# 第六章 函数# 在Python语言中,定义函数的语法格式如下:
# def 函数名([参数列表]):
# 函数体# [注意]
# (1)圆括号内是形参列表,如果有多个参数则使用逗号分隔开,
# 即使该函数
# 不需要接收任何参数,也必须保留一对空的圆括号。
# (2)圆括号后的“:”必不可少。
# (3)函数体相对于def关键字必须保持一定的空格缩进。
# (4)函数体中可以使用return语句返回值。return语可以有多条,在这种情况下,一
# 旦第一条return语句得到执行,函数立即终止。return语可以出现在函数体的任何位置# 在Python 语言中,调用函数的语法格式如下:
# 函数名([实参列表])# 例如
# def max(a,b):
# if a >= b: return a
# else : return b# # 例6-1 编写程序,求任意个联系整数的和
# def calSum(n1,n2):
#
# sm = 0
#
# for i in range(n1,n2+1):
# sm = sm + i
# return sm
#
# n1,n2 = eval(input('请输入两个数:'))
#
# print(calSum(n1, n2))
#
# # 请输入两个数:1,10
# # 55# # 求(2+3+...+19+20)+(11+12+...+99+100)的和# print('(2+3+...+19+20)+(11+12+...+99+100)的和为:',calSum(2,20) + calSum(11,100))
# # (2+3+...+19+20)+(11+12+...+99+100)的和为: 5204# 例6-2
# (1)找出 2~100 中所有的素数。# 我自己写的是直接求一个范围内的所有素数的函数
# 更通用是写一个判断是否是是素数的函数,剩下的可以在函数外面写
# def primes(n1,n2):
#
# # c = 0
# for i in range(n1,n2+1):
# for j in range(2,i):
# if i % j == 0:
# break
# else:
# # c += 1
# print(i,end=' ')
# # if c % 10 == 0: # 设置为每十个换行
# # print()
#
# a1,a2 = eval(input('请输入一段范围,求这段范围内的所有素数:'))
# print(primes(a1,a2))
# 请输入一段范围,求这段范围内的所有素数:2,100
# 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 None# 书上例题写的# def primes(n):
#
# for i in range(2,n):
# if n % i == 0:
# return False
# else:
# return True# for i in range(2,100):
# if primes(i) == True:
# print(i,end=' ')# 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97# (2)找出 2~100 中所有的孪生素数。孪生素数是指相差 2 的素数对,如3和5、5和7、11和13 等。# 思路
