实验目的:
学会使用Pandas操作数据集,并进行可视化。
数据集描述:
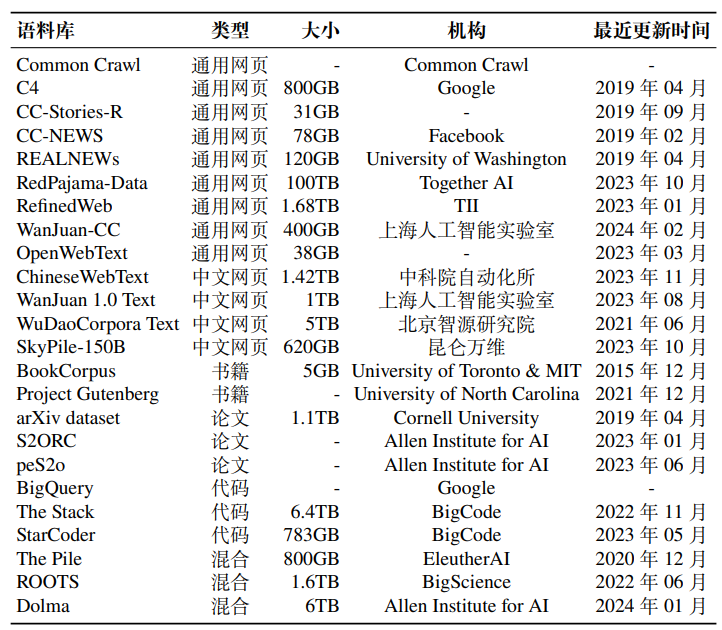
该数据集是CNKI中与“中药毒理反应”相关的文献信息,包含文章题目、作者、来源(出版社)、摘要、发表时间等信息。
实验要求:
- 使用Pandas读取数据集。
- 统计每年的发文数量,并绘制折线图。
- 统计出版社的发文量信息,列出发文前10位的出版社。
- 使用jieba分词,对摘要进行分词统计,制作词频前30位的词云图。(需安装jieba分词和词云工具包)。
实验过程:
为了完成这个实验,你需要在你的Python环境中安装Pandas, jieba, matplotlib, 和 wordcloud这几个库。如果你还没有安装,可以通过以下命令进行安装:
python">pip install pandas jieba matplotlib wordcloud
导入库,导入文件(文件名称为 ansi.csv),打印几行看看导入情况
python">import pandas as pd
df = pd.read_csv('./ansi.csv')
df.head()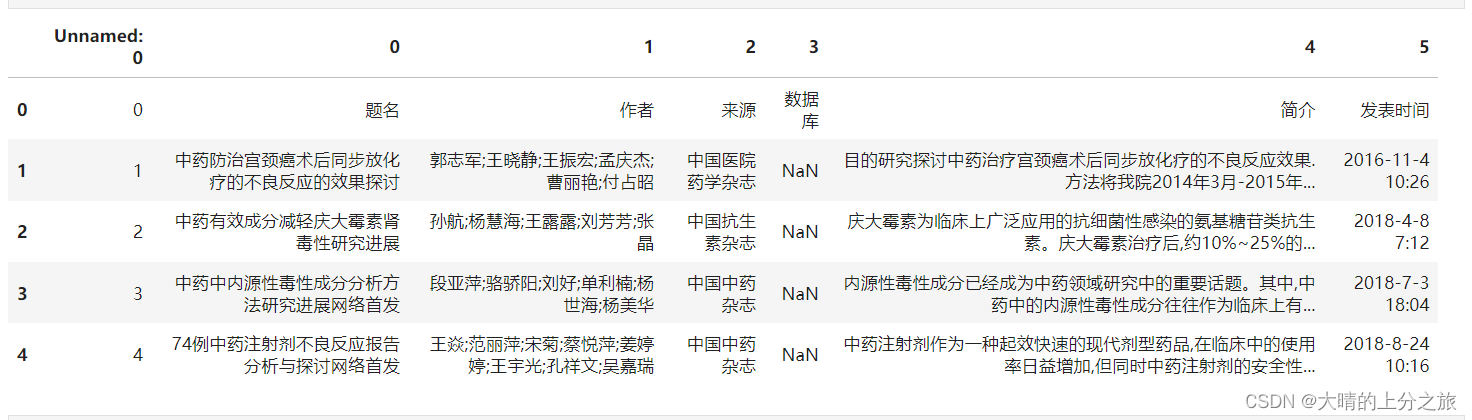
通过输出查看文件的表头是什么
python">print(df.columns)![]()
统计每年的发文数量,并绘制折线图
python">import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
df['年'] = pd.to_datetime(df['5'], format='%Y-%m-%d %H:%M', errors='coerce').dt.year
year = df['年'].value_counts().sort_index()
plt.figure(figsize=(10, 6))
plt.plot(year.index, year.values, marker='o')
