目录
1 再谈构造函数
2 类中的隐式类型转换
3 Static成员
4 友元和内部类
5 匿名对象
6 编译器的一些优化
1 再谈构造函数
先看一段代码:
class Date
{
public :Date(int year, int month, int day){_year = year;_month = month;_day = day;}
private:int _year;int _month;int _day;
};
int main()
{Date d1;return 0;
}
当我们生成解决方案的时候,系统会报错:没有默认的构造函数,因为我们显式调用了构造函数,也没有默认构造,我们没有给缺省值,参数也没有缺省值,调用的时候就会报错。
C++引入了一个概念叫做初始化列表,以冒号开始,逗号分割,括号给值:
Date():_year(2024),_month(4),_day(30)
{} 也就是我们将构造函数写成这样,这样我们不传参也是可以成功的。
可能看起来没什么用?
class Stack
{
public:
Stack(int n):_size(10), _capacity(n), arr(nullptr)
{//……
}
private:int _size;int _capacity;int* arr;
};
class MyQueue
{
public:MyQueue(int n):s1(n),s2(n){_size = n;}
private:Stack s1;Stack s2;int _size;
};
int main()
{MyQueue q1(10);return 0;
}对于类中有自定义类型的,我们原本的想法是给MyQueue一个值,然后初始化,并且stack调用自己的默认构造,如果没有初始化列表,Stack就完不成自己的初始化,那么MyQueue也就完不成自己的默认构造。
初始化列表赋值的时候都是用括号赋值,如果不想用括号,那么进入花括号里面进行赋值也是可以的,一般来说的话能直接括号就直接括号了。
赋值的括号里面可以是变量也可以是加减法一类的,也可以是常量。

有意思的是括号里面还可以进行运算。
初始化的本质可以理解为声明和定义,private那里是声明,初始化列表就是定义,定义的时候我们给缺省值也是没有问题的。
那么,初始化列表有那么几个需要注意的地方。
有三种成员必须要在初始化列表初始化:
第一种是const成员:
int main()
{const int a;a = 10;return 0;
}这种代码就是错误的,因为const定义的变量只有一次初始化的机会,就是定义的时候,定义好了之后就不能改值的,所以const成员变量必须要在初始化列表初始化。
第二种是引用类型:
int main()
{int x = 10;int& xx;xx = x;return 0;
}引用类型和const类型是一样的,不可能说先给一个外号,看谁像就给谁,所以引用类型也是要在初始化列表的时候给值。
第三种类型是没有默认构造的自定义类型的成员:
class Stack
{
public:Stack(int n):_size(n), _capacity(n), arr(nullptr){//……}private:int _size;int _capacity;int* arr;
};
class MyQueue
{
public:MyQueue(int n = 10):s1(n),s2(n){_size = n;}
private:Stack s1;Stack s2;int _size;
};像这种,stack类必须要传参才是初始化的,没有默认构造函数,那么为了让他能顺利初始化,就在初始化列表里面初始化了。
对于初始化列表来说,三类成员必须在初始化列表初始化,其他类型的可以在初始化列表进行初始化,也可以进入函数体内初始化。
看个有意思的:
class Stack
{
public:Stack(int n = 4):_size(n), _capacity(n), arr(nullptr){}
private:int _size;int _capacity;int* arr;
};
class MyQueue
{
public:MyQueue(int n = 10){_size = n;}
private:Stack s1;Stack s2;int _size;
};
int main()
{MyQueue q1;return 0;
}我们给stack默认构造函数,使用MyQueue的初始化列表的时候没有Stack的初始化,那么stack会不会初始化呢?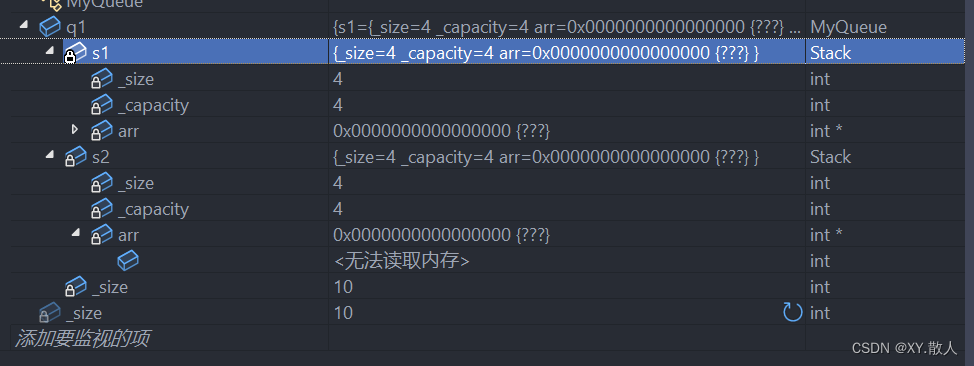
stack类也是初始化了的,那么这就意味着,初始化列表不管你写不写编译器都是要走一遍的,所以C++打的补丁缺省值,实际上给的是初始化列表。即便我初始化列表什么都不写,仍然会走一遍初始化列表。无非就是调用它自己的默认构造函数而已。
一般的顺序都是先走一遍初始化列表,再走函数体,比如初始化一个指针,我们可以这样初始化:
Stack(int n = 4):_size(n), _capacity(n), arr((int*)malloc(sizeof(int) * 10)){memset(arr, 1, 40);}函数体更多的是用来进行其他参数,初始化一般在初始化列表就可以了。
接下来看一个有意思的:
class A
{
public:A(int a):_a1(a),_a2(_a1){}void Print(){cout << _a1 << " " << _a2 << endl;}
private:int _a2;int _a1;
};
int main()
{A a(1);a.Print();return 0;
}问最后结果是什么?