# 遍历,可以先找到一个素数,然后判断+2后的数是不是素数,如果是就输出# for i in range(2,100):
# if primes(i) and primes(i+2) :
# print(i,i+2)# 3 5
# 5 7
# 11 13
# 17 19
# 29 31
# 41 43
# 59 61
# 71 73# (3)将4~20中所有的偶数分解成两个素数的和。例如,6=3+3、8=3+5、10=3+7 等。# 思路
# 遍历偶数,先找到第一个素数,然后用这个 偶数 减去 这个素数,再判断是不是素数# for i in range(4,20+1,2):
# for j in range(2,i):
# if primes(j) and primes(i-j):
# print(i,'=',j,'+', i-j)
# break# 4 = 2 + 2
# 6 = 3 + 3
# 8 = 3 + 5
# 10 = 3 + 7
# 12 = 5 + 7
# 14 = 3 + 11
# 16 = 3 + 13
# 18 = 5 + 13
# 20 = 3 + 17# 函数的参数# 默认值参数# 1. 默认值参数
# 在声明函数时,如果希望两数的一些参数是可选的,则可以在声明函数时为这些参数指定默认值
# 调用该函数时,如果没有传入对应的实参值,则函数使用声明时指定的默认参数值
# 例如:# def babble (words, times = 1): # 函数babble的第二个参数指定了默认值
# print ( (words+" ")*times) # 每个字符之间有空格
#
# # 对babble函数进行调用
# babble ('hello',3) # 调用babble()函数,传“hel1o”给words,3给times
#
# # hello hello hello
#
# babble ('Tiger') # 调用 babble()函数,“Tiger” 给words, times 使用默认值 1
#
# # Tiger
#
#
# # 这里需要注意的是,默认值参数必须写 在形参列表的右边,这是因为函数调用时,默认是按位置传递实际参数值的
# # 例如:
#
# # 这是错误的
#
# def babble (words = "abc", times): # 默认值参数位置不正确
# print ((words+" ") * times)
# # SyntaxError: non-default argument follows default argument
#
#
# # 修改后的
#
# def babble (words = 'abc', times = 2 ): # 默认值参数位置不正确
# print ((words+" ") * times)
# babble()
#
# # abc abc
#
#
# def babble ( times , words = 'abc' ): # 默认值参数位置不正确
# print ((words+" ") * times)
# babble(5)
#
# # abc abc abc abc abc# 例6-3
# 基于期中成绩和期末成绩,按指定的权重计算总评成绩# def score(mid,end,rate = 0.4):
# sum = mid * rate + end * (1-rate)
# return sum
#
# a,b,c = eval(input("请输入期中期末成绩和权重:"))
#
# print('最后总评成绩:',score(a,b,c))# 请输入期中期末成绩和权重:95,98,0.5
# 最后总评成绩: 96.5# print('最后总评成绩:',score(92,100))# 最后总评成绩: 96.80000000000001# 名称传递参数
# 与顺序无关# 例6-4
# print(score(end = 99,mid = 90,rate = 0.2)) # 97.2
# print(score(end = 99,mid = 90)) # 95.4# print()函数
# print(values,sep, end, file, flush)# sep string inserted between values, default a space.
# 在值之间插入字符串,默认为空格# end string appended after the last value, default a newline
# 附加在最后一个值之后的字符串,默认为换行符# file a file-like object (stream); defaults to the current sys.stdout.
# 类似文件的对象(流);默认为当前 sys.stdout# flush whether to forcibly flush the stream.
# 是否强行冲洗流# 例6-5# print(1,2,3,sep='-') # 用‘-’分隔多项输出
# # 1-2-3# print(23,35,1,sep='/') # 用‘/’分隔多项输出
# # 23/35/1# for i in range(1,4):
# print(i,end='') # 输出后不换行
# # 123# 可变参数# 在定义函数的时候,使用带星号的参数,如*param1,则意味着允许向函数传递可变数量的参数
# 调用函数时,从该参数之后所有的参数都被收集为一个元组
# * 元组# 例6-6 利用可变参数输出名单,并统计人数def pepole(*c):for i in c:print(i,' ',end='')len(c)return len(c)print(pepole('李白','杜甫'))
print(pepole('李白','杜甫','苏轼','柳宗元','李商隐','王维','白居易','欧阳修','龚自珍'))# 李白 杜甫 2
