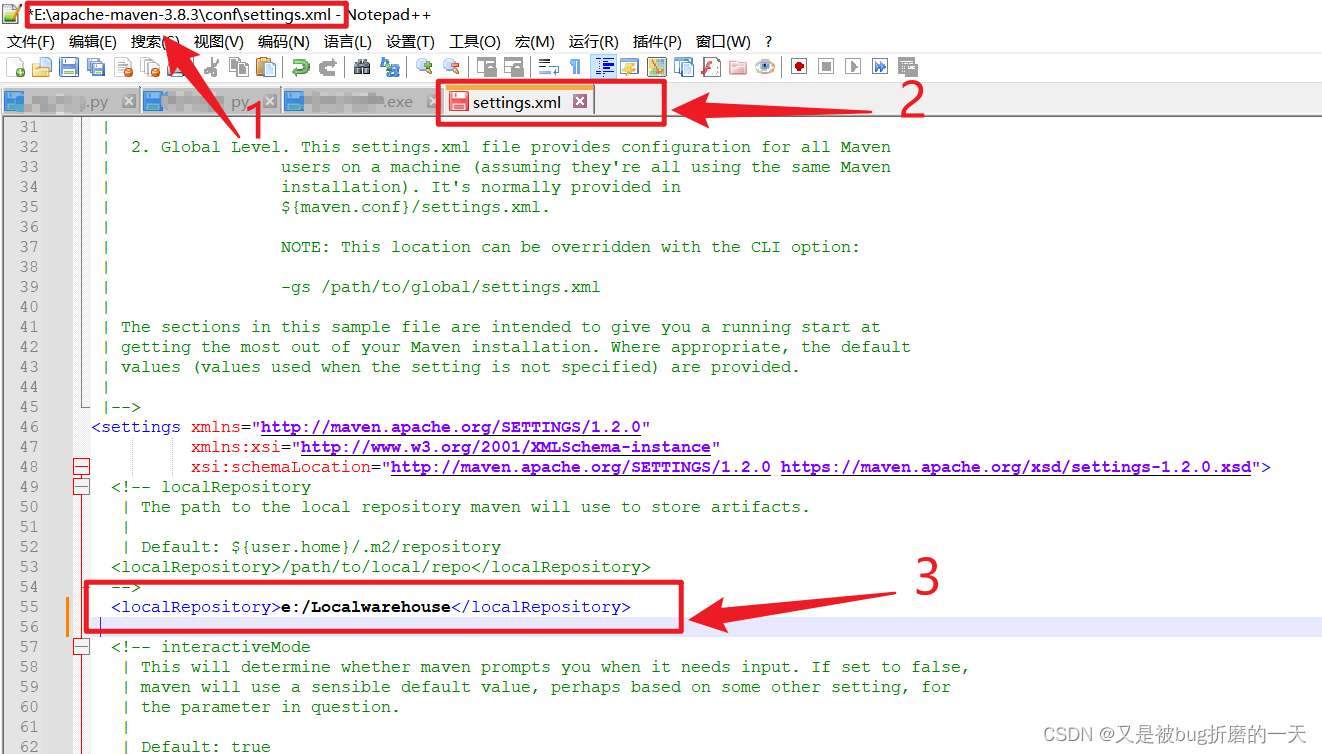
配置maven: 记得修改完文件之后保存!
