一、优化思路梳理
课前准备
在昨天的内容中,我们通过使用更强的集成模型以及模型融合的方法,已经顺利将比赛分数提高至前20%。但正如此前所说,之前的一系列操作只不过是遵循了常规操作流程进行的数据处理与建模,若希望能够更进一步提高模型分数,则需要因地制宜、活学活用,在考虑到当前数据及特殊情况下进行有针对性的策略调整。本节内容我们将结合此前搜集到的所有数据集信息及业务背景信息,进行最后一轮的特征优化与模型优化,并最终将排名提升至前1%。
当然,这个过程并不简单,若需要跟上本节内容的讨论,需要非常熟悉当前数据集的基本情况,也就是需要深度掌握Day1-2所介绍内容,从而才能理解接下来的特征优化相关内容;此外也需要对Day 5中介绍的集成学习建模策略,即在使用原生算法库情况下,如何配合交叉验证过程、借助贝叶斯优化器进行超参数搜索,并最终输出交叉验证的测试集预测均值作为最终预测结果的一整个流程,从而才能更快速的理解本节开始我们对模型训练流程进行的优化与调整;此外,我还将在本节介绍非常适用于竞赛场景的融合技巧,亦可作为同学日后参与竞赛时的有力工具。不过没有跟上此前的内容的同学也不用担心,本节内容将更加强调优化过程的整体逻辑,并尽可能从一个更加通俗且准确的角度进行解释,大家也可以在听完本节内容后再去回顾此前Day1-5的相关内容,以终为始、未尝不可,通过反复观看,也相信大家会对本节内容有一个更深刻的理解。
