一、Bert整体模型架构
基础架构是transformer的encoder部分,bert使用多个encoder堆叠在一起。
主要分为三个部分:1、输入部分 2、注意力机制 3、前馈神经网络

bertbase使用12层encoder堆叠在一起,6个encoder堆叠在一起组成编码端,6个decoder堆叠在一起组成解码端。
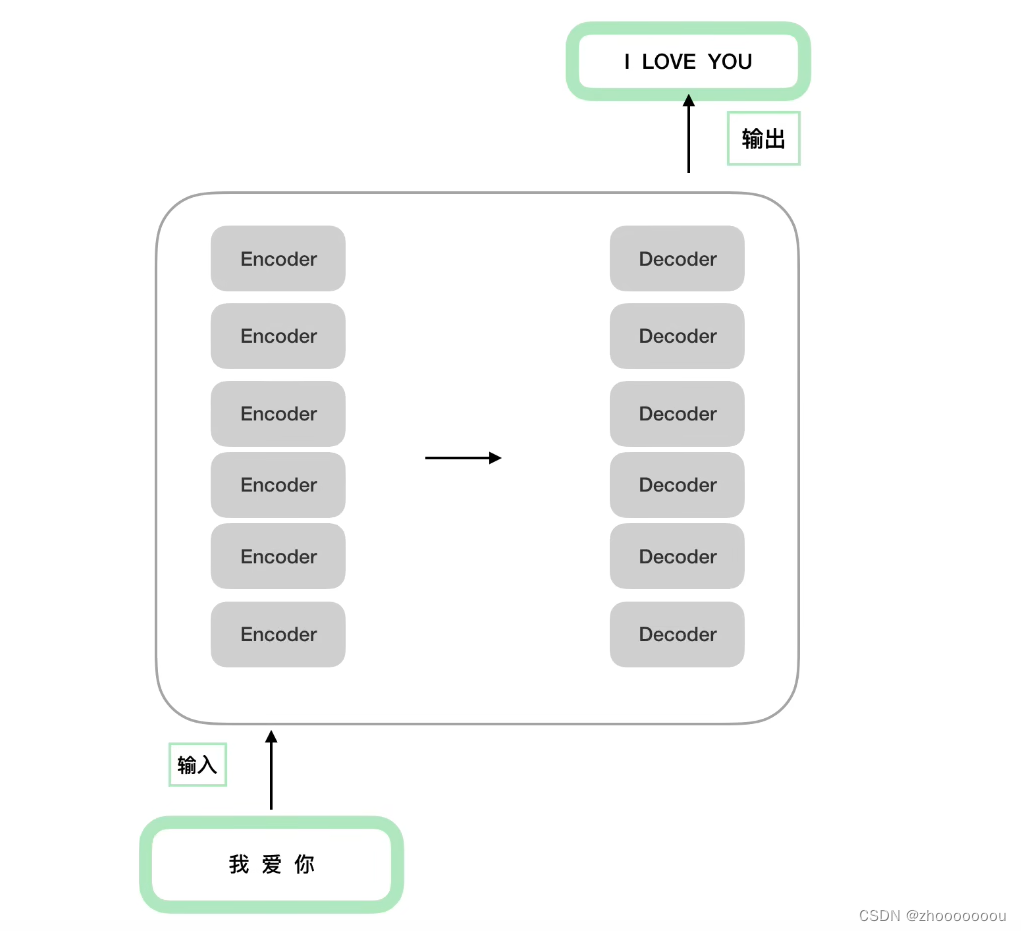
对于Bert的encoder部分重点关注输入部分
对于transformer来说,输入包括两部分:
1、input embedding:做词的词向量,比如做词的初始化
2、positional encoding:位置编码,使用的是三角函数正余弦函数去代表他。
在Bert中分为了三个部分:
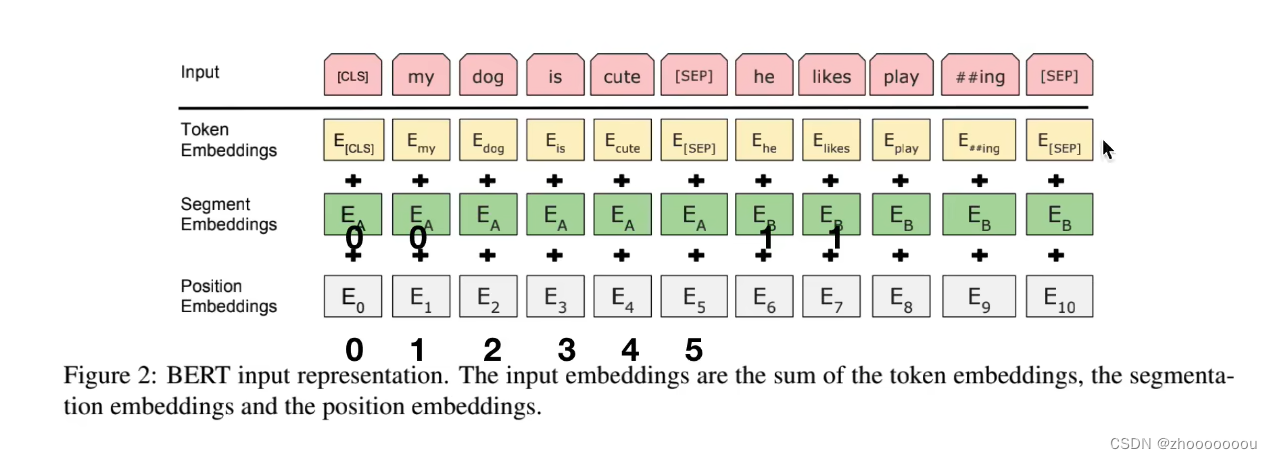
input = token emb + segment emb + position emb

二、Bert的输入部分
1、input
正常词汇: my dog is cute he likes play ## ing
特殊词汇:CLS SEP
这两个存在是因为在Bert预训练时有NSP(Next Sentence Prediction)任务存在,这个任务是用于处理两个句子之间的关系

SEP主要是做句子间隔:之前的是一个句子,SEP之后的是另一个句子。
CLS 的输出向量接一个二分类器,去做一个二分类任务(误区:CLS向量输出不能代表整个句子的语义信息)
2、输入的内容
token embeddings
对input中的所有词汇,包括正常词汇和特殊词汇,都去做正常的embedding比如随机初始化
segment embeddings
由于处理的是两个句子,所以需要对两个句子进行区分,第一个句子使用0来表示,第二个句子使用1来表示;并使用不同的符号来表示。
