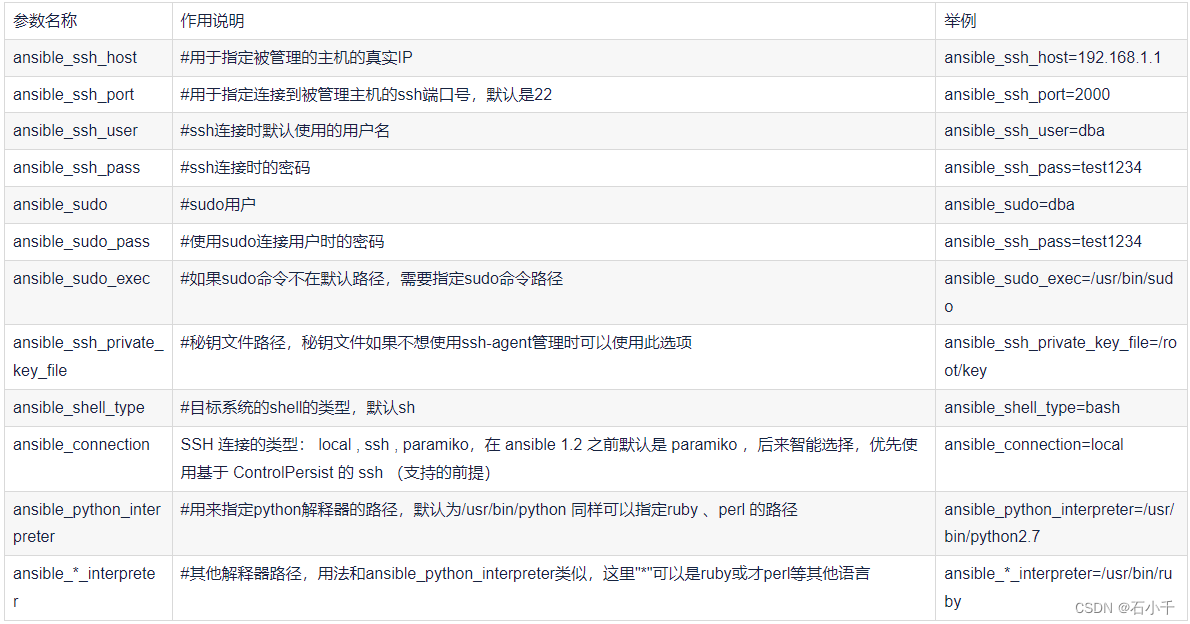
当我们谈到数据库性能优化时,索引是一个非常重要的篇章。数据库索引是一个数据结构,它可以帮助数据库系统更快地查找数据。
-
什么是索引:
数据库索引是一种特殊的数据结构,它可以提高数据库查询的速度。可以简单地将数据库索引理解为一本书的目录。假设你需要找到书中的某个特定主题,你可以直接翻阅目录,找到主题对应的页码,然后快速翻到该页面,而无须一页一页地查找。
同样地,数据库的索引也是如此。假设你需要在数据库表(书)中查询特定行(主题)。如果没有索引,你将必须查看表中的每一行直到找到所需的行,这就是所谓的"全表扫描"。但是,如果你有一个索引,数据库可以直接定位到包含所需数据的行,而无需查看所有行。
一些关键点包括:
-
索引加快查询速度:索引的主要目的是加快查询速度。另外,索引还可以减少数据库引擎需要扫描的数据数量。
-
索引在某些操作中也可以提升性能:除了直接查询(SELECT),还有一些操作(如JOIN、GROUP BY、ORDER BY等)也可以从索引中受益。
-
索引需要维护:尽管索引可以提高查询速度,但良好的索引维护仍很重要。每当数据被插入、更新或删除,索引都需要被更新。其次,失效的或者未使用的索引仍然会占据存储空间并降低写操作速度,因此,需要定期检查并清理这些索引。
-
使用策略:并非所有数据都需要索引。是否创建索引取决于数据的使用模式(如查询类型、频率等)和数据的特性(如数据量、唯一性等)。
-
-
索引的类型:主要有两种类型的索引:聚集索引和非聚集索引。聚集索引按照表中键的顺序排列条目的物理位置。非聚集索引则并不会重新安排物理位置,而是创建一个指向每个行的指针。
-
聚集索引:聚集索引将数据记录直接存储在它的键值的逻辑顺序中。每个表只能有一个聚集索引,因为数据行本身只能按照特定的顺序存储一次。聚集索引通常定义在主键上。
CREATE CLUSTERED INDEX index_name ON table_name(column_name);
-
非聚集索引:非聚集索引和聚集索引的主要区别在于,非聚集索引不会影响数据的物理存储顺序。非聚集索引存储了对数据的逻辑视图,为了提高效率,会保存与每个索引键相关联的指针,这些指针指向存储在硬盘上的数据位置。一个表可以有多个非聚集索引。
CREATE NONCLUSTERED INDEX index_name ON table_name(column_name);
-
唯一索引:唯一索引是一个特殊的索引,它要求所有键值唯一,没有任何重复。一般在有唯一约束的列(例如:邮箱、身份证号)上使用这种索引。
CREATE UNIQUE INDEX index_name ON table_name(column_name);
-