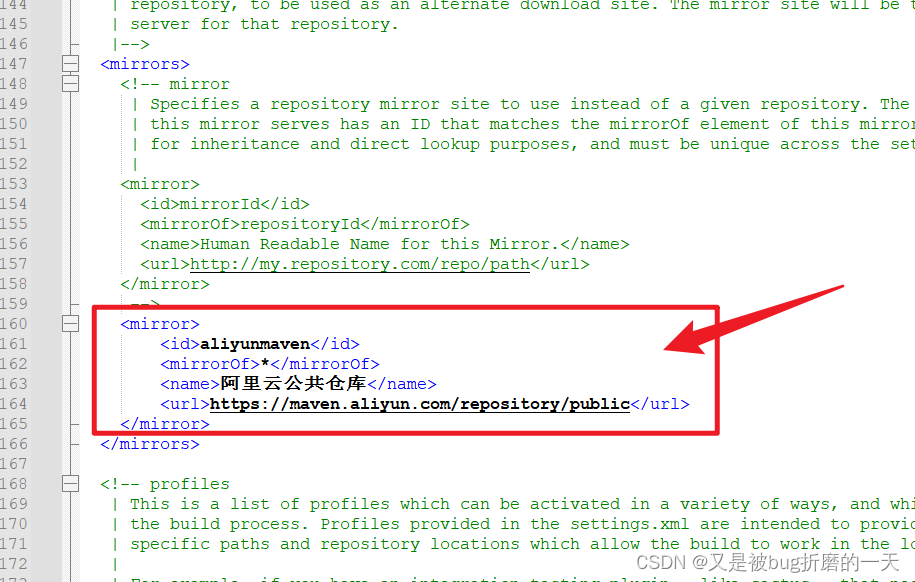
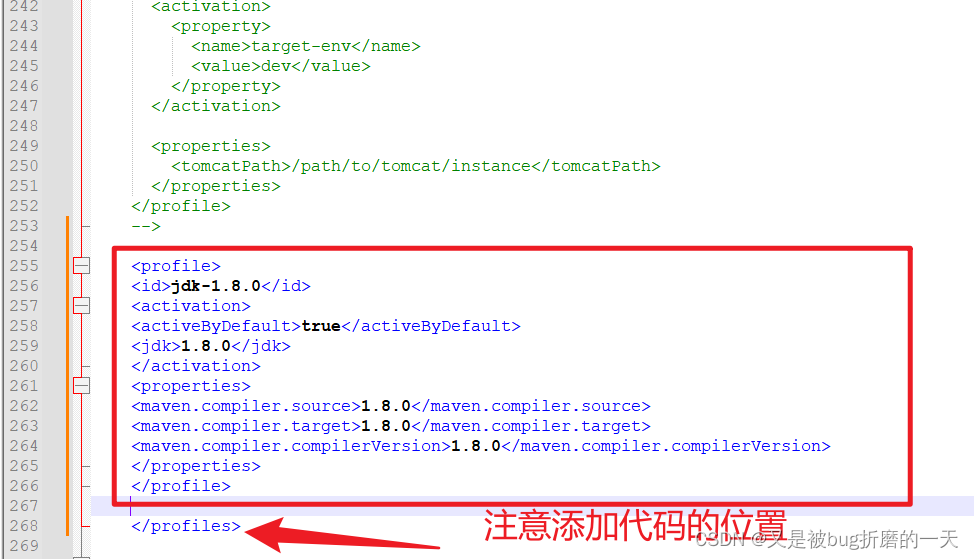
继续添加如下代码用来配置jdk版本
4. 验证idea是否安装好了
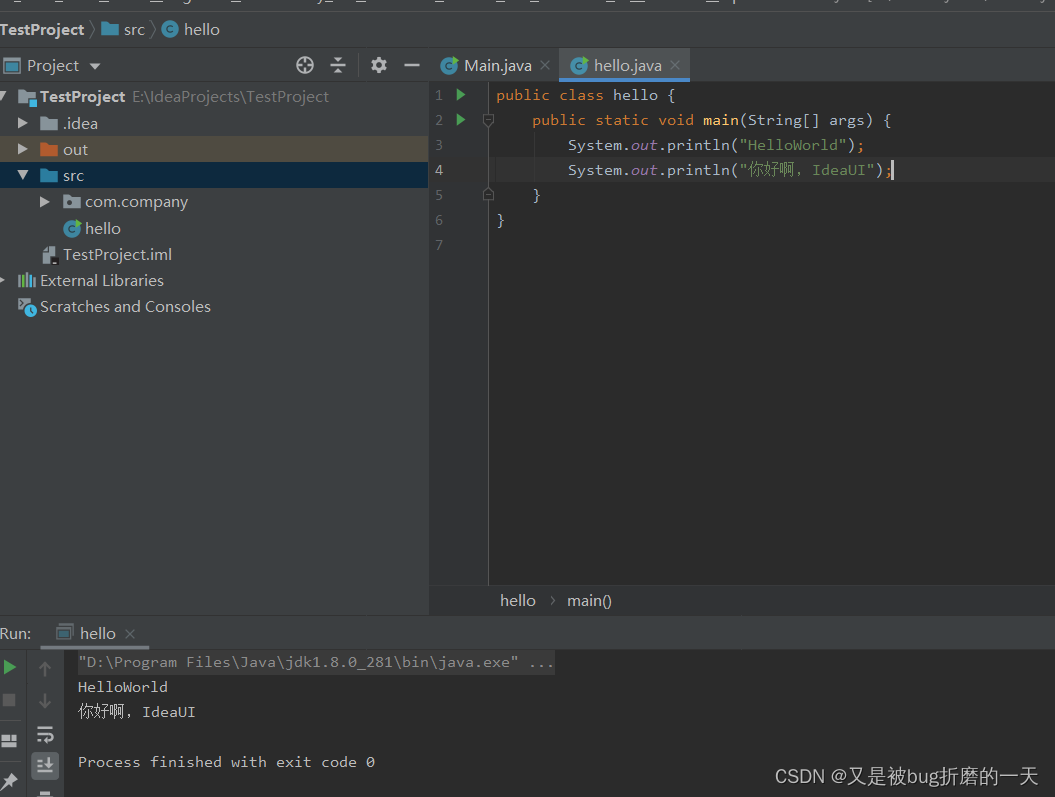
输出hello world 证明安装成功
idea的一些使用方法:
-
字体设置:file–>settings–>输入font–>设置字体样式以及字号大小;
-
快捷生产main方法:psvm;
-
快速生产System.out.println():sout;
-
删除一行:选中需要删除的那一行,ctrl+y;
5. 将maven加载到idea中
6. 安装scala插件