position embeddings
Bert的输入部分与transformer输入部分很大的不同点:
transformer中使用正余弦函数
Bert使用随机初始化,然后让模型自己去学习出来,整个512的长度,让模型自己去学习出来每个位置应该是什么样子的
三、预训练:MLM+NSP
MLM(Masked Language Modeling)是指掩码语言模型。这是一种预训练语言模型的方法,旨在通过预测被掩码(或称为遮盖、掩盖)的单词来学习语言的上下文表示。
NSP(Next Sentence Prediction)是一个特定的预训练任务,旨在预测两个句子在原始文本中是否连续出现。
BERT 在预训练的时候使用的是大量的无标注的语料,所以在设计的时候,一定会考虑无监督来做。
无监督目标函数
AR: auto regressive,自回归模型:只能考虑单侧的信息,典型的就是GPT
AE:auto encoding,自编码模型:从损坏的输入数据中预测重建原始数据。可以使用上下文信息。
MLM模型
1、基本原理
打破了文本,让他文本重建。模型在周围的文本中学习各种信息,来让预测出来的文本无限接近原本的词汇。就像是让模型根据上下文去做完形填空
2、缺点
mask 和mask之间是独立的,但是在实际中不一定是独立的,而是有关系的。
3、模型概率
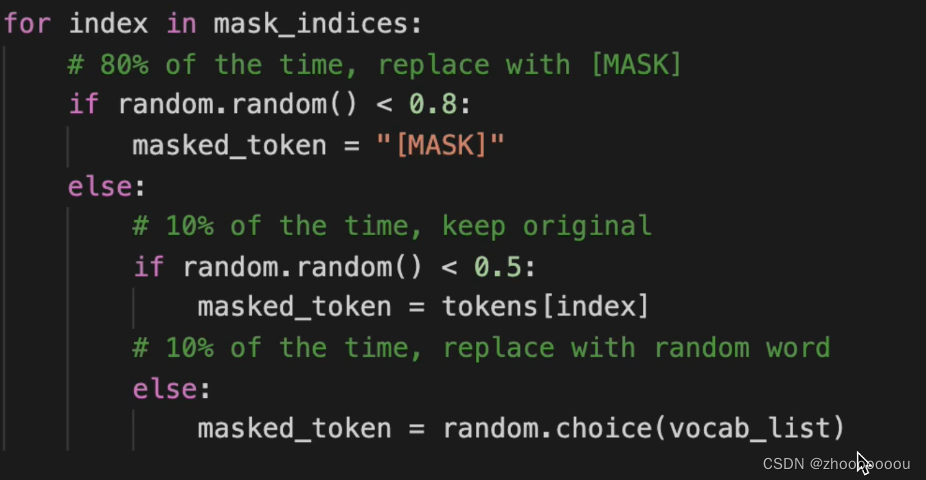
随机 mask 15% 的单词 ==》 10%替换成其他 10%原封不动 80%替换成马赛克
模型代码
NSP任务
最重要的一个点是理解样本的构造模式。
NSP样本如下:
1、从训练语料库中取出两个连续的段落作为正样本。两个连续的段落来自同一个文档,并且属于同一个主题,两个连续的段落顺序也不会颠倒。
