作者:Sebastian Raschka 博士,
翻译:张晶,Linux Fundation APAC Open Source Evangelist
编者按:本文并不是逐字逐句翻译,而是以更有利于中文读者理解的目标,做了删减、重构和意译,并替换了多张不适合中文读者的示意图。
原文地址:https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
在过去几个月中,OpenVINO™架构师 Yury阅读了众多有关多模态大语言模型的论文和博客,在此基础上,推荐了一篇解读多模态大语言模型的最佳文章《Understand Multimodal LLMs》--- 能让读者很好的理解大语言模型(LLMs)是如何演进为视觉语言模型(VLMs)的。

阅读本文之前,可以先在自己的电脑上运行当前最新的视觉大语言模型Llama 3.2 Vision模型,感受一下视觉语言模型能干什么!
一,什么是多模态大语言模型
多模态大语言模型是能够处理多种“模态”类型输入的大语言模型,其中每个“模态”指的是特定类型的数据,例如:文本、声音、图像、视频等,处理结果以文本类型输出。
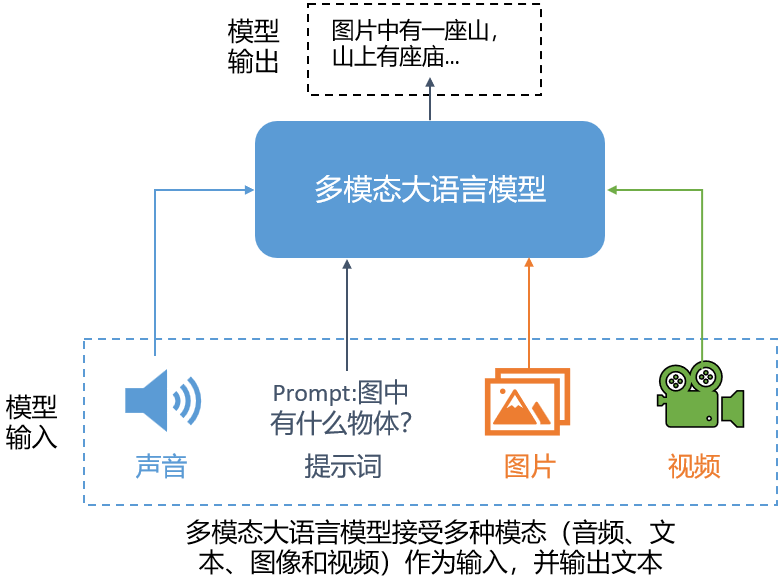
多模态大语言模型的一个经典而直观的应用是解读图片:输入图像和提示词,模型生成该图像的描述(文本),如下图所示。

当然,还有许多其他应用,例如:从图片中提取信息并将其转换为 LaTeX 或 Markdown。
二,构建多模态大语言模型的常见方式
构建多模态 LLM 有两种主要方式:
-
方法 A:统一嵌入解码器架构(Unified Embedding Decoder Architecture);
-
方法 B:跨模态注意架构(Cross-modality Attention Architecture approach)。