由于我的idea在plugins里搜索不到scala插件,所以可以官网上下载跟自己idea版本对应的scala插件,在idea安装目录下的plugins下,然后重启idea,就可以搜索到scala插件已经安装上了。


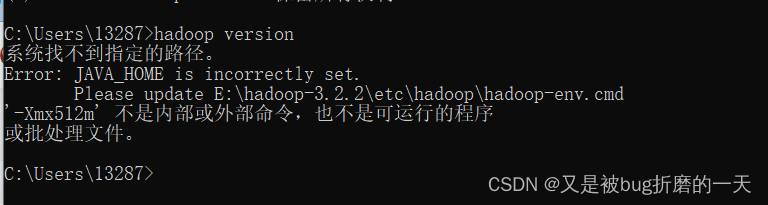
7.下载安装hadoop
Index of apache-local/hadoop/core/hadoop-3.2.2![]() https://repo.huaweicloud.com/apache/hadoop/core/hadoop-3.2.2/环境变量配置好后,执行 hadoop version 出现以下异常
https://repo.huaweicloud.com/apache/hadoop/core/hadoop-3.2.2/环境变量配置好后,执行 hadoop version 出现以下异常
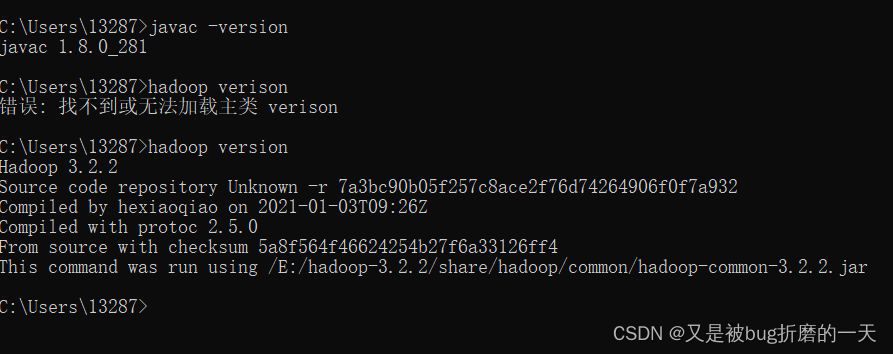
解决办法:

都修改完之后,执行hadoop version成功
8.Spark 安装和配置
安装的是3.0.2的版本
下载地址:
https://archive.apache.org/dist/spark/spark-3.0.2/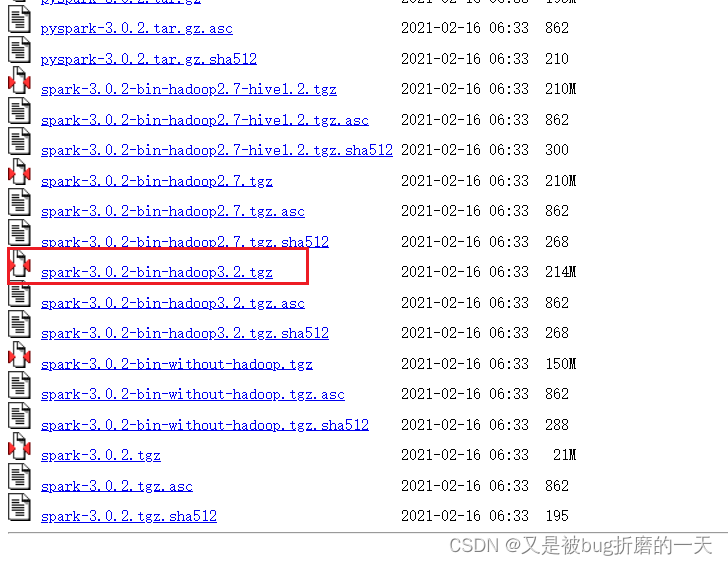
解压spark安装包,解压到E:\spark-3.0.2-bin-hadoop3.2

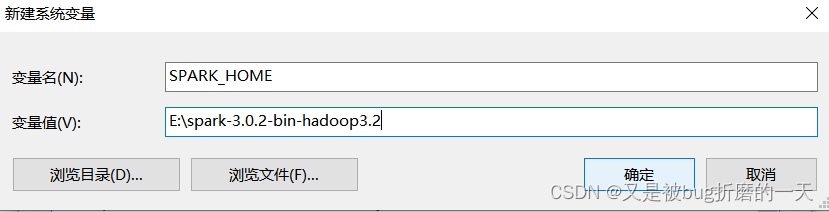
在系统环境变量中添加SPARK_HOME,并将SPARK_HOME添加到系统环境变量的Path中。
cmd中执行spark-shell,出现如下警告