plt.title('每年中药毒理反应文献发表数量')
plt.xlabel('年份')
plt.ylabel('发表数量')
plt.grid(True)
plt.show()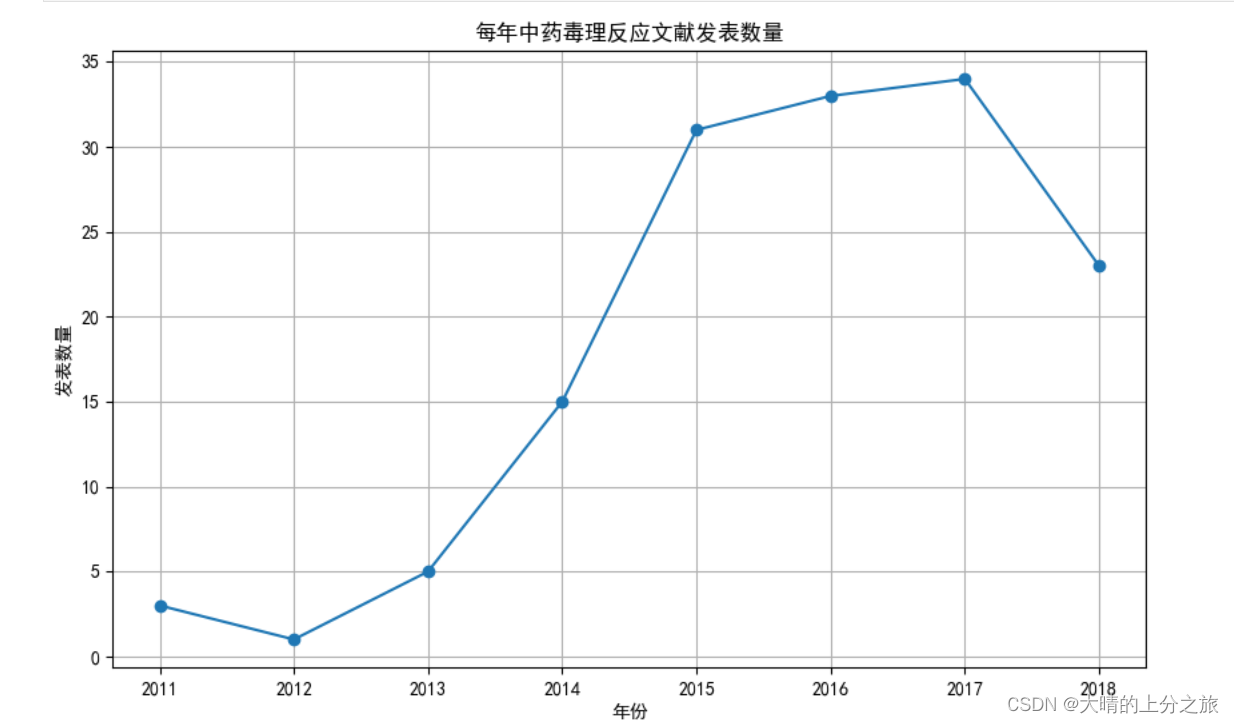
统计出版社的发文量信息,列出发文前10位的出版社
python">publisher = df['2'].value_counts()
top = publisher.head(10)
print("发文前10位的出版社:")
print(top)
使用jieba分词,对摘要进行分词统计,制作词频前30位的词云图
python">import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as pltdef tokenize_abstracts(abstracts):all_words = []for abstract in abstracts:words = jieba.cut(abstract, cut_all=False)all_words.extend(words)return all_wordsabstracts = df['4'].dropna().tolist()# 分词
all_words = tokenize_abstracts(abstracts)# 计算词频
word_freq = {word: all_words.count(word) for word in set(all_words)}# 制作词云
wordcloud = WordCloud(font_path='simhei.ttf',width=800, height=600, background_color='white', max_words=30).generate_from_frequencies(word_freq)# 显示词云图
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()