整体优化思路
对于机器学习来说,总的来看有两种建模思路,其一是通过特征工程方法进一步提升数据质量,其二则是通过更加复杂的模型或更加有效的模型融合技巧来提升建模效果,并且就二者的关系来看,正如时下流行的观点所说,特征工程将决定模型效果上界,而建模过程则会不断逼近这个上界。但无论如何,在优化的过程中,需要二者配合执行才能达到更好的效果。
image-20211210125340547
1.特征优化思路
首先,先来看特征优化思路。在此前的建模过程中,我们曾不止一次的对特征进行了处理,首先是在数据聚合时(以card_id进行聚合),为了尽可能提取更多的交易数据信息与商户信息带入进行模型,我们围绕交易数据表和商户数据表进行了工程化批量特征衍生,彼时信息提取流程如下:

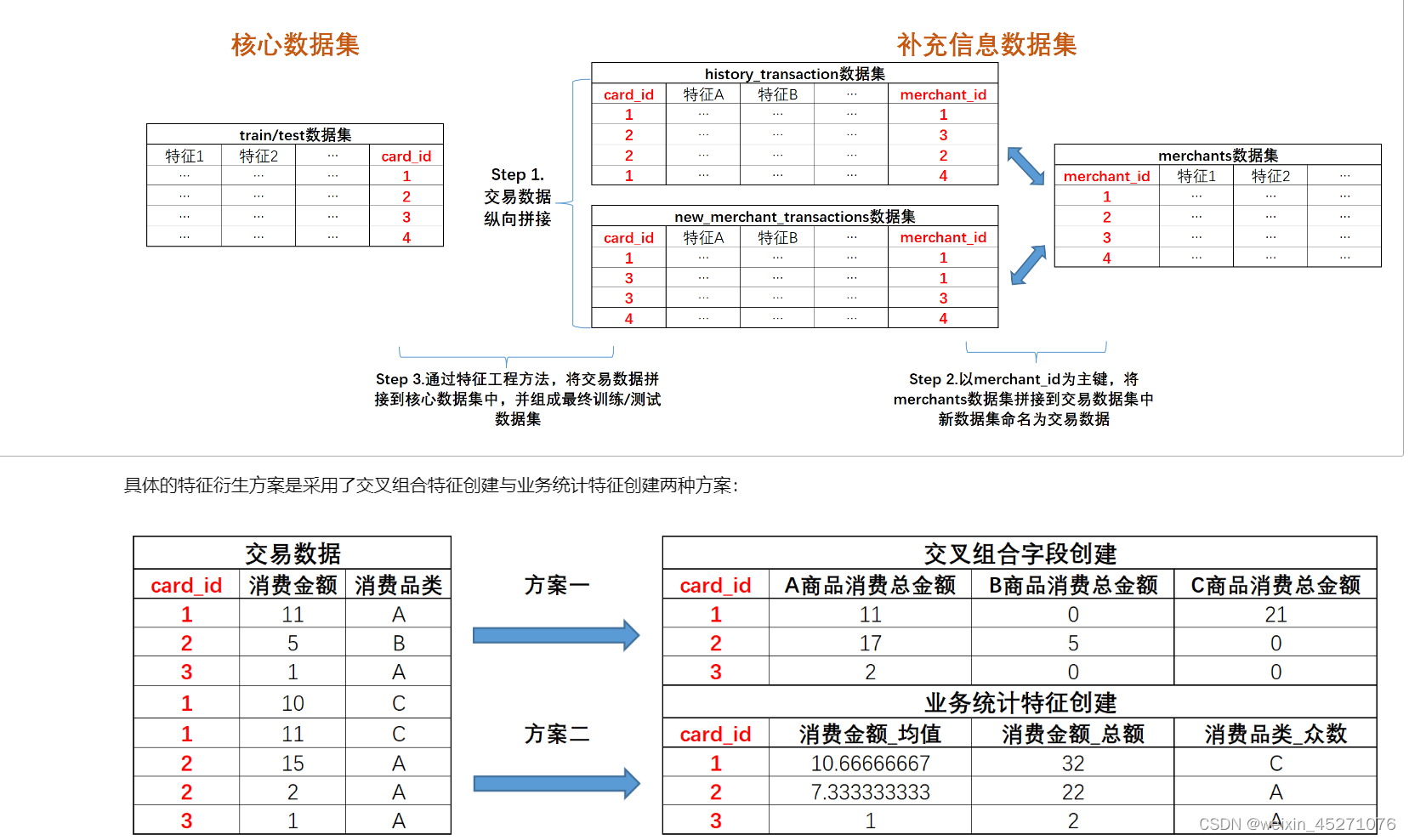
该过程的详细讲解,可参考Day 3-Day 4的课程内容。总而言之,通过该过程,我们顺利的提取了交易信息表和商户信息表中的数据带入进行建模,并且借助随机森林模型,顺利跑通Baseline。但值得一提的是,在上述流程中,我们其实只是采用了一些工程化的通用做法,这些方法是可以快速适用于任何数据集的特征衍生环节,同时这样的方法也应该是所有建模开始前必须尝试的做法,但既然是“通用”方法,那必然无法帮我们在实际竞赛中脱颖而出。
当然,我们也曾尝试过进行有针对性的特征优化,在Day 5的内容中,我们曾采用NLP方法用于提取特征ID列的信息,并得到了一系列能够更加细致描述用户行为信息与商品偏好的特征,借助该特征,我们最终训练得出了一个效果更好的模型,该结果也进一步验证了特征优化对模型效果提升所能起到的作用。接下来我怕们也将尝试进一步进行有针对性的特征优化。
总体来看,特征优化需要结合数据集当前的实际情况来制定,在已有批量衍生的特征及NLP特征的基础上,针对上述数据集,还可以有以下几点优化方向:
用户行为特征
首先,我们注意到,每一笔信用卡的交易记录都有交易时间,而对于时间字段和文本字段,普通的批量创建特征的方法都是无法较好的挖掘其全部信息的,因此我们需要围绕交易字段中的交易时间进行额外的特征衍生。此处我们可以考虑构造一些用于描述用户行为习惯的特征(经过反复验证,用户行为特征是最为有效的提高预测结果的特征类),包括最近一次交易与首次交易的时间差、信用卡激活日期与首次交易的时间差、用户两次交易平均时间间隔、按照不同交易地点/商品品类进行聚合(并统计均值、方差等统计量)。