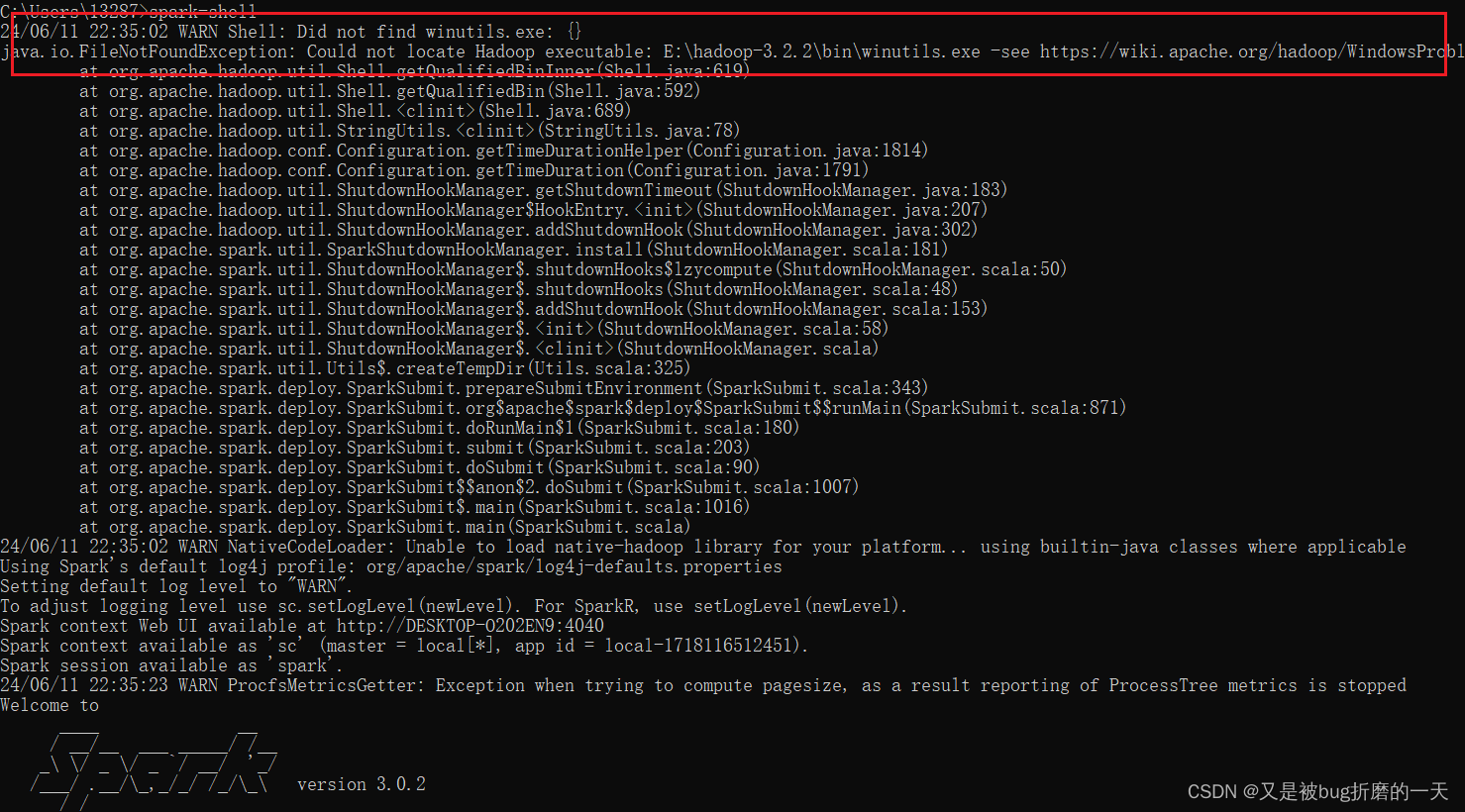
解决办法:
到这里 GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows 下载和你的 Hadoop 版本对应的工具所在的整个目录,比如 hadoop-3.2.0
把下载的文件中的 winutils.exe 拷贝到上述文件夹中
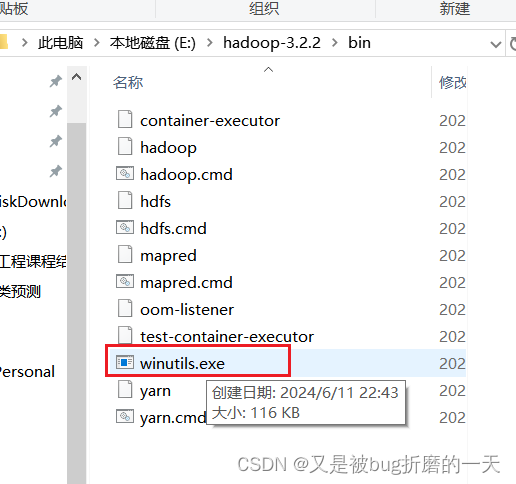
重新运行spark-shell,执行成功
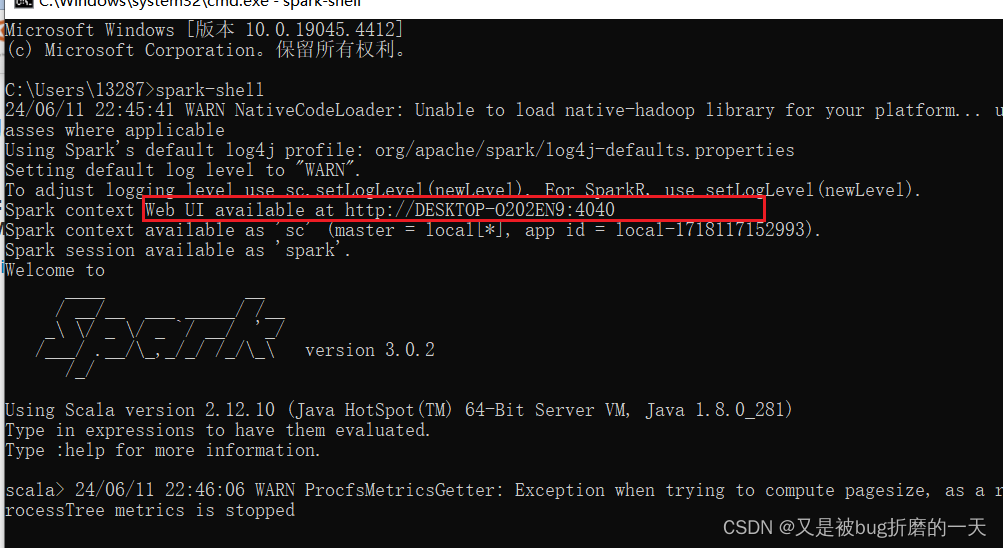
可通过http://DESKTOP-O202EN9:4040来查看web UI界面
9. idea里配置spark
新建maven项目、配置pom.xml文件等主要参考的是: