链接: R语言实战——中国职工平均工资的变化分析——相关与回归分析
1、模型诊断和评估的方法
1. 残差分析
1、残差图 (Residual Plot):用于检查残差是否存在非随机模式。理想情况下,残差应随机分布在零附近。
2、Q-Q 图 (Quantile-Quantile Plot):用于检查残差是否符合正态分布。如果残差接近正态分布,Q-Q 图上的点应接近一条直线。
3、Shapiro-Wilk Test:用于检验残差的正态性。p 值大于 0.05 表示残差近似正态分布。
2. 多重共线性检测
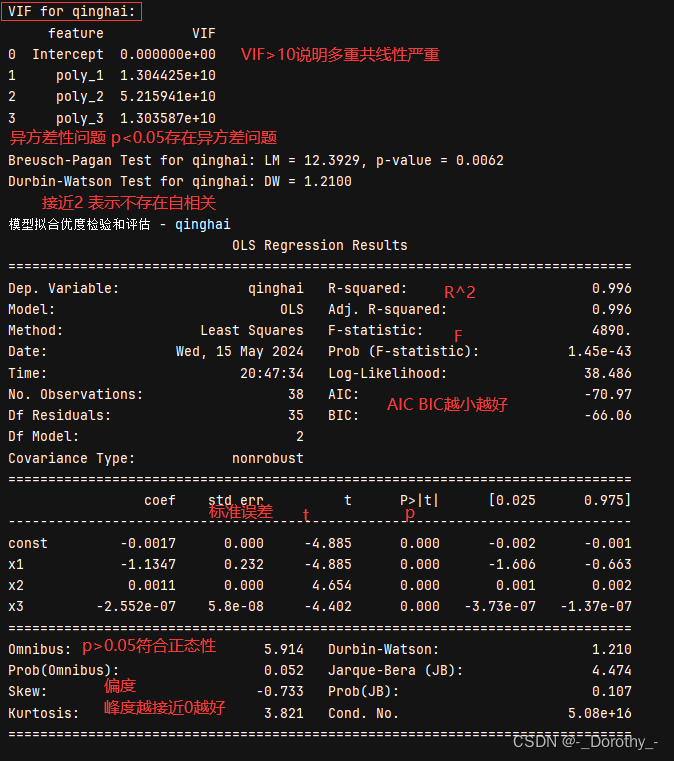
方差膨胀因子 (VIF, Variance Inflation Factor):用于检测多重共线性。如果 VIF 值大于 10,说明存在严重的多重共线性问题。
3. 模型拟合优度
R² 和调整后的 R²:衡量模型解释变异的能力。调整后的 R² 考虑了自变量个数,对模型复杂度进行了惩罚。