(顺便说一句,Sebastian认为这些技术目前还没有正式的术语,但如果您遇到过,请告诉他。例如,更简短的描述可能是“仅解码器(Decoder-Only)”和“基于交叉注意(Cross-Attention-Based)”)
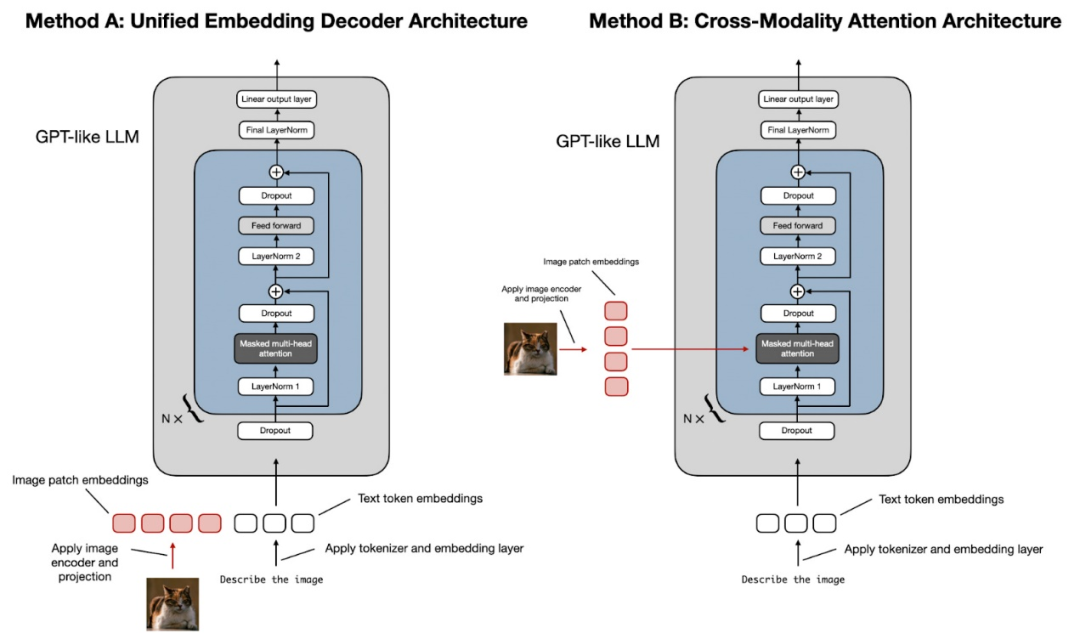
如上图所示,统一嵌入解码器架构使用单个解码器模型,与仅解码器(Decoder-Only)的 LLM 架构(如 GPT-2 或 Llama 3.2)非常相似。在这种方法中,图像被转换为与原始文本分词(本文将大语言模型语境下的Token,统一翻译为分词)具有相同嵌入大小的分词,从而允许 LLM 在连接后同时处理文本和图像输入分词。
跨模态注意架构采用交叉注意机制,将图像和文本嵌入直接集成到注意层中。
三,统一嵌入解码器架构
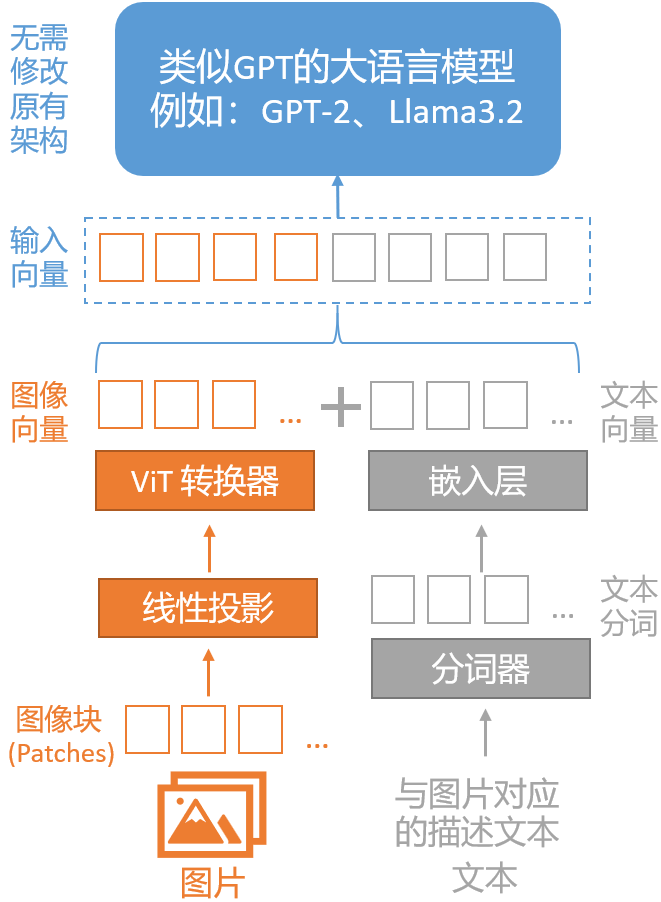
统一嵌入解码器架构是一种将图像向量和文本向量组合成嵌入向量后输入给大语言模型的架构,其优点是:无需修改原有的大语言模型架构。
在统一嵌入解码器架构中,图像跟文本一样,先被转换为分词(Token),然后被转换为嵌入向量,最后跟文本嵌入向量一起,送入原来的大语言模型进行训练或推理。
1,文本向量化
自然语言本文在输入大语言模型前,会先经过分词器(Tokenizer)变成分词,然后经过嵌入层变成向量。

自然语言是非常高维的数据,因为每个可能的单词都被视为一个特征。通过分词化,可以将文本映射到一个固定大小的向量空间中(例如,GPT2模型用的分词器算法是BPE,词汇表大小是50,257),这有助于减少数据的维度,使得模型训练更加高效。
分词数据经过嵌入层(Embedding Layer)转换成向量数据后,方便模型进行特征提取、捕捉丰富的语义信息和上下文关系,并提高模型的性能和计算效率。