答案可能出乎你的意料: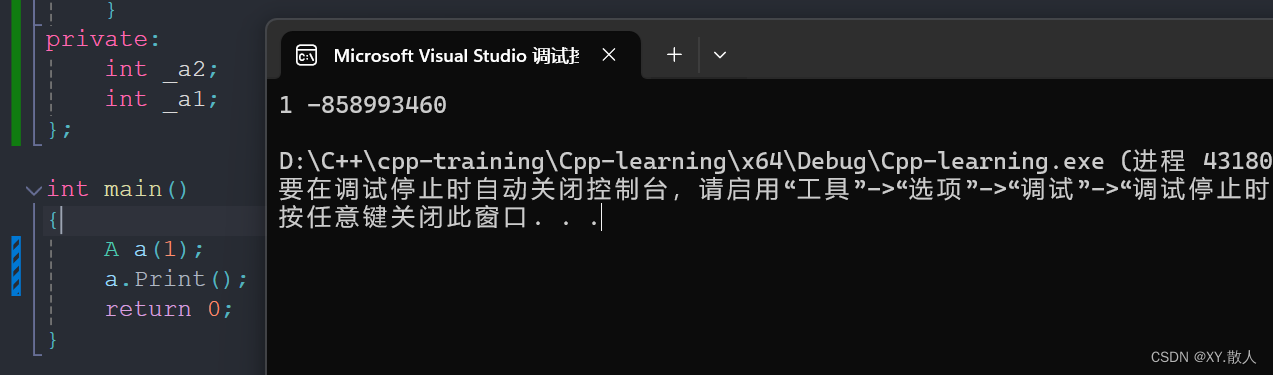
打印出来了一个随机值,这是因为初始化列表的一个特点:
成员变量的声明次序就是初始化列表中的初始化顺序
我们先声明的_a2,所以_a2先给值,是_a1给的,_a1还没开始初始化,所以给的是随机值,然后初始化_a1,这时候_a1初始化为了1,所以打印出来有一个是1,有一个是随机值。
如果我们声明次序换一下,就是Ok的: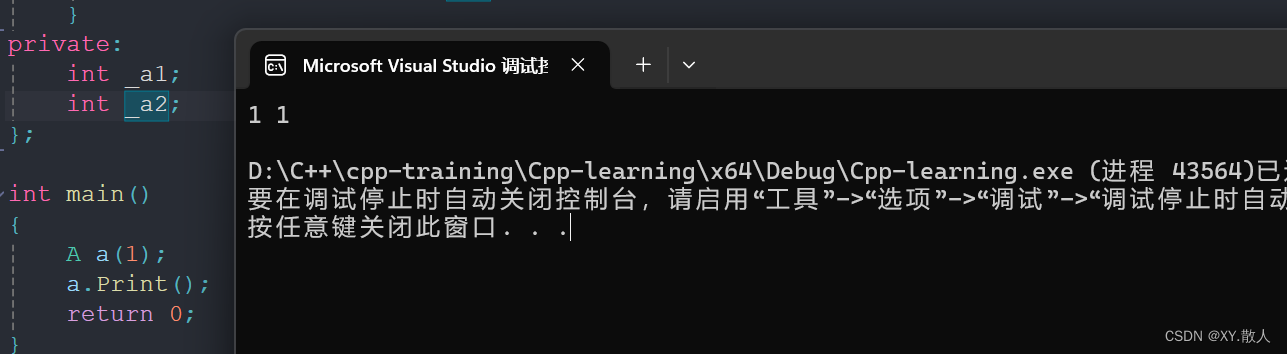
2 类中的隐式类型转换
先来看一个很有用的小代码:
class A
{
public:A(int n):_a(n){}
private:int _a;
};
int main()
{A a1();A a2 = 2;return 0;
}我们创建对象的时候,可以用构造函数创建,也可以利用隐式类型转换创建,内置类型被转换为自定义类型,这里是2构建了一个A的临时对象,然后临时对象拷贝复制给a2。
当然了如果我们要引用一个的话,就得加一个const了,因为const具有常性。
const A& aa = 1;
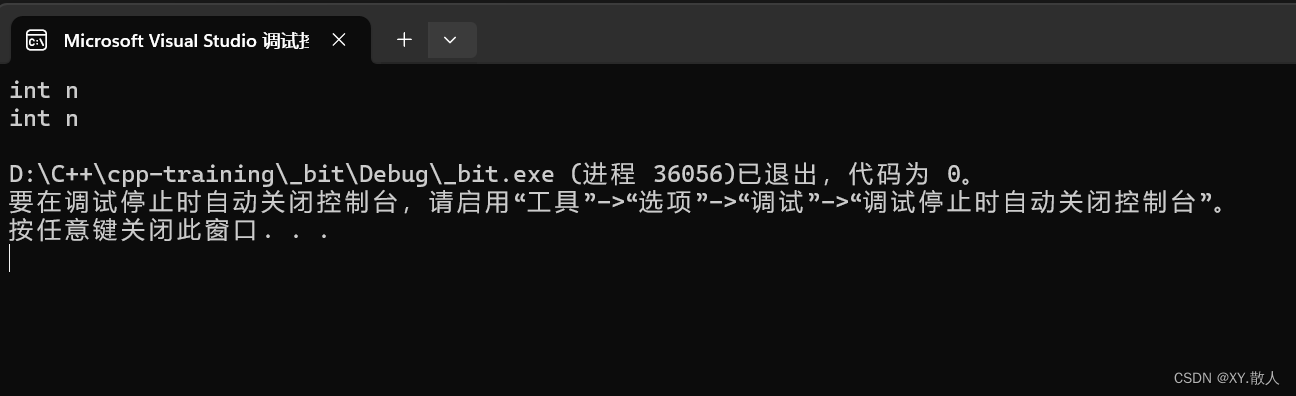
按道理来说,2构造了一个临时对象,发生了一次构造,然后临时对象拷贝构造给a2,所以一共是两次函数调用,但是在编译认为连续的构造 + 拷贝构造不如优化为构造,测试一下:
class A
{
public:A(int n):_a(n){cout << "int n" << endl;}A(const A& aa):_a(aa._a){cout << "const A& aa" << endl;}
private:int _a;
};
int main()
{A a1(1);//构造A a2 = 2;//构造+拷贝构造 = 直接构造return 0;
}
这个隐式类型转换应用的场景比如:
class A
{
public:A(int n = 1):_a(n){cout << "int n" << endl;}A(const A& aa):_a(aa._a){cout << "const A& aa" << endl;}
private:int _a;
};class Stack
{
public:void push(const A& aa){//...}
private:int _size;
};int main()
{A a1;Stack s1;s1.push(a1);s1.push(2);return 0;
}我往栈里面插入一个自定义类型,如果没有隐式类型转换,我就需要先创建一个,再插进去,这多麻烦,有了隐式类型转换直接就插入进去了。
但是有没有发现一个问题就是,隐式类型转换是内置类型给给自定义类型,如果是多个参数,又怎么办呢?
先不急,还有一个关键字explicit,它的用法很简单,就是防止隐式类型转换的发生的:
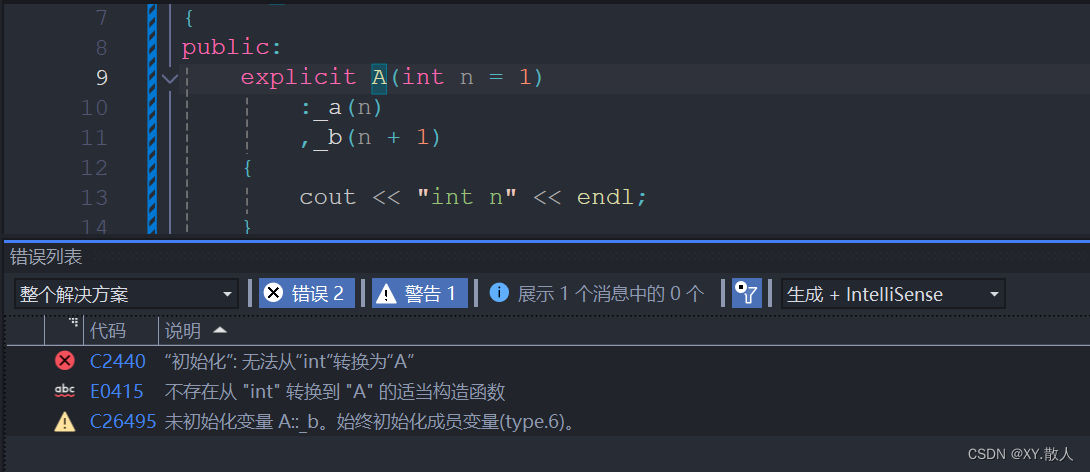
当多参数的时候,万能的花括号就派上用场了:
class A
{
public:A(int n,int m):_a(n),_b(m + 1),_c(n + 2){cout << "int n" << endl;}A(const A& aa):_a(aa._a){cout << "const A& aa" << endl;}
private:int _a;int _b;int _c;
};
int main()
{A a1 = { 1,2};A a2{ 1,3 };const A& aa{ 2,2 };return 0;
}
对于多参数的初始化,用花括号即可,并且在新的标准中可以不用等好,直接就花括号就可以了,
3 Static成员
class A
{
public:A(){_count++;}A(const A& aa){_count++;}~A(){_count--;}
private:int _a;int _b;static int _count;
};都知道static是用来修饰静态成员变量,那么在类里面如上,请问该类的大小是多大呢?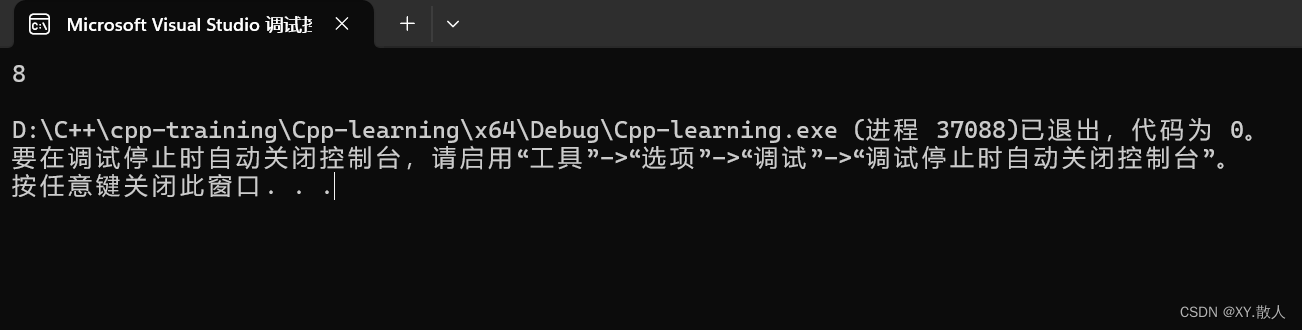
sizeof计算出来是8,也就是说_count是不在类里面的,因为它在静态区里面,那么结合初始化列表的知识,我们能给缺省值吗?
当然是不行的,因为缺省值最后都是要走初始化列表的,static的成员变量都不在类里面,怎么能走呢?