AIC (Akaike 信息准则) 和 BIC (贝叶斯信息准则):用于模型比较,较低的 AIC 或 BIC 表示模型更好。
4. 异常值和影响点
标准化残差 (Standardized Residuals):用于识别异常值。绝对值大于 2 或 3 的残差可能是异常值。
Cook’s 距离 (Cook’s Distance):用于识别对模型有显著影响的数据点。Cook’s 距离大于 1 的点可能是影响点。
5. 异方差性检验
Breusch-Pagan Test:用于检测异方差性。如果 p 值小于 0.05,说明存在异方差性问题。
White Test:另一种异方差性检测方法。
6. 自相关性检验
Durbin-Watson Test:用于检测残差的自相关性。值接近 2 表示不存在自相关性,值接近 0 或 4 表示存在自相关性。
7. 预测性能评估
交叉验证 (Cross-Validation):将数据集分成训练集和测试集,评估模型在未见过的数据上的表现。
均方误差 (MSE, Mean Squared Error) 和 均方根误差 (RMSE, Root Mean Squared Error):用于衡量模型的预测误差。
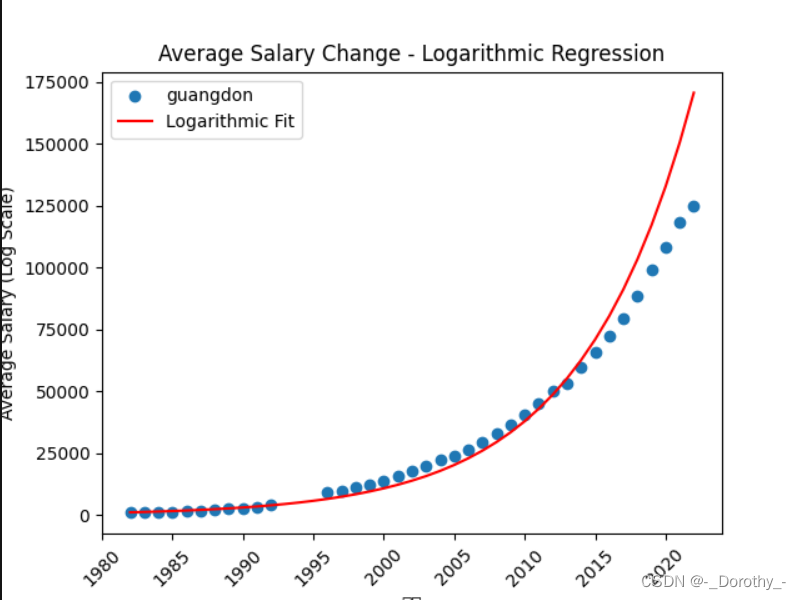
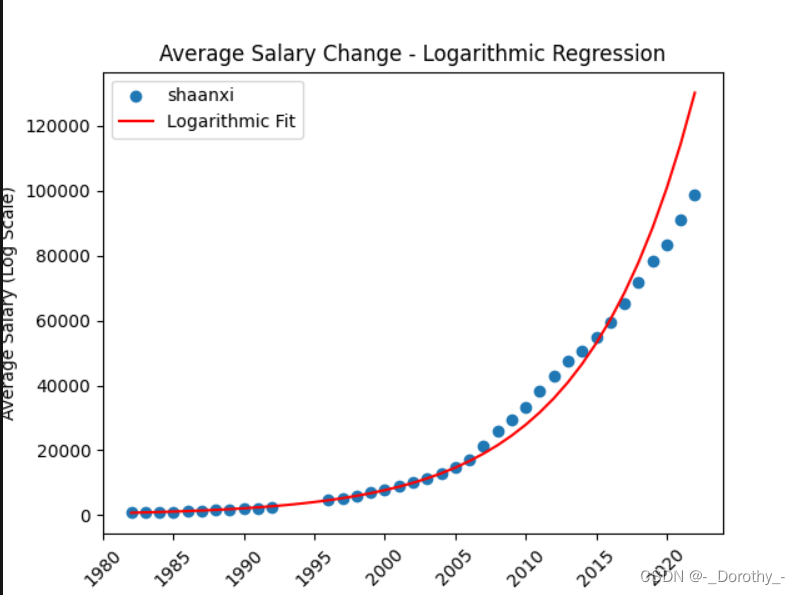
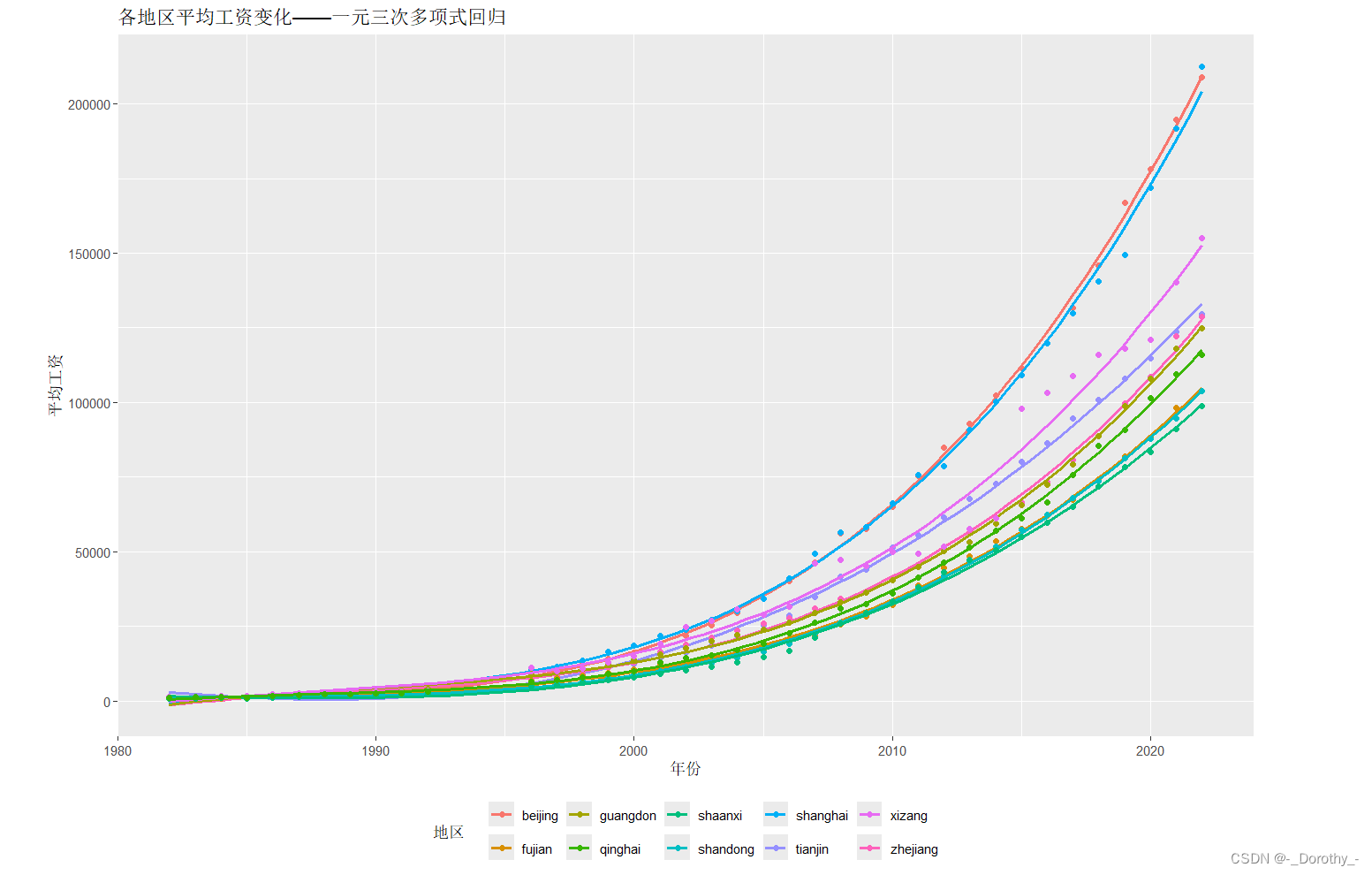
2、指数回归(对数模型)——地区
由于指数模型的值会过于大,会出现以下警告
: RuntimeWarning: overflow encountered in exppredicted_values_exp = np.exp(predicted_values)
这个警告通常是由于指数函数中的值过大而引起的。当预测值非常大时,应用指数函数可能会导致数值溢出(overflow)