将自然语言文本分词化和向量化已经成为Transformer架构模型的标准数据预处理步骤。
2,图像向量化
类似于文本的分词化和向量化,图像的向量化是通过图像编码器模块(而不是分词器)实现的。原始图像首先会被分割成更小的块(patches),这与分词器(Tokenizer)将自然语言的单词(Word)拆成分词(Token)类似。
随后,图像编码器会把这些块由线性投影(Linear Projection)模块和预训练视觉转换器(Vision Transformer)进行编码,最终转换成向量,其大小与文本向量相同。
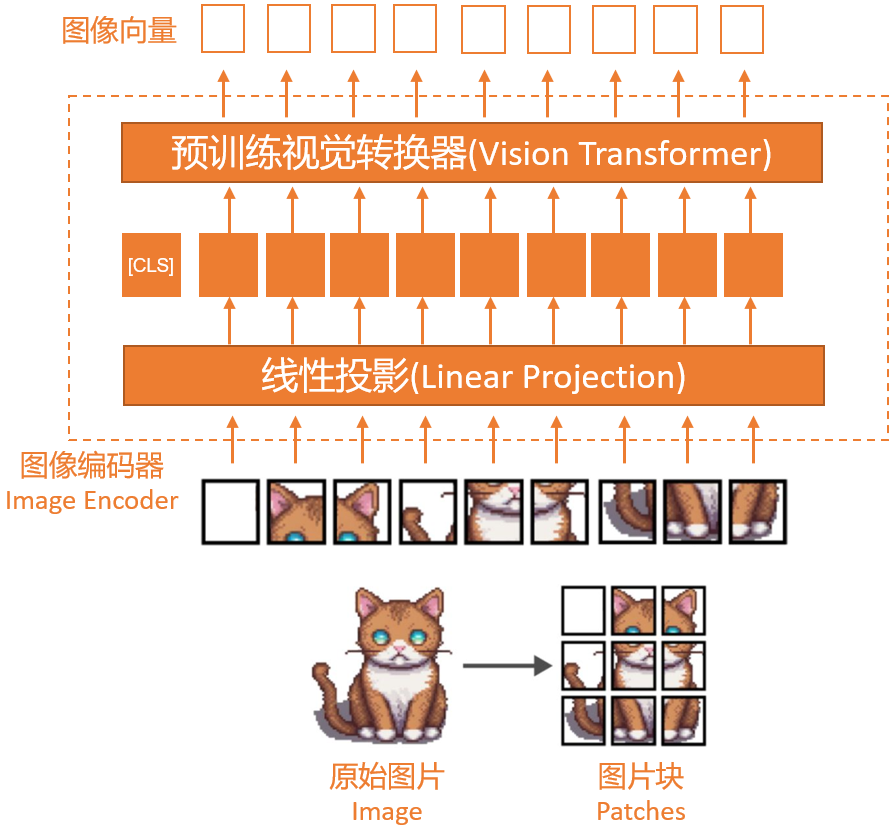
上图中的“线性投影”由一个单一的线性层(即全连接层)组成,这个层的目的是将被展平为向量的图像块投影到与变换器编码器兼容的嵌入尺寸。
当前普遍使用的视觉变换器是CLIP或OpenCLIP等,负责把展平的图像块变换为图像向量。由于图像块向量具有与文本分词向量相同的向量维度,我们可以简单地将它们串联起来作为大语言模型的输入,如本节开头的图片所示。
到此,统一嵌入解码器架构(Unified Embedding Decoder Architecture)介绍完毕。
下一篇文章,我们将继续介绍:跨模态注意架构(Cross-modality Attention Architecture approach)。
如果你有更好的文章,欢迎投稿!
稿件接收邮箱:nami.liu@pasuntech.com
更多精彩内容请关注“算力魔方®”!



![[UUCTF 2022 新生赛]ez_rce](https://img-blog.csdnimg.cn/img_convert/a13d690ea32d3922272e9caabcfcd8dd.png)