# 李白 杜甫 苏轼 柳宗元 李商隐 王维 白居易 欧阳修 龚自珍 9# 在定义函数的时候,使用带两个星号的参数,如**param2,则可以允许向函数传递可变数量的参数
# 调用函数时,从该参数之后所有的参数都被收集为一个字典
# ** 字典# def p (**d):
# print(d)
# total = 0
# for k in d:
# total = total + d[k]
# return total
#
# print(p(g1 = 5,g2 = 20,g3 = 14,g4 = 22))# 需要说明的是 **d 收集为一个字典 键 :值
# 可变参数的形式为 a = cc ,这种类似的,a表示 键,cc表示 值# {'g1': 5, 'g2': 20, 'g3': 14, 'g4': 22}
# 61# 例6-8 累计单账户利息# def addInterest(money,rate):
#
# money = money * (1+rate)
#
# return money
#
# money = 1000
# rate = 0.05
# a = addInterest(money,rate)# 或者
# a = addInterest(money = 1000,rate= 0.05)# 或者
# a = addInterest(1000,0.05)# a = addInterest(money,rate)# print(a) # 1050.0# 例6-9 累计多账户利息def addInterest(money,rate):for i in range(len(money)):money[i] = money[i] * (1 + rate)return moneymoney = [1200,1400,800,650,1600]
rate = 0.05a = addInterest(money,rate)print(a)
# [1260.0, 1470.0, 840.0, 682.5, 1680.0]# 返回多个值# 例6-10 编写一个函数,返回两个整数本身,以及他们的商和余数# def fun(a,b):
#
# return (a,b, a // b, a % b)
#
# m,n,p,q = fun(6,4) # 返回的是4个数,那么就要有4个房子接住它们
#
# print(m,'和',n,'的商',p)
# print(m,'和',n,'的余数',q)# 6 和 4 的商 1
# 6 和 4 的余数 2# lambda()函数# lambda0函数是一种简便的,在同一行定义函数的方法# lambda0实际上是生成了一个函数对象,即匿名函数
# 它广泛用于需要 函数对象 作为 (参数) 或 (函数比较简单 并且 只使用一次)的场合# lambda0函数的定义语法格式如下:
# lambda 参数1,参数 2,.....: <函数语句># 其中函数语句的结果为函数的返回值,且只能是一条语句
# 例如:
# 语句 lambda x,y:x*y
# 将生成一个函数对象,函数的形参为x和y,函数的返回值为x与y的乘积# 例6-11 利用lambda()函数输出列表中所有的负数ls = [3,5,-7,4,-1,0,-9]for i in filter(lambda y: y < 0, ls):print(i)# -7
# -1
# -9# filter()函数
# 这里的filter函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表
# filter()函数接收两个参数,第一个为函数,第二个为序列
# 序列的每个元素作为参数传递给函数进行判断,然后返回 True False
# 最后将返回 True 的元素存放到新列表中# 找出正整数小于等于100 同时能被3整除 且 个位上是5 的数for i in filter(lambda x: x % 3 ==0 and x % 10 == 5,range(1,100+1)):print(i)# 15
# 45
# 75# 例6-12 利用lambda()函数对字典元素按值或按键排序dictD = {'化1704':33,'化1702':28,'化1701':34,'化1703':30}# print(dictD.items())
# dict_items([('化1704', 33), ('化1702', 28), ('化1701', 34), ('化1703', 30)])
# 可以看出以条目形式提取的字典,每个条目以元组()括号的形式
# 所以x代表每个元组,x[0]为'化170X',x[1]为 数字print(sorted(dictD))
# ['化1701', '化1702', '化1703', '化1704']
# 按 键 排序,输出键print(sorted(dictD.items()))
# [('化1701', 34), ('化1702', 28), ('化1703', 30), ('化1704', 33)]
# 按 键 排序,输出键值对print(sorted(dictD.items(),key= lambda x:x[1]))
# [('化1702', 28), ('化1703', 30), ('化1704', 33), ('化1701', 34)]
# 按 值 排序,输出键值对print(sorted(dictD.items(),key= lambda x:x[1] % 10))
# [('化1703', 30), ('化1704', 33), ('化1701', 34), ('化1702', 28)]
# 按 值的个位 排序,输出键值对# 有列表“list=[-2,7,-3,2,9,-1,0,4],按照列表中每个元素的平方值排排序list=[-2,7,-3,2,9,-1,0,4]print(sorted(list,key=lambda x: x**2))
# [0, -1, -2, 2, -3, 4, 7, 9]# 有列表list =['their','are','this','they','is'],按照列表中每个元素的长度值排序list =['their','are','this','they','is']print(sorted(list,key=lambda x: len(x)))
# ['is', 'are', 'this', 'they', 'their']# 变量的作用域# 如果遇到一定要在函数f()中访问全局变量 的情况,只要使用关键字 global 声明将使用全局变量即可
def f():global x # 访问全局变量x,x = 10x=5 # 这一行将全局变量x重新赋值为 5,所以现在的全局变量改为了5print("f内部:x=",x)return x*xx=10 # 全局变量print("f()=",f())