因此:使用对数函数:如果数据呈现指数型增长,可以考虑使用对数函数进行拟合和预测。这样可以将指数型增长的问题转化为线性回归问题。
(1)构建对数模型并可视化
(2)模型诊断的评估
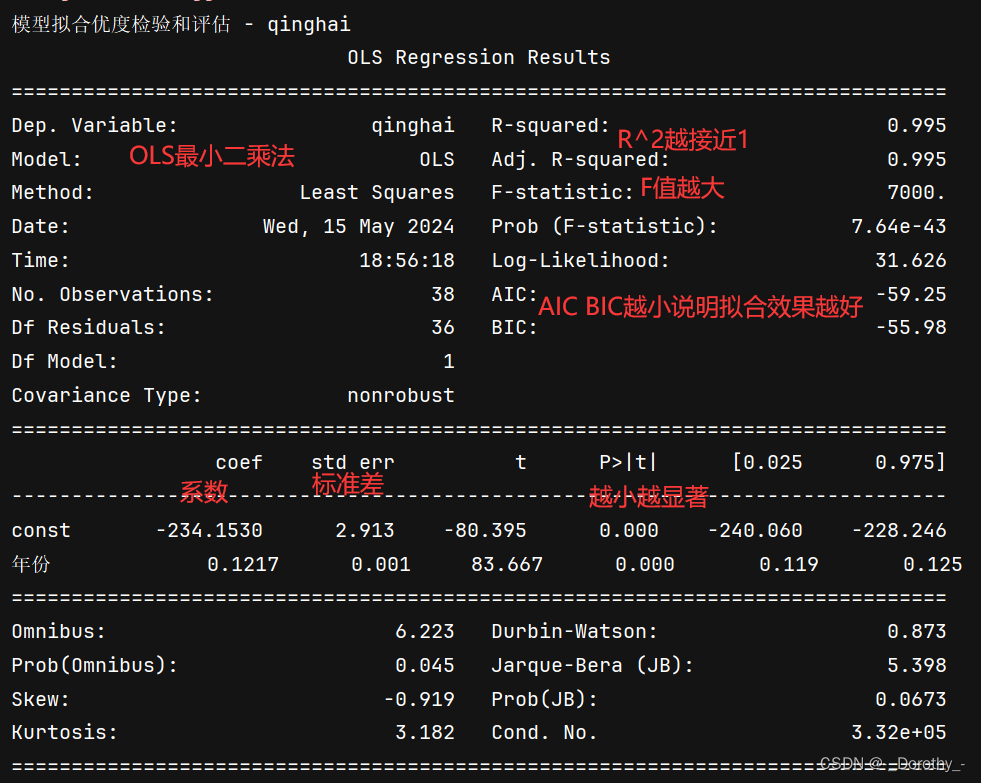
- Omnibus(Omnibus test of normality):
这个统计量是对模型中误差项的正态性进行综合检验的统计量。正态性是线性回归模型的一个重要假设,即模型的残差应该近似服从正态分布。Omnibus统计量的p值提供了一个关于模型中误差项是否服从正态分布的检验结果。如果p值低于某个显著性水平(通常是0.05),则拒绝了误差项服从正态分布的假设。p值应该越大越好,因为大的p值表示误差项符合正态分布的假设越合理。 - Skewness(Skewness of residuals):