复合索引:复合索引是针对表中的两列或以上创建索引,也就是索引由两个或更多的列组成。创建复合索引时,列的顺序非常重要,第一列是最重要的,决定了索引的效率。
CREATE INDEX index_name ON table_name(column1_name, column2_name);
-
全文索引:全文索引是一种特殊类型的索引,主要用于全文搜索。全文索引并非直接查找完全匹配的文本,而是通过构建一个包含有关数据位置信息的关键字的集合来进行搜索。
CREATE FULLTEXT INDEX index_name ON table_name(column_name);
-
空间索引:空间索引用于地理数据存储,并提供了在二维或三维空间内查找点、线和多边形等图形对象的能力。
CREATE SPATIAL INDEX index_name ON table_name(geometry_column_name);
-
位图索引:位图索引通常用于处理两值或者低基数列(即,列只有少数几个不同值)。位图索引对此类场景非常高效,因此通常在数据仓库环境中使用。
CREATE BITMAP INDEX index_name ON table_name(column_name);
注意:以上的SQL脚本只是示例,并非所有的数据库系统都支持以上的所有语法。比如,在MySQL中并没有区分聚集索引和非聚集索引的关键字,它默认InnoDB存储引擎中的主键索引就是聚集索引。具体的语法可能会因不同的数据库类型(例如:MySQL,PostgreSQL,Oracle等)而有所不同
-
-
索引的优点和缺点
优点:
-
提高查询速度:索引能够大大减少数据库系统需要读取的数据量。
-
提高数据的存取速度:索引可以使用户更快地找到并获取数据。
-
减少排序计算量:在数据已经建立索引的字段上进行排序,查询时可以有效避开排序操作,提高查询效率。
-
提高数据的并发性:通过锁定索引的部分数据,而不是全部数据,可以提高数据库的并发性。
缺点:
-
占用存储空间:创建索引需要占用一定的物理空间。
-
插入,删除和修改数据的速度会变慢:因为在对数据进行插入、删除和修改的时候,索引也需要进行相应的变更。
-
索引维护的成本:对数据表进行大批量的数据更新操作时,可能需要重新构建索引,这会带来额外的时间成本。
-
无法覆盖全部查询情况:索引并不能解决所有的查询需求,有些复杂的查询可能不会使用索引,例如使用了不等于操作或者跨表查询。
-
-
性能优化:
尽管索引可以提高查询速度,但并非每个表都需要创建索引。对小表进行全表扫描通常会更快。同时,如果表中的数据经常变动,过多的索引可能会影响insert和update的速度。因此,正确的索引策略应根据具体的业务场景和需求来制定。此外,除了索引,还有其他数据库性能优化的方法,如SQL查询优化、物理数据库设计优化、硬件优化等。