Hadoop安装、整合测试
文章目录
参考原文:https://blog.csdn.net/weixin_44458771/article/details/141711471
1.简介
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一 [2]。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法 [2]。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。到了2008年年初,hadoop已成为Apache的顶级项目。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。广义上也可代指hadoop生态圈
1.优点
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中 。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5.低成本。Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,成本很低。
2.组成
hadoop主要由三大部分组成
- MapReduce:负责计算
- HDFS: 分布式文件存储
- Yarn:资源管理调度 (hadoop2.x之后引入)
2.安装
1.安装jdk(如已安装可跳过)
1.下载安装包
wget --no-check-certificate https://repo.huaweicloud.com/java/jdk/8u151-b12/jdk-8u151-linux-x64.tar.gz
2.解压
tar -zxvf jdk-8u151-linux-x64.tar.gz
3.重命名
mv jdk1.8.0_151/ java8
4.配置环境变量
echo 'export JAVA_HOME=/usr/local/jdk/java8' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile
5.验证是否安装成功
java -version

hadoop_70">2.安装hadoop
1.安装
1.下载安装包
wget --no-check-certificate https://repo.huaweicloud.com/apache/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
2.解压重命名
tar -zxvf hadoop-3.1.3.tar.gz
mv hadoop-3.1.3 hadoop
3.配置环境变量
echo 'export HADOOP_HOME=/usr/software/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile
4.修改配置文件
echo "export JAVA_HOME=/usr/local/jdk/java8" >> /usr/software/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/local/jdk/java8" >> /usr/software/hadoop/etc/hadoop/hadoop-env.sh
5.验证是否安装成功
hadoop version

- Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
- Hadoop 的配置文件位于 /usr/software/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
2. 修改配置文件core-site.xml
编辑
vim /usr/software/hadoop/etc/hadoop/core-site.xml
将下列内容添加进configuration标签
<property><name>hadoop.tmp.dir</name><value>file:/usr/software/hadoop/tmp</value><description>location to store temporary files</description>
</property>
<property><name>fs.defaultFS</name><value>hdfs://0.0.0.0:9000</value>
</property>
3. 修改配置文件hdfs-site.xml
编辑hdfs-site.xml
vim /usr/software/hadoop/etc/hadoop/hdfs-site.xml