偏度是衡量数据分布偏斜程度的统计量。在线性回归模型中,残差的偏度可以用来检验误差项是否符合正态分布。如果残差的偏度接近于0,则表示数据分布大致对称。如果偏度值大于0,则表示数据分布右偏,即正偏。如果偏度值小于0,则表示数据分布左偏,即负偏。通常认为,偏度的绝对值大于2时,数据分布具有显著的偏斜。偏度应该接近于0,因为接近于0表示数据分布大致对称,符合正态分布的特征。 - Kurtosis(Kurtosis of residuals):
峰度是衡量数据分布峰态(峰的陡峭程度)的统计量。在线性回归模型中,残差的峰度可以用来检验误差项是否符合正态分布。如果残差的峰度接近于0,则表示数据分布具有正常的峰态。如果峰度值大于0,则表示数据分布具有尖峰,即峰态较高。如果峰度值小于0,则表示数据分布扁平,即峰态较低。与偏度类似,通常认为,峰度的绝对值大于2时,数据分布具有显著的峰态。峰度应该接近于0,因为接近于0表示数据分布的峰态与正态分布相似,没有明显的尖峰或扁平。 - Durbin-Watson statistic:
杜宾-沃森统计量是用来检验残差是否存在自相关(序列相关)的统计量。自相关是指残差之间的相关性,如果残差之间存在自相关,意味着模型中的一些信息没有被完全捕捉到,可能导致模型的估计结果不准确。Durbin-Watson统计量的取值范围为0到4之间,如果接近于2,则表示残差之间不存在自相关;如果接近于0或4,则表示存在正向或负向自相关。通常认为,当Durbin-Watson统计量的值在1.5到2.5之间时,不存在严重的自相关问题。值接近于2,因为接近于2表示残差之间不存在自相关,即模型中没有未被捕捉到的序列相关性。
Q-Q图
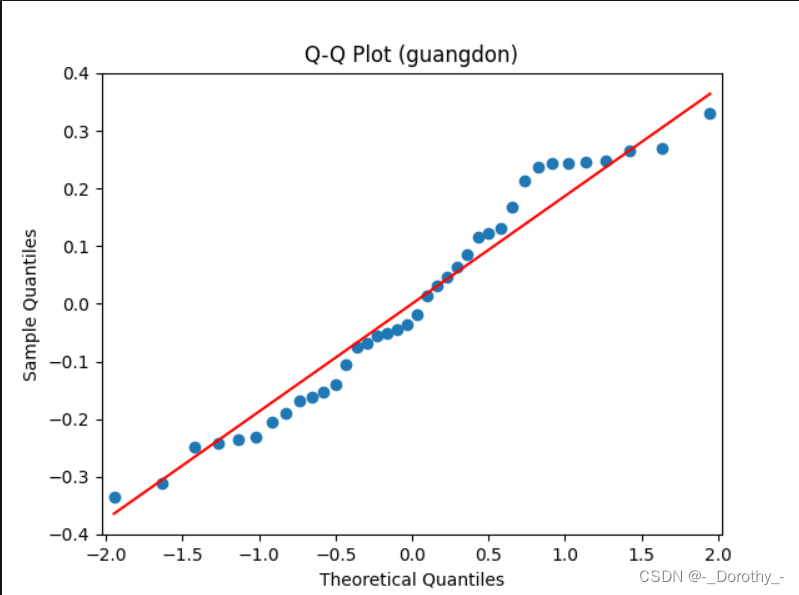
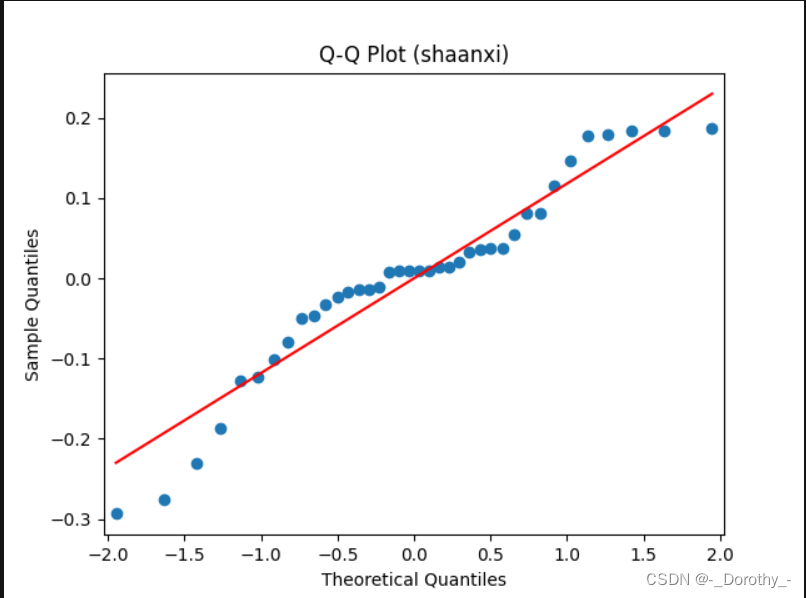
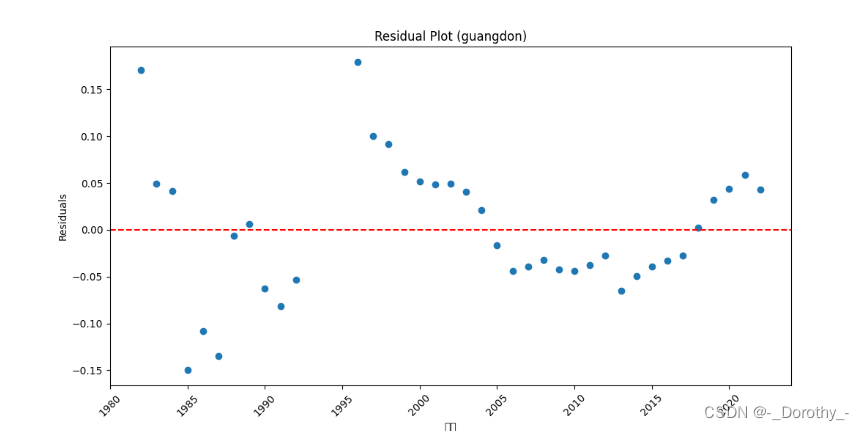
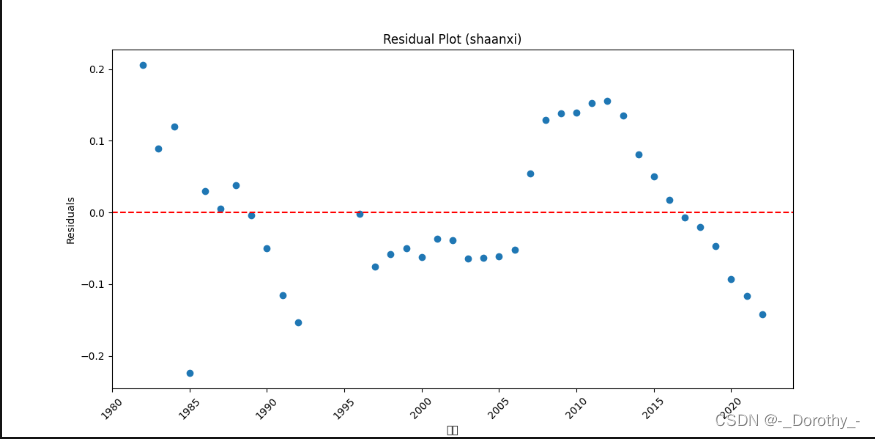
