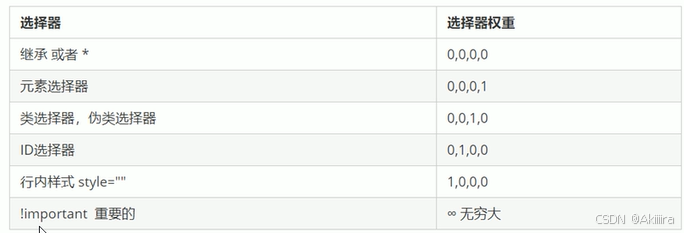
规范化通常是对数据进行缩放,使其符合某种分布特征,规范化在训练和预测时的应用有一些区别
训练时:
目的是使数据发布更加一只,减少不同特征间的尺度差异,能帮助模型更好的学习,因为它确保了不同特征在更新权重时具有相似的能力。
预测时:
目的是确保输入数据与训练数据具有相同的分布特性,从而使模型具有相同的分布特性,使模型能够准确预测,因为模型在训练时已经适应了规范化后的数据分布
为什么使用批量规范化
深层网络很复杂,容易过拟合,所以正则化变得更加重要
原理:
在每次训练迭代中,我们首先规范化输入,即通过减去其均值并除以其标准差,其中两者均基于当前小批量处理。 接下来,我们应用比例系数和比例偏移。 正是由于这个基于批量统计的标准化,才有了批量规范化的名称。
请注意,如果我们尝试使用大小为1的小批量应用批量规范化,我们将无法学到任何东西。 这是因为在减去均值之后,每个隐藏单元将为0。 所以,只有使用足够大的小批量,批量规范化这种方法才是有效且稳定的。 请注意,在应用批量规范化时,批量大小的选择可能比没有批量规范化时更重要。
全连接层使用批量归一化
通常,我们将批量规范化层置于全连接层中的仿射变换和激活函数之间,设全连接层的输入为x,权重参数和偏置参数分别为W和b,激活函数为ϕ,批量规范化的运算符为BN。 那么,使用批量规范化的全连接层的输出的计算详情如下:

卷积层使用批量归一化
对于卷积层,我们可以在卷积层之后和非线性激活函数之前应用批量规范化。 当卷积有多个输出通道时,我们需要对这些通道的“每个”输出执行批量规范化,每个通道都有自己的拉伸(scale)和偏移(shift)参数,这两个参数都是标量。假设我们的小批量包含m个样本,并且对于每个通道,卷积的输出具有高度p和宽度q。 那么对于卷积层,我们在每个输出通道的m⋅p⋅q个元素上同时执行每个批量规范化。 因此,在计算平均值和方差时,我们会收集所有空间位置的值,然后在给定通道内应用相同的均值和方差,以便在每个空间位置对值进行规范化。
预测过程中的批量规范化
一种常用的方法是通过移动平均估算整个训练数据集的样本均值和方差,并在预测时使用它们得到确定的输出。 可见,和暂退法一样,批量规范化层在训练模式和预测模式下的计算结果也是不一样的。
代码实现
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式if not torch.is_grad_enabled():# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)else:assert len(X.shape) in (2, 4)if len(X.shape) == 2:# 使用全连接层的情况,计算特征维上的均值和方差mean = X.mean(dim=0)var = ((X - mean) ** 2).mean(dim=0)else:# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。# 这里我们需要保持X的形状以便后面可以做广播运算mean = X.mean(dim=(0, 2, 3), keepdim=True)var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)# 训练模式下,用当前的均值和方差做标准化X_hat = (X - mean) / torch.sqrt(var + eps)# 更新移动平均的均值和方差moving_mean = momentum * moving_mean + (1.0 - momentum) * meanmoving_var = momentum * moving_var + (1.0 - momentum) * varY = gamma * X_hat + beta # 缩放和移位return Y, moving_mean.data, moving_var.data使用批量规范化层的 LeNet
批量规范化是在卷积层或全连接层之后、相应的激活函数之前应用的。
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5),BatchNorm(6, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),nn.Linear(84, 10))