-
基本原理理解 - 分类问题视角
- 几何直观理解:想象在一个二维平面上有两类不同的点,比如红色的点代表一类,蓝色的点代表另一类。SVM的目标是找到一条直线(在二维空间中是直线,在高维空间中是超平面),将这两类点尽可能完美地分开。这条直线就像是一道“分界线”,使得两类点分别位于直线的两侧。
- 最大化间隔:但不是随便一条能分开两类点的直线都好,SVM要找的是具有最大间隔的直线。间隔是指从这条分界线到最近的点(这部分点被称为支持向量)的距离。为什么要最大化间隔呢?这就好比在两个阵营之间划分地盘,要让中间的“无人区”(间隔)尽可能地宽,这样当有新的点(数据)到来时,分类的准确性更高。
- 例如,假设有一组数据是关于水果的大小和甜度来判断是苹果还是橙子。我们可以把大小作为x轴,甜度作为y轴,每个水果的数据点(大小和甜度的组合)分布在这个二维平面上。SVM会在这个平面上找到一条直线,使得苹果的点在直线一侧,橙子的点在另一侧,并且这条直线到离它最近的苹果点和橙子点的距离(间隔)最大。
-
核函数的引入(处理非线性问题)
- 在很多实际情况中,数据不是线性可分的,就像在一个扭曲的空间里,没办法用一条简单的直线(或超平面)把两类点分开。这时候就需要核函数。核函数可以将原始数据从低维空间映射到高维空间,使得在高维空间中数据变得线性可分。
- 可以把核函数想象成一种魔法工具,它能把原本混乱复杂的点云(数据)进行变形,让它们在新的空间里能够被一条直线(或超平面)分开。比如,在二维平面上有一些数据点像一个圆形分布,无法用直线分开两类点。通过核函数将数据映射到三维空间后,这些点可能就变成了在一个平面的两侧,这样就能用平面(在三维空间中的超平面)来分开它们了。
-
在回归问题中的应用
- SVM用于回归时,目标是找到一个函数,使得尽可能多的样本点落在这个函数周围的一定范围内(这个范围被称为 ϵ − \epsilon - ϵ−不敏感带)。对于那些落在这个范围之外的点,会计算它们的损失,然后通过最小化这些损失来训练模型。
- 例如,在预测土壤中重金属含量与某种土壤特性(如酸碱度)的关系时,SVM回归可以找到一个函数来拟合数据,并且对于那些与函数预测值偏差较大的样本点进行惩罚,从而得到一个比较准确的回归模型,用于根据土壤特性来预测重金属含量。
理解支持向量机
embedded/2024/12/20 14:20:14/
相关文章


CSS padding(填充)
CSS padding(填充)
概述
CSS(层叠样式表)中的padding属性用于设置元素的内边距,即元素内容与边框之间的空间。这个属性对于控制页面布局和元素间距至关重要。本文将详细介绍padding属性的使用方法、值、单位以及如何…
第六章:反射+设计模式
一、反射 1. 反射 (Reflection) :允许在程序运行状态中,可以获取任意类中的属性和方法,并且可以操作任意对象内部的属 性和方法,这种动态获取类的信息及动态操作对象的属性和方法对应的机制称为反射机制。 2. 类对象 和 类的…
[一招过] Python的正则表达式篇
Python 正则表达式(re模块)
正则表达式(regular expression)是用于匹配字符串的一种强大工具。Python 提供了 re 模块来处理正则表达式。通过正则表达式,可以快速匹配、查找、替换、分割字符串等。
1. re 模块基础
…
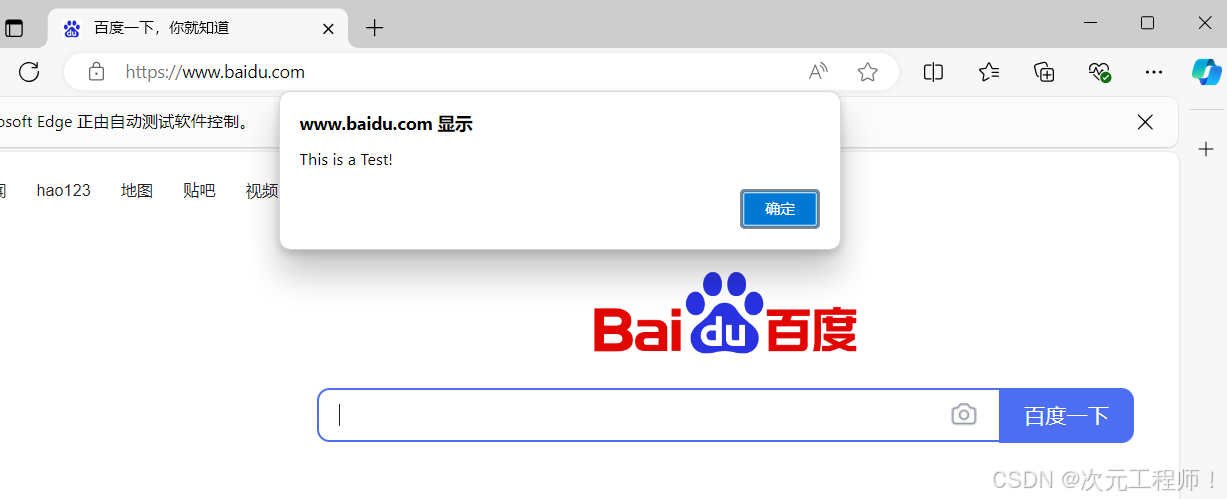
Selenium之execute_script()方法执行js脚本
目录
场景应用和使用
页面滚动
获取返回值
返回JavaScript定位的元素对象
修改元素属性
弹出提示框 场景应用和使用
在自动化测试中,部分场景无法使用自动化Selenium原生方法来进行测试: 滚动到某个元素(位置) 修改…
【C语言】库函数常见的陷阱与缺陷(一):字符串处理函数[2]--gets函数
C语言中的gets函数是一个用于从标准输入(通常是键盘)读取一行字符串的函数。然而,gets函数存在多个陷阱与缺陷,这些缺陷可能导致程序崩溃、安全漏洞或未定义行为。
一、gets功能与用法
gets函数的主要作用是从标准输入(通常是键盘)读取一行字符串,并将其存储在指定的缓…
AIGC:图像风格迁移技术实现猜想
定义以下函数: f(image) -> (style, content) g(style, content) -> image 函数f将图片(image)分解成风格(style)和内容(content)两部分 函数g将风格(style)和内容…

写入hive metastore报问题Permission denied: user=hadoop,inode=“/user/hive”
背景
使用Doris创建hive catalog后,想在hive上的库中创建一个表,报如下图片错误
解决办法
hdfs dfs -ls /看到如下图片所示,只有root用户有写的权限 所以通过export HADOOP_USER_NAMEroot将hadoop的用户名改成root,然后再hdfs…