残差图
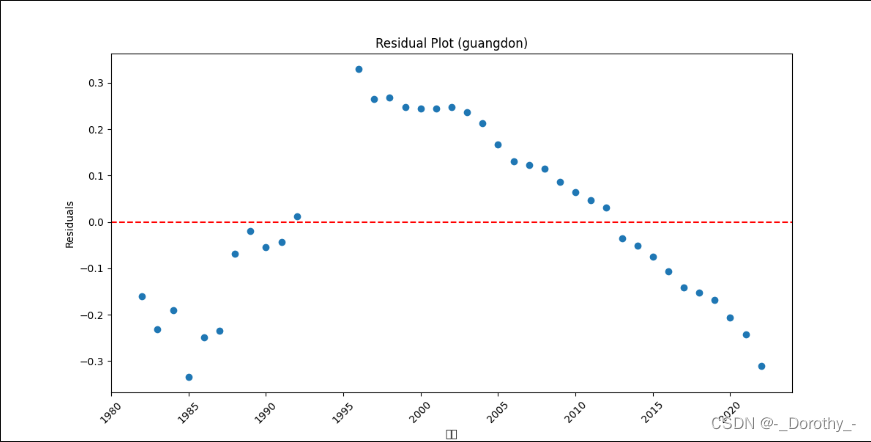
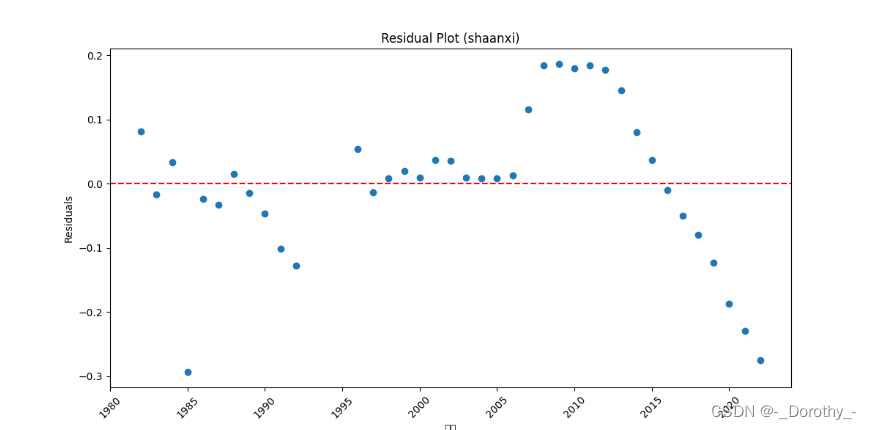
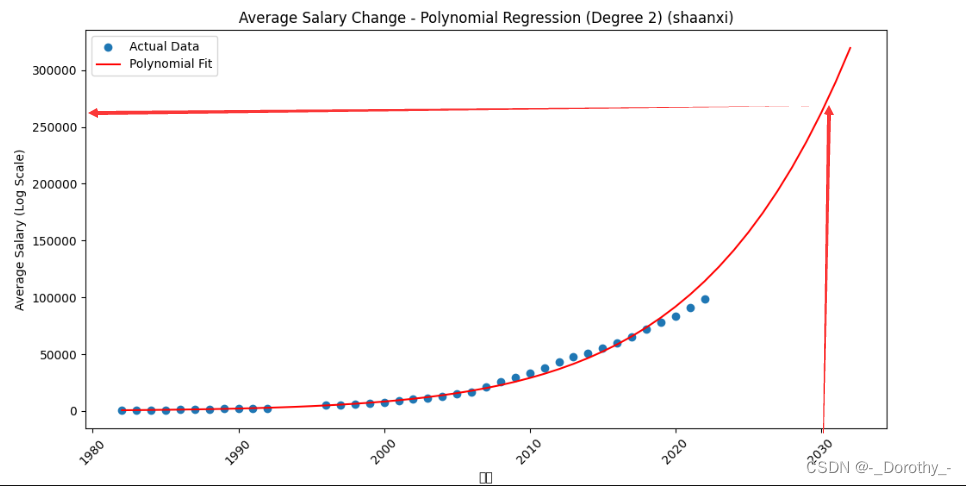
3、多项式回归及检验——地区
(1)构建模型并可视化
(2)模型诊断评估
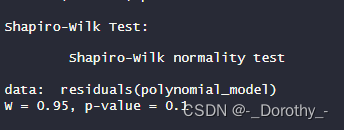
- Shapiro-Wilk Test
W 值:Shapiro-Wilk Test 的统计量。这个值接近于1时,表示样本数据与正态分布相符。
p 值:Shapiro-Wilk Test 的显著性水平。如果 p 值小于某个阈值(通常为 0.05),我们拒绝原假设,认为数据不服从正态分布。反之,如果 p 值大于 0.05,我们不能拒绝原假设,认为数据服从正态分布。
作用和意义