因为static的成员是静态的,我们只能在定义的时候给初始值,我们就只能在全局给一个初始值:
int A::_count = 1;
既然它是静态的,所以我们可以用来计数,比如实时观察有几个对象:
class A
{
public:A(int n = 1):_a(n),_b(n){_count++;}A(const A& aa){_count--;}~A(){_count++;}
//private:int _a;int _b;static int _count;
};int A::_count = 0;A Func()
{A a1;return a1;
}int main()
{A a1;//1A a2 = a1;//2A a3 = 3;//3Func();//4//拷贝构造一个5cout << a1._count << endl;return 0;
}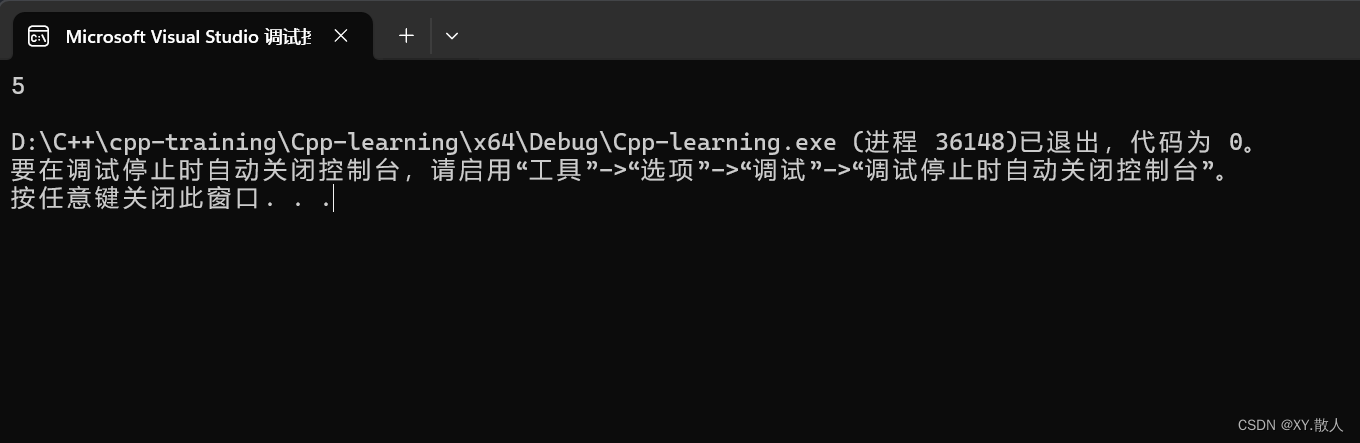
函数里面有一次初始化,一次拷贝,加上主函数的三次,一共就是5个。
但是!
以上的所有操作都是基于count是公有的解决的,但是成员变量一般都是私有的,所以解决方法是用static修饰的函数:
static int Getcount()
{return _count;
}因为函数也是静态的,所以没有this指针,那么访问的只能是静态成员,比如_count,其他成员变量都是不能访问的。
4 友元和内部类
友元前面已经简单提过,这里也介绍一下:
class A
{friend class B;//A是B的友元
public://...
private:int _a1;int _a2;
};
class B
{
public://...
private:int _b1;int _b2;
};A是B的友元,友元的位置声明放在任意位置都是可以的,既然A是B的友元,也就是说A是B的朋友,那么B就可以访问A中的成员,如:
class A
{friend class B;//A是B的友元
public://...
private:int _a1 = 1;int _a2 = 2;
};
class B
{
public://...void BPrint(){cout << a1._a1 << endl;}
private:int _b1;int _b2;A a1;
};
int main()
{B bb;bb.BPrint();return 0;
}但是反过来就不行了,A是B的朋友没错,但是B不是A的朋友,所以A不能使用B的成员,这个世界的情感很多都是单向的~
但是呢友元关系不能继承,之后介绍。
内部类,和友元关系挺大的:
class A
{
public:class B{public:private:int _b1 = 1;int _b2 = 2;};
private:int _a1 = 1;int _a2 = 2;
};B是A的内部类,那么他们天生就有B是A的友元的关系,所以A可以直接访问B的成员变量,但是sizeof(外部类)的结果就是外部类:
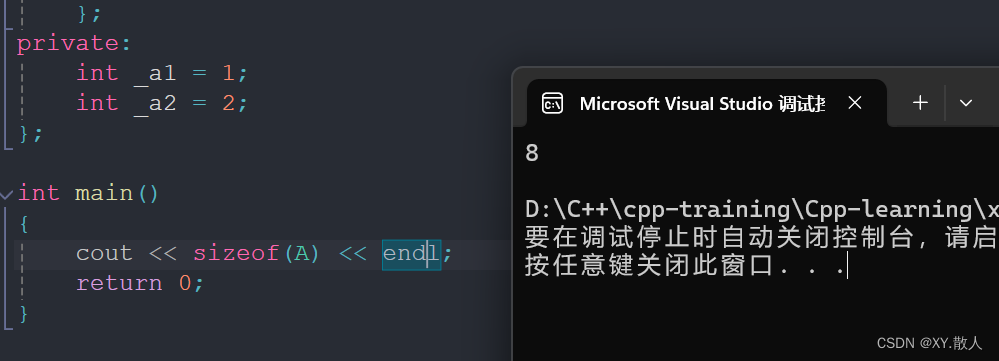
内部类还可以直接访问外部类的static变量,不需要类名等:
class A
{
public:class B{public:void PirntK(){cout << _k << endl;}private:};
private:static int _k;
};
int A::_k = 1;
int main()
{A::B b1;b1.PirntK();return 0;
}5 匿名对象
不少人看到匿名对象可能会联想到匿名结构体,不同的是匿名对象是对象实例化的时候不给名字,如:
class A
{
public:A(int num = 1):_a(num){cout << "int A" << endl;}~A(){_a = -1;cout << "~A" << endl;}
private:int _a;
};
int main()
{A a1;//有名对象A(1);//匿名对象return 0;
}与匿名结构体不同的是,匿名i对象的声明周期只在这一行,没错,就是只有一行,我们可以通过析构函数调用实验一下:
int main()
{A(1);cout << "666" << endl;return 0;
}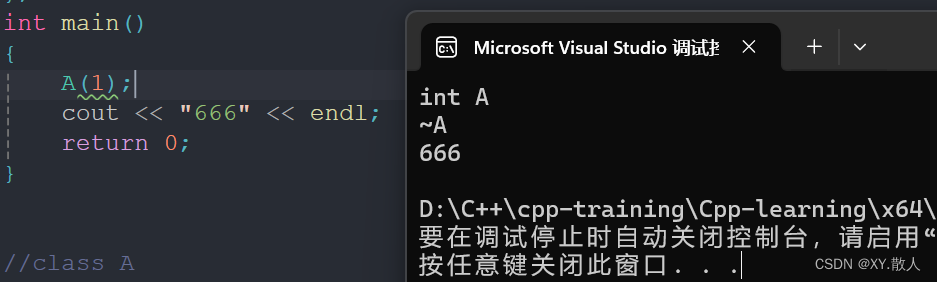
如果是有名对象,那么析构函数的调用会在主函数结束的时候调用,那么666的打印就会在~A之前打印,但是这是匿名对象,创建即是销毁。
那么有用没呢?
存在即合理,比如我们调用函数:
class S
{
public:void P(){cout << " aaa " << endl;}
private:};
int main()
{S s1;s1.P();S().P();return 0;
}这是两种调用方法,两行代码的是有名对象的调用,一行代码的是匿名对象的调用,所以嘛,存在即合理。
6 编译器的一些优化
编译器的一些优化在2022是不太好观察的,因为2022的优化是比较大的,这里推荐的是Vs2019或者使用Linux机器观察,这里使用Vs2019观察:
先来看一下传值传参热热身:
class A
{
public:A(int num = 1):_a(num){cout << "int A" << endl;}A(const A& aa){cout << "const A& aa" << endl;}~A(){cout << "~A" << endl;}
private:int _a;
};
//测试代码
void Func(A aa)
{}
int main()
{A a;Func(a);cout << endl;return 0;
}顺序是a的构造->aa的拷贝构造->aa的析构(因为出了函数的作用域)->a的析构:
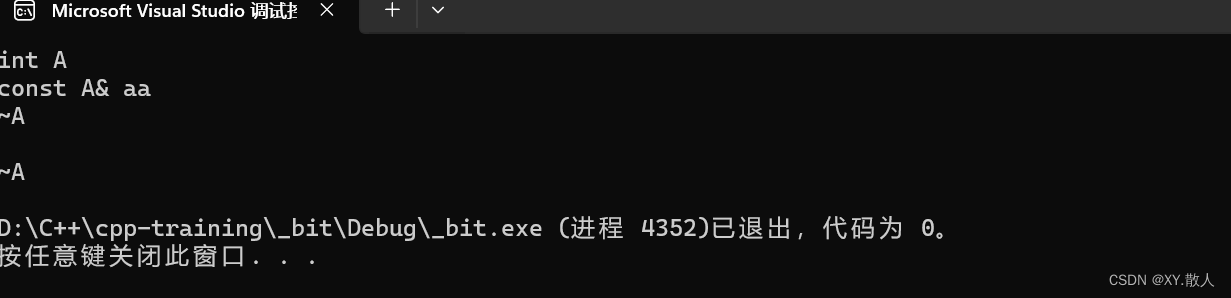
打印出来的换行也可以说明。
这里可能有人要问了,为什么拷贝构造函数要用个const修饰,因为有了匿名对象,呼应上了这就:
匿名对象发生的是临时变量的拷贝,具有常性,所以我们应该用const进行修饰
Func(A(1));
1 连续的构造 + 拷贝构造 = 直接构造(不绝对)
如下三个场景:
int main()
{Func(2);Func(A(2));A aa = 3;return 0;
}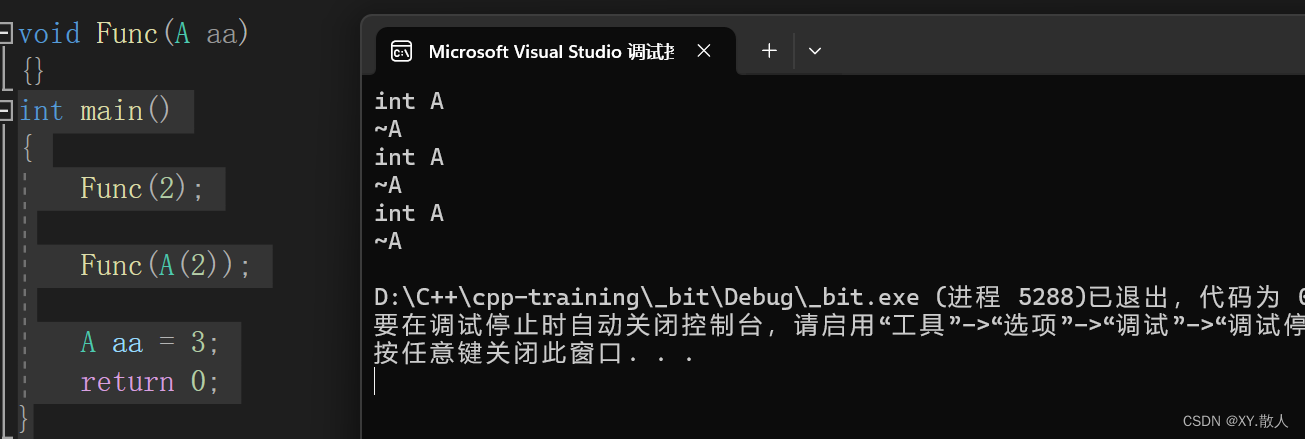
比如最后一个,给一个3,那么3会构造一个临时对象,临时变量拷贝给aa,整个过程就是连续的构造 + 拷贝构造,编译器会直接优化为构造。
但是为什么说不绝对呢?这和内联函数都是一样的,取决于编译器的实现,优化,内联函数对编译器来说都只是个建议,具体看的是编译器。
2 连续的拷贝构造 + 拷贝构造 = 一个拷贝构造
A Func()
{A aa;return aa;
}
int main()
{A ret = Func();return 0;
}代码执行的顺序是aa的构造 -> aa返回临时变量进行拷贝 -> ret拷贝构造一个临时对象
这里是连续的拷贝构造即被编译器优化为一个拷贝构造:
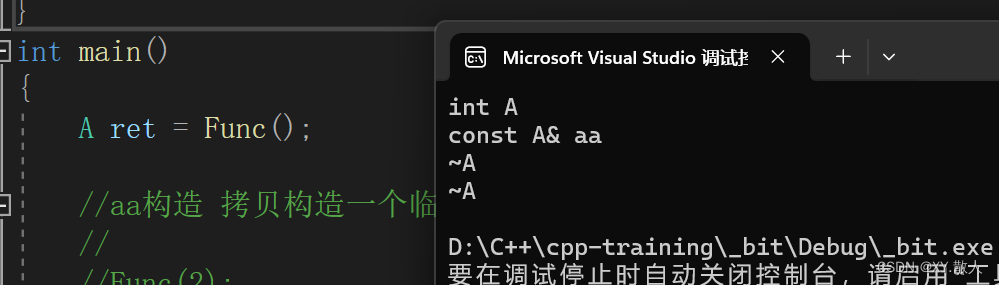
但是……
int main()
{A ret;ret= Func();return 0;
}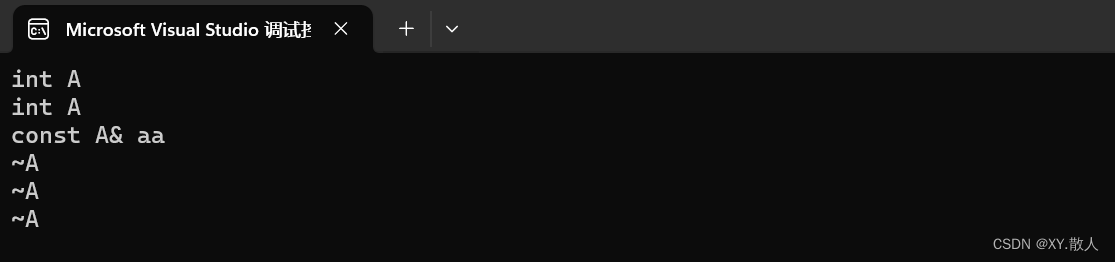
这里是连续的拷贝构造吗?