2、从不同的文档中随机创建一对段落作为负样本。不同的主题进行选取文档。
缺点:主题预测(判断两个段落是不是来自同一个文档)和连贯性预测(判断两个段落是不是顺序关系)合并为一个单项任务。
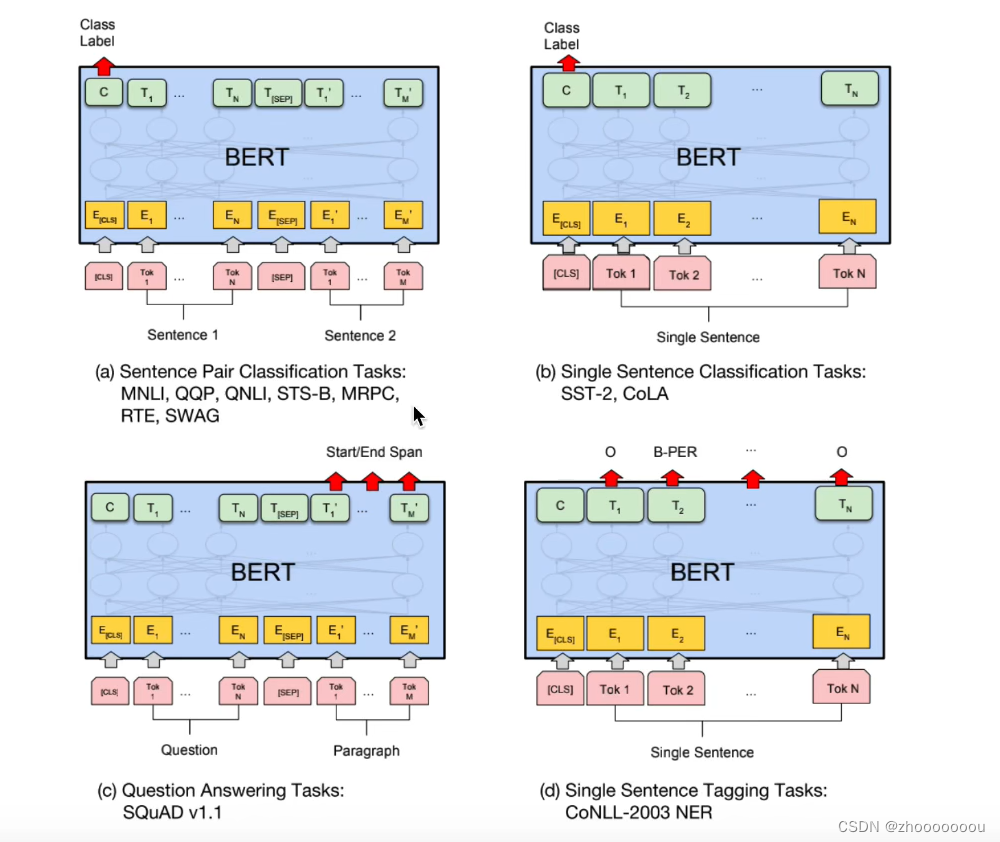
四、如何在下游任务中微调Bert
分为四部分:
(a):句子对分类任务:文本匹配的任务,把两个句子拼接起来去看是否相似,CLS输出0为相似,输出1为不相似
(b):单个句子分类任务:使用CLS的输出去做一个微调,做一个二分类或者多分类
(c):问答任务
(d):序列标注任务:将所有的token输出做一个softmaax去看属于实体中的哪一个
五、如何提升Bert在下游任务中的表现
一般都是使用大公司已经训练好的Bert模型(获取谷歌中文Bert),再根据自己的数据进行微调。
将步骤细化为四步:
1、在大量通用语料上训练一个language model (pretrain)----这一步一般不用做,直接使用中文谷歌Bert即可。
2、在相同领域上继续训练language model (domain transfer 领域自适应)
3、在任务相关的小数据上继续训练language model (task transfer)
4、在任务相关数据上做具体任务(fine - tune 微调)
先 domain transfer 再进行 task transfer 最后 fine-tune 性能效果是最好的。
第二步中:如何在相同领域数据中进行 further pre - training
1、使用动态mask :每次epoch去训练的时候,mask是会变化的,不会一直使用同一个。
2、n-gram mask:比如ERNIE和 SpanBert 都是类似于做了实体词的mask。
参数设置

或者进行数据增强、自蒸馏、外部知识的融入。