Shapiro-Wilk Test 的主要作用是检验数据正态性,这在统计分析中非常重要,因为许多统计方法(如 t 检验、回归分析)假设数据是正态分布的。如果数据不符合正态分布,这些方法的结果可能不可靠。
残差正态性:在回归分析中,残差应该近似正态分布。这是因为正态分布的残差意味着模型的假设是合理的,且估计的系数和预测是可靠的。
模型诊断:如果残差不符合正态分布,可能表明模型不适合数据,或者数据中存在异常值、异方差性等问题。
Q-Q图
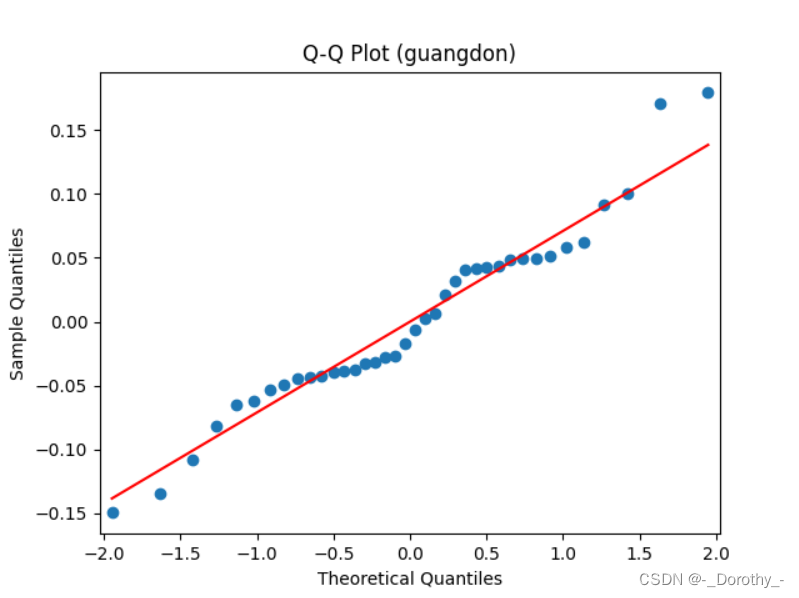
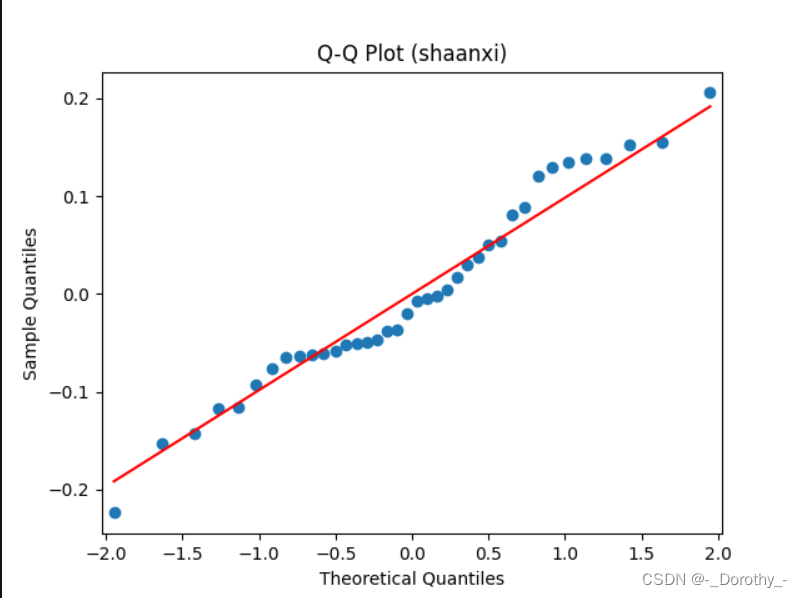
残差图
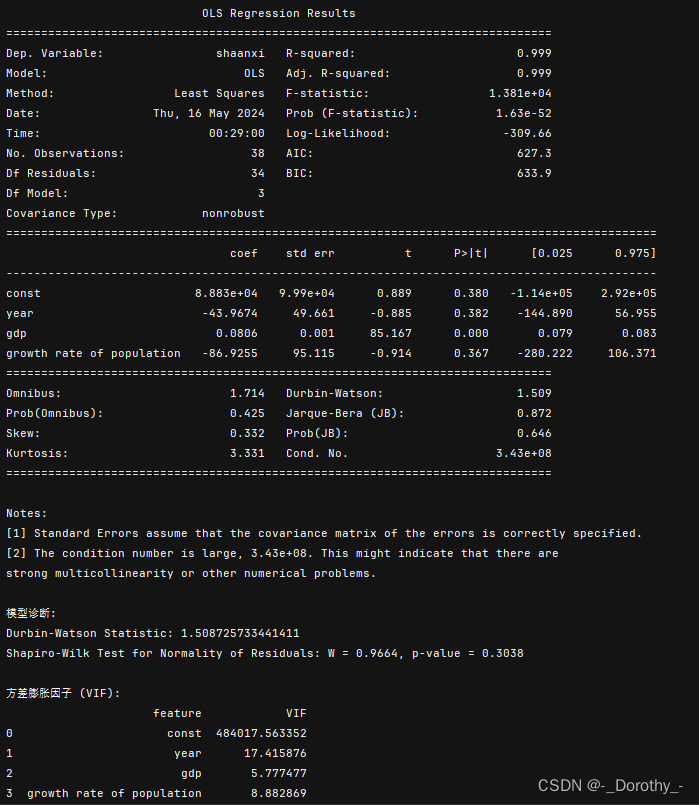
4、多元线性回归(增加变量gdp、人口增长率)
5、预测
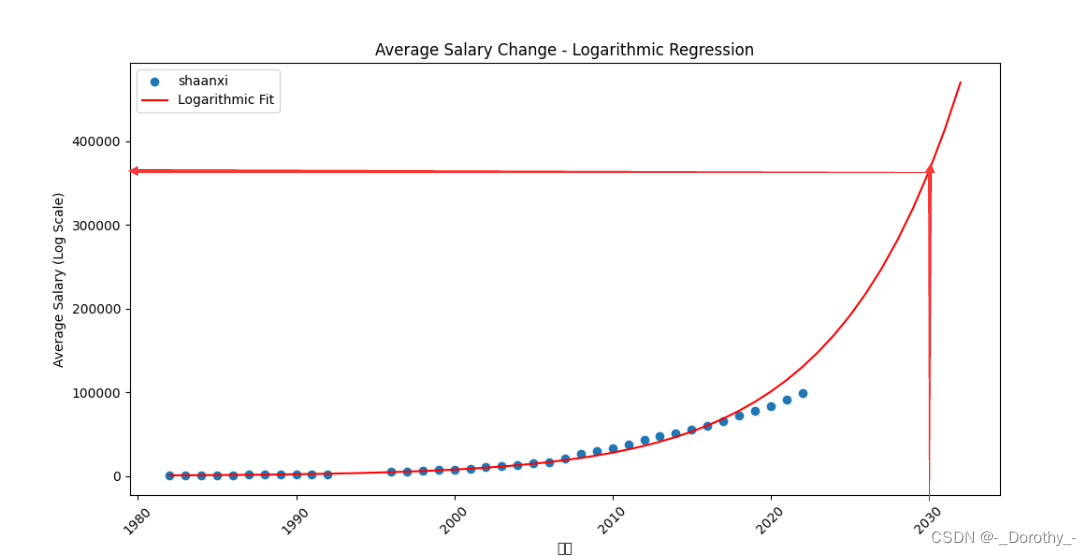
(1)指数预测
(2)多项式预测