并不是,ret = Fun()这里是一个赋值重载,所以就不会有编译器的优化。
即拷贝 + 赋值重载 = 无法优化。
这是debug版本下的优化,release版本下的优化简直可以吓死人:
void operator=(const A& aa)
{cout << "operator=" << endl;
}
A Func()
{A aa;return aa;
}
int main()
{A ret;ret= Func();return 0;
}原来是构造 + 构造 + 拷贝 + 赋值重载,这直接:
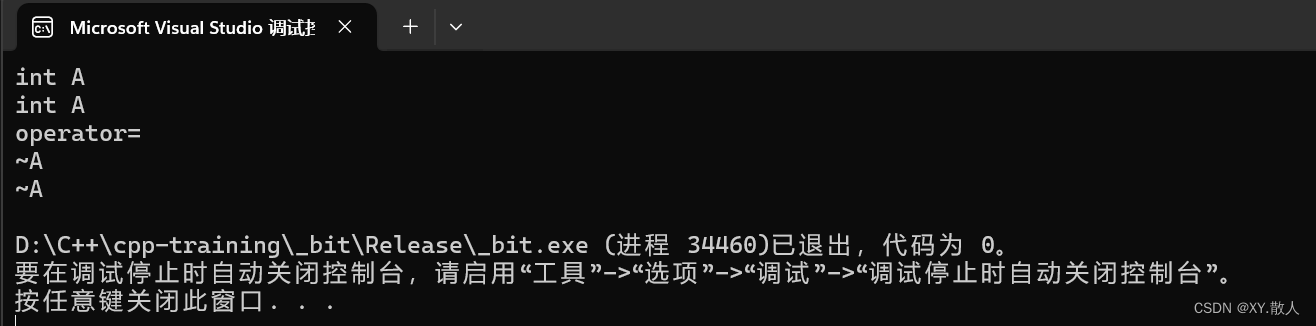
拷贝直接优化掉了,直接赋值重载,这还不是最吓人的。
A Func()
{A aa;return aa;
}
int main()
{A ret= Func();return 0;
}按道理来说,有构造 + 拷贝 + 拷贝,编译器直接三合一:
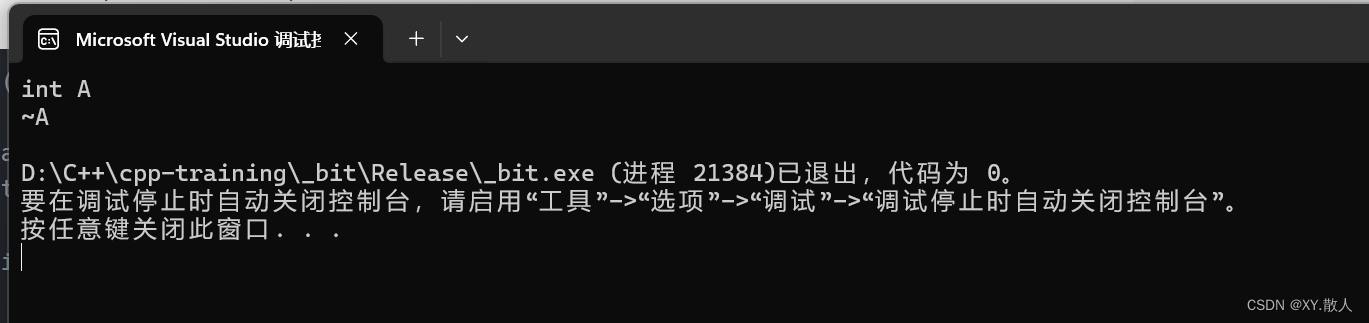
厉害吧?所以有时候观察麻烦就是因为编译器给优化掉了。
以上就是类和对象下的内容。
感谢阅读!