此外,我们也知道越是接近当前时间点的用户行为越有价值,因此我们还需要重点关注用户最近两个月(实际时间跨度可以自行决定)的行为特征,以两个月为跨度,进一步统计该时间周期内用户的上述交易行为特点,并带入模型进行训练。
二阶交叉特征
在此前的特征衍生过程中,我们曾进行了交叉特征衍生,但只是进行了一阶交叉衍生,例如交易额在不同商品上的汇总,但实际上还可以进一步构造二阶衍生,例如交易额在不同商品组合上的汇总。通常来说更高阶的衍生会导致特征矩阵变得更加稀疏,并且由于每一阶的衍生都会创造大量特征,因此更高阶的衍生往往也会造成维度爆炸,因此高阶交叉特征衍生需要谨慎。不过正如此前我们考虑的,由于用户行为特征对模型结果有更大的影响,因此我们可以单独围绕用户行为数据进行二阶交叉特征衍生,并在后续建模前进行特征筛选。
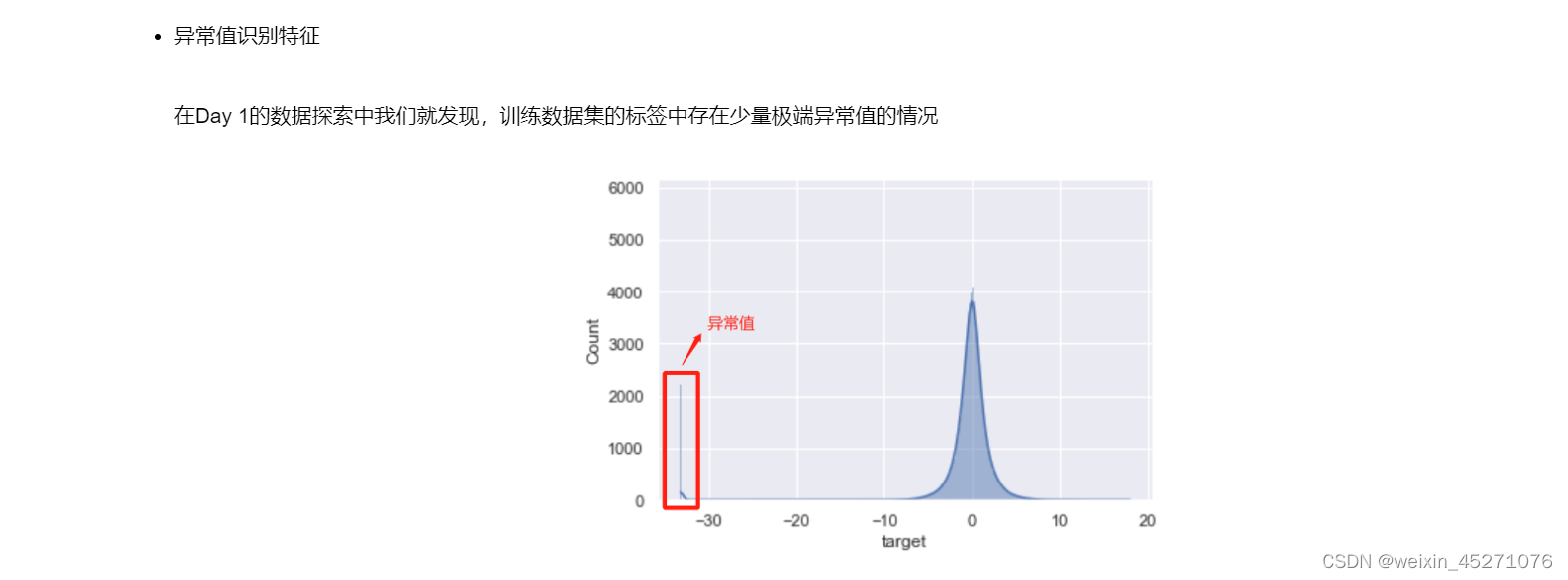
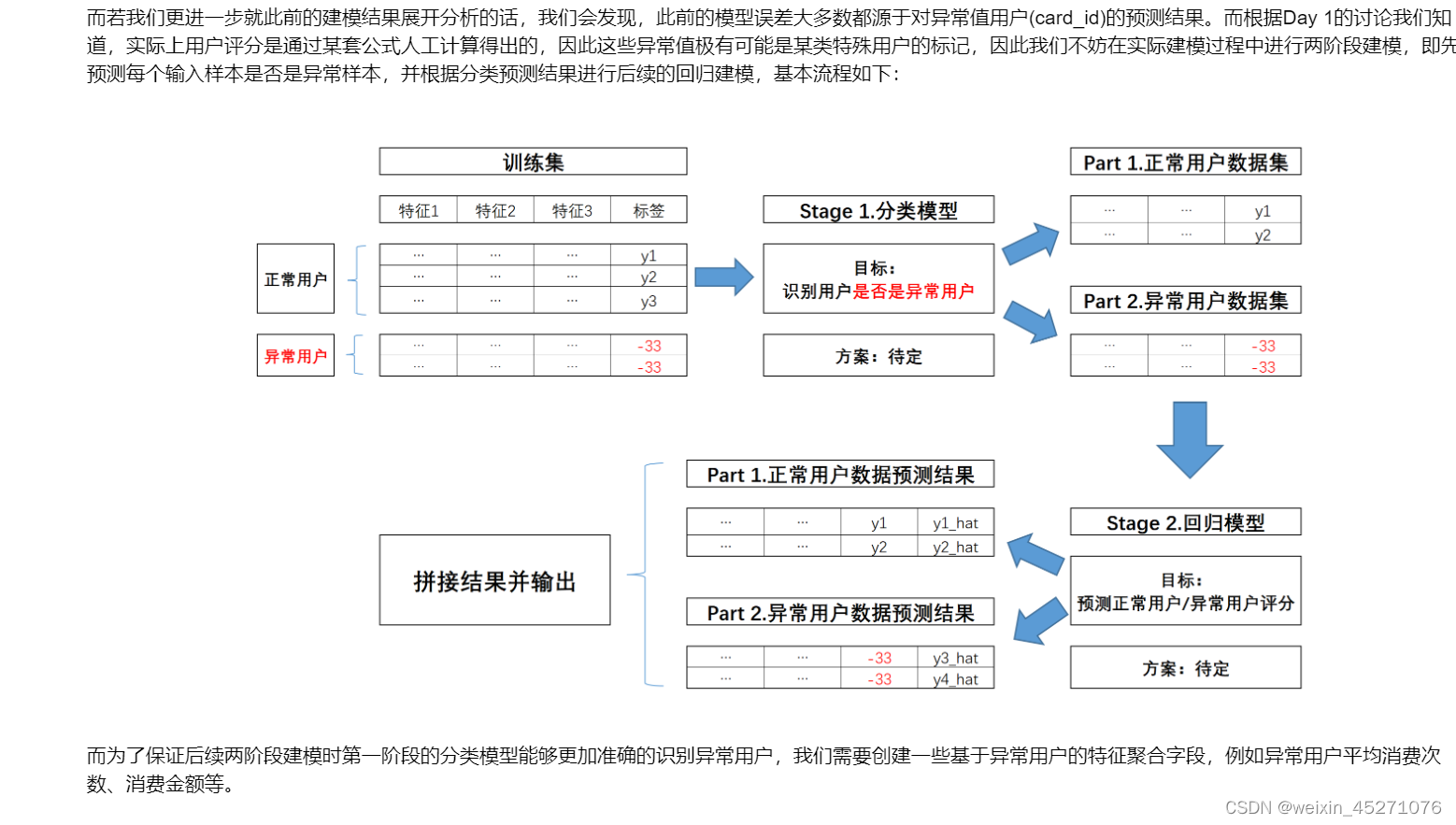
异常值识别特征
在Day 1的数据探索中我们就发现,训练数据集的标签中存在少量极端异常值的情况