<property><name>dfs.replication</name><value>1</value>
</property>
<property><name>dfs.namenode.name.dir</name><value>file:/usr/software/hadoop/tmp/dfs/name</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>file:/usr/software/hadoop/tmp/dfs/data</value>
</property>
<property><name>dfs.namenode.http-address</name><value>0.0.0.0:50070</value>
</property>
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
hadoop_165">4.启动hadoop
初始化namenode
hadoop namenode -format
启动hdfs
start-dfs.sh
若出现以下报错
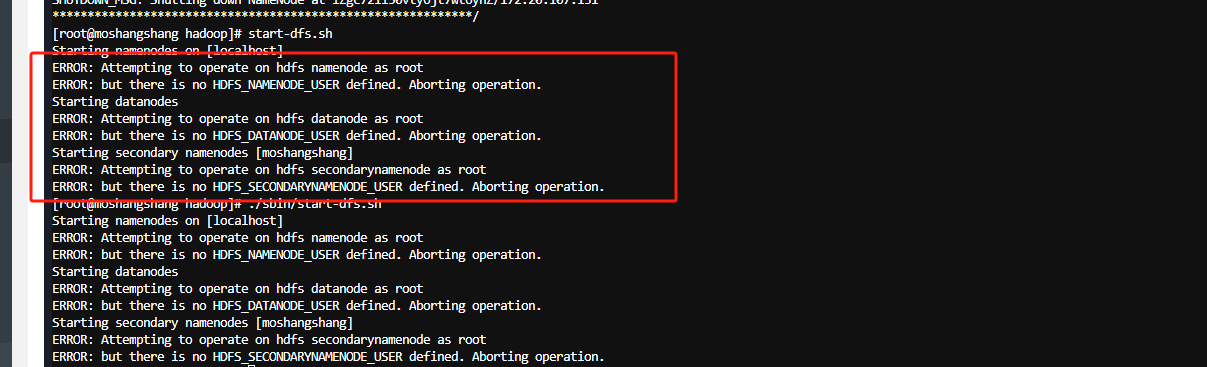
编辑/etc/profile
vim /etc/profile
在文件末尾加入以下内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
激活配置
source /etc/profile
5.启动yarn
start-yarn.sh
6.执行jps查看
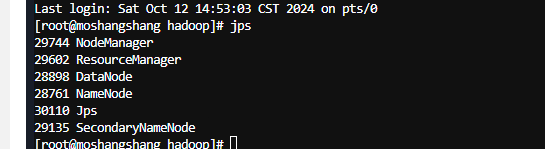
如果失败可以查看hadoop/logs下日志
7.相关端口及配置位置
NameNode:
默认端口:9870
配置文件:hdfs-site.xmlDataNode:
默认端口:9864
配置文件:hdfs-site.xmlResourceManager:
默认端口:8088
配置文件:yarn-site.xmlNodeManager:
默认端口:8043
配置文件:yarn-site.xmlSecondaryNameNode:
默认端口:9868
配置文件:hdfs-site.xml
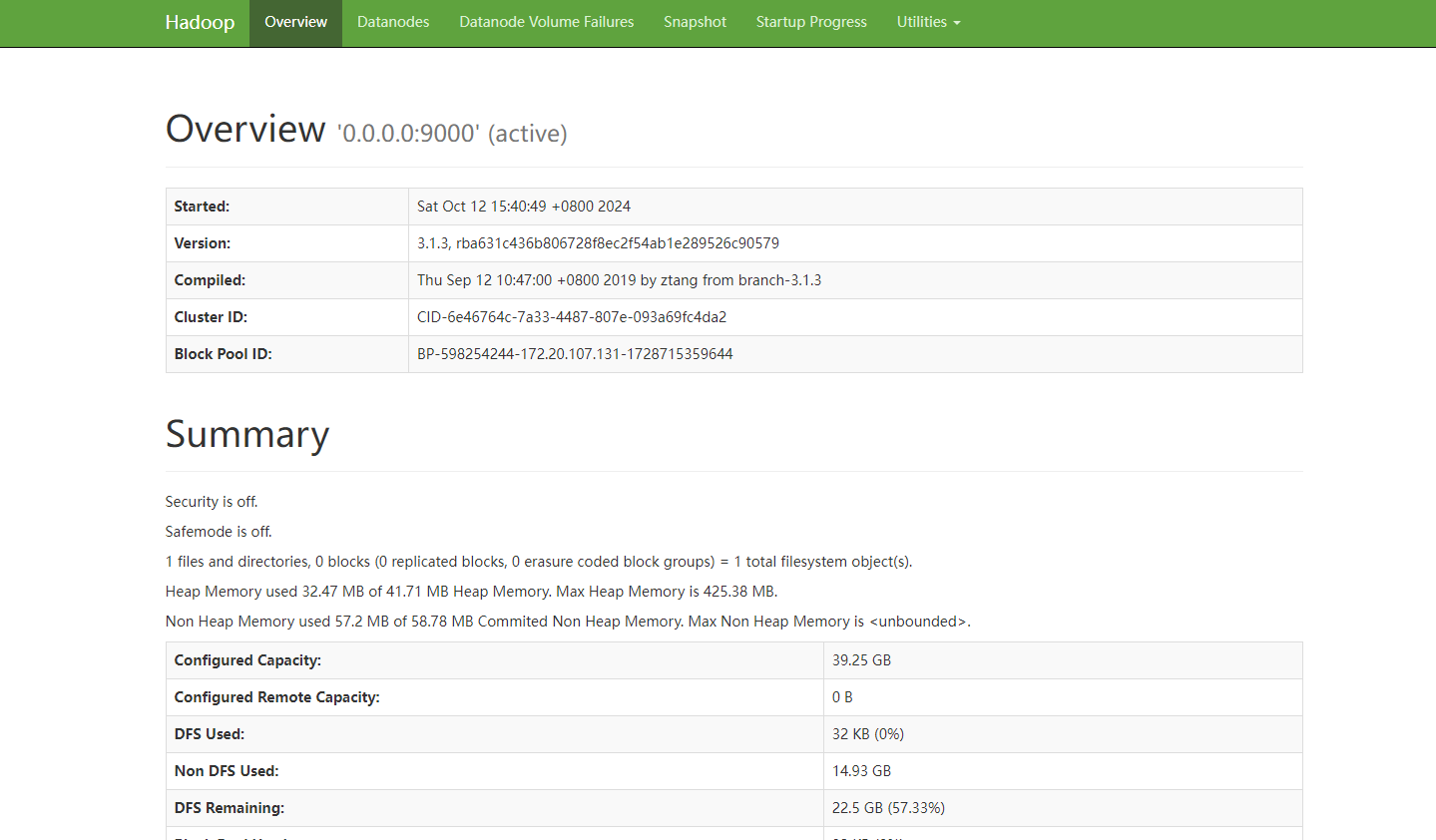