print("f外部:x=",x)# f内部:X= 5
# f()= 25
# f外部:x= 5# 递归函数# 一个函数调用它自己就称为递归# 例6-13 递归方法求1-9的阶乘def fact(i):if i == 1: return 1else: return i * fact(i-1)for i in range(1,9+1):print('{}! = {}'.format(i,fact(i)))# 1! = 1
# 2! = 2
# 3! = 6
# 4! = 24
# 5! = 120
# 6! = 720
# 7! = 5040
# 8! = 40320
# 9! = 362880# 例6-13 递归法求1-20的斐波那契数列def fibo(i):if i == 1 or i == 2: return 1else: return fibo(i-1) + fibo(i-2)for i in range(1,20+1):print('{:<8}'.format(fibo(i)),end='' if i % 5 != 0 else '\n')# 1 1 2 3 5
# 8 13 21 34 55
# 89 144 233 377 610
# 987 1597 2584 4181 6765# 例6-15 递归方法求最大公约数# 用于计算最大公约数的递归算法称为欧几里得算法
# 其计算原理依赖于定理:
# 两个整数的最大公约数等于其中较小的那个数和两数相除余数的最大公约数
# 公式为:gcd(a,b) = gcd(b,a mod b)
# 分析公式可知:终止条件为“ged(a,b)=a,当b=0时”;递归步骤为“gcd(b,a%b)”
# 每次递归a%b严格递减,故逐渐收于0def gcd(a,b):if b == 0: return aelse: return gcd(b,a % b)print('gcd(12,24) = ',gcd(12,24))
print('gcd(48,24) = ',gcd(48,24))
print('gcd(15,11) = ',gcd(15,11))
print('gcd(15,35) = ',gcd(15,35))# gcd(12,24) = 12
# gcd(48,24) = 24
# gcd(15,11) = 1
# gcd(15,35) = 5Python.第六章(函数)
embedded/2024/10/11 7:30:08/
相关文章

阿里云详细介绍,与AWS和GCP比较
一、阿里云详解
阿里云(Alibaba Cloud),也被称为阿里巴巴云计算,是中国最大的云服务提供商,同时在全球范围内也具有显著的市场影响力。自2009年成立以来,阿里云已经发展成为一个提供全方位服务的云平台&am…
使用ganache实现Web3js和区块链交互的步骤 及问题解决:Command ‘express’ not found等
Web3js和区块链交互
做一个简单的dapp
1.express安装
sudo npm install express -g
出现问题:Command ‘express’ not found,
解决:在安装express时增加generator参数:
npm install -g express-generator
成功后使用 express -e MyDa…
DS高阶:图论基础知识
一、图的基本概念及相关名词解释
1.1 图的基本概念 图是比线性表和树更为复杂且抽象的结,和以往所学结构不同的是图是一种表示型的结构,也就是说他更关注的是元素与元素之间的关系。下面进入正题。 图是由顶点集合及顶点间的关系组成的一种数据结构&…
react中useReducer如何使用
useReducer 是 React 提供的一个用于状态管理的 Hook,它接收一个 reducer 函数和初始状态作为参数,并返回当前状态以及一个 dispatch 函数。这个 Hook 适用于管理复杂或嵌套的状态对象,它提供了一种更加结构化的更新状态的方法。 useReducer是…
centos按照mysql
mysql 下载 步骤: Select Operating System: Linux - Generic 下载Linux - Generic (glibc 2.12) (x86, 64-bit), Compressed TAR Archive 5.7.38 643.6M 下载地址: https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.38-linux-glibc2.12-x86_64.ta…

基于Spring Boot的校园博客系统设计与实现
基于Spring Boot的校园博客系统设计与实现
开发语言:Java框架:springbootJDK版本:JDK1.8数据库工具:Navicat11开发软件:eclipse/myeclipse/idea
系统部分展示
系统功能界面图,在系统首页可以查看首页、文…
OpenStack云计算(十四)——综合演练手动部署OpenStack,
本项目的项目实训可以完全参考教材配套讲解的详细步骤实施,总体来说实训工作量较大,可根据需要选做,重点观看配套的微课视频。
项目实训一
【实训题目】
搭建OpenStack云平台基础环境
【实训目的】
掌握OpenStack基础环境的安装和配置方…
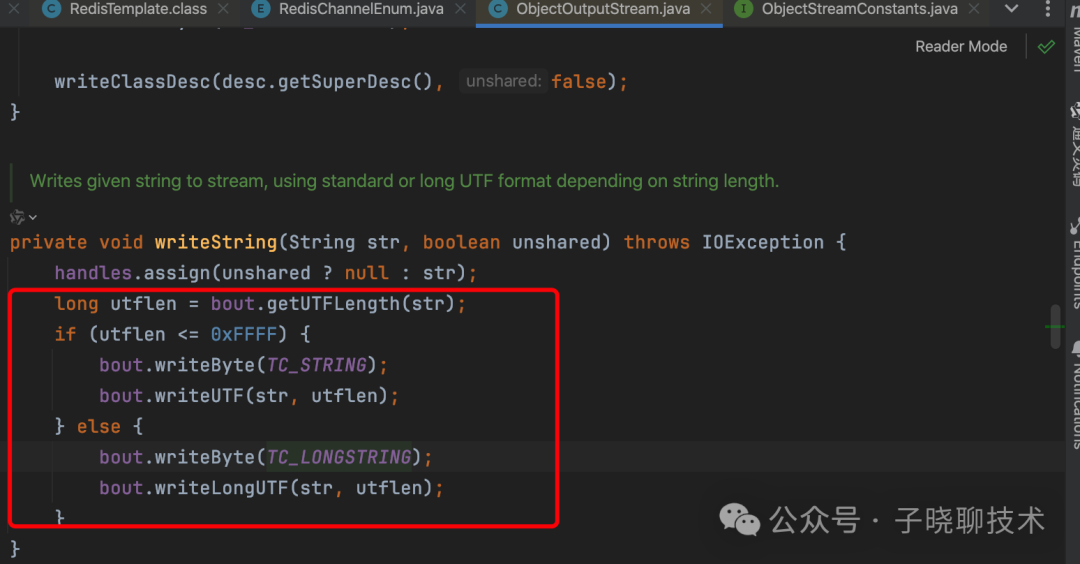
【问题排查】Springboot集成RedisTemplate发布Redis数据带有前缀乱码问题排查解决
先说下项目背景:
五一前冲刺新项目,项目springboot2 , 集成stomp协议 和前端进行websocket通信。 之前写过一篇文章关于stomp协议的文章,有兴趣可以看看 【JAVA技术】springboot集成stomp协议实现 用户在线离线 。
测试同学反…