8.访问后台
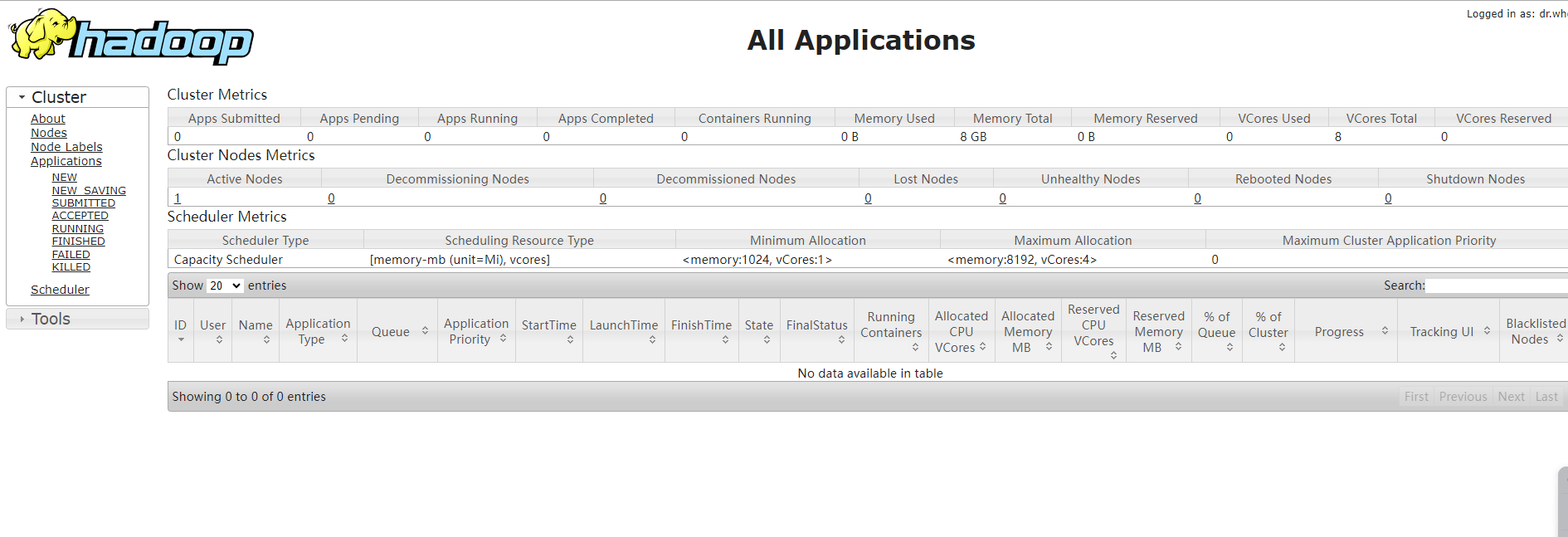
http://127.0.0.1:8088
这个链接通常与Hadoop的YARN资源管理器相关。
http://127.0.0.1:50070
这个链接通常与Hadoop的HDFS(Hadoop分布式文件系统)的Web界面相关。
3.Springboot整合HDFS
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>3.1.3</version></dependency>
测试
@Test
public void test02() throws Exception {Configuration configuration = new Configuration();configuration.set("fs.defaultFS", "hdfs://127.0.0.1:9000");FileSystem fileSystem = FileSystem.get(new URI("hdfs://127.0.0.1:9000"),configuration, "root");System.out.println(fileSystem);
}
如果出现报错
Caused by: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
原因:本地远程连接Hadoop系统时需要在本地配置相关的Hadoop变量 。
下载同版本的winutils:https://github.com/cdarlint/winutils
设置windows环境变量 HADOOP_HOME为下载的版本目录
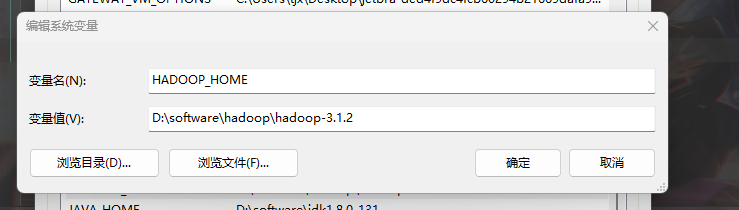
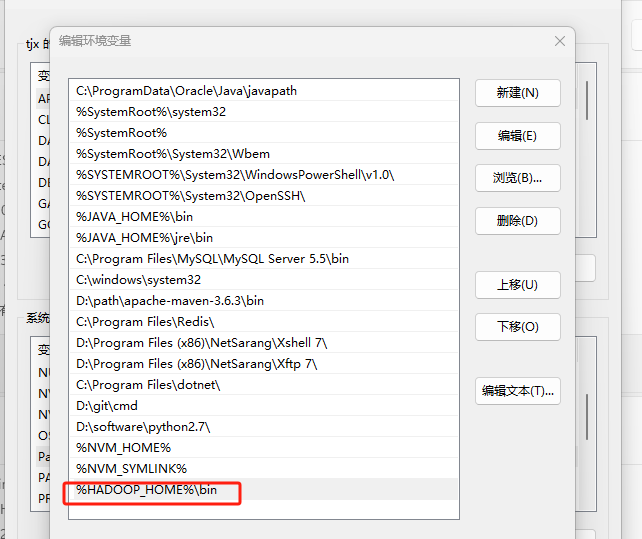
Path新增
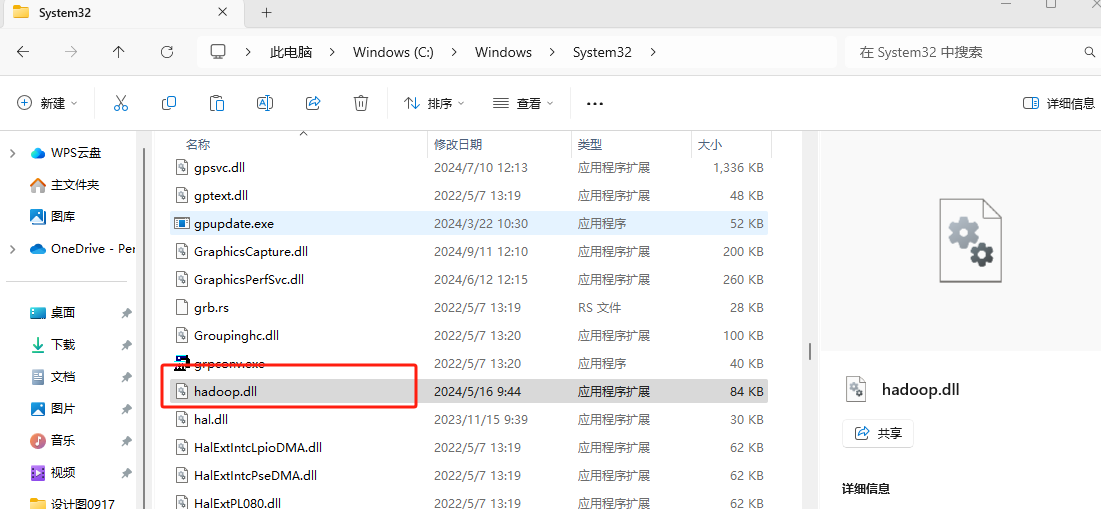
复制bin目录下hadoop.dll文件到windows/system32
重启idea,测试






![[网鼎杯 2018]Fakebook](https://i-blog.csdnimg.cn/direct/9a1e2ffb98fc4202b460d43276476af9.png)