个人主页:C++忠实粉丝
欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C++忠实粉丝 原创模拟算法(4)_外观数列
目录
1. 题目链接 :
2. 题目描述 :
3. 解法(模拟 + 双指针) :
题目分析:
算法思路 :
代码展示 :
结果分析 :
1. 题目链接 :
OJ链接 : 外观数列
2. 题目描述 :
「外观数列」是一个数位字符串序列,由递归公式定义:
countAndSay(1) = "1"countAndSay(n)是countAndSay(n-1)的行程长度编码。
行程长度编码(RLE)是一种字符串压缩方法,其工作原理是通过将连续相同字符(重复两次或更多次)替换为字符重复次数(运行长度)和字符的串联。例如,要压缩字符串 "3322251" ,我们将 "33" 用 "23" 替换,将 "222" 用 "32" 替换,将 "5" 用 "15" 替换并将 "1" 用 "11" 替换。因此压缩后字符串变为 "23321511"。
给定一个整数 n ,返回 外观数列 的第 n 个元素。
示例 1:
输入:n = 4
输出:"1211"
解释:
countAndSay(1) = "1"
countAndSay(2) = "1" 的行程长度编码 = "11"
countAndSay(3) = "11" 的行程长度编码 = "21"
countAndSay(4) = "21" 的行程长度编码 = "1211"
示例 2:
输入:n = 1
输出:"1"
解释:
这是基本情况。
提示:
1 <= n <= 30
3. 解法(模拟 + 双指针) :
题目分析:
countAndSay(n) 是对 countAndSay(n - 1) 的描述,然后转换成另⼀个数字字符串。
前五项如下:
1. 1
2. 11
3. 21
4. 1211
5. 111221
第⼀项是数字 1
描述前⼀项,这个数是 1 即 “ ⼀ 个 1 ”,记作 "11"
描述前⼀项,这个数是 11 即 “ ⼆ 个 1 ” ,记作 "21"
描述前⼀项,这个数是 21 即 “ ⼀ 个 2 + ⼀ 个 1 ” ,记作 "1211"
描述前⼀项,这个数是 1211 即 “ ⼀ 个 1 + ⼀ 个 2 + ⼆ 个 1 ” ,记作 "111221"
算法思路 :
1. 初始化:
先将 ret 初始化为 "1",这是 * *"count and say" * *序列的第一项。
2. 迭代构建序列 :使用一个外层循环 for (int i = 1; i < n; i++),这个循环会执行 n - 1 次,因为我们已经有了第一项。每次迭代都会根据当前项生成下一项。
3. 内部逻辑 :在每次迭代中,首先定义一个空字符串 tmp,用于存储下一项的内容。
len 存储当前字符串 ret 的长度,以便在后续处理中使用。
4. 双指针扫描 :使用两个指针 left 和 right,初始都指向字符串的开始位置。目的是扫描字符串并统计相邻相同字符的数量。
内层循环:while(right < len && ret[left] == ret[right]) 用来找到从 left 开始的相同字符的连续个数。right 会向右移动,直到遇到不同的字符或到达字符串末尾。
一旦 right 指向了不同的字符(或者到达了字符串的末尾),就可以得知从 left 到 right 的字符是相同的,且数量为 right - left。
5. 生成下一项 :使用 tmp += to_string(right - left) + ret[left]; 将当前相同字符的数量和字符本身拼接到 tmp 中。例如,如果遇到 "11",就会在 tmp 中添加 "21"(表示有两个1)。
更新 left 为 right,准备处理下一个不同的字符。
6. 更新当前项 :在内层循环完成后,将 tmp 赋值给 ret,这就构成了新的 * *"count and say" * *项。
7. 返回结果 :当外层循环完成后,返回最终构建好的字符串 ret,即为 * *"count and say" * *序列的第 n 项。
代码展示 :
class Solution {
public:string countAndSay(int n) {//最基本的情况string ret = "1";for(int i = 1; i < n; i++)//解释n - 1次ret即可{string tmp;int len = ret.size();for(int left = 0, right = 0; right < len;){while(right < len && ret[left] == ret[right]) right++;//"11" -> 2个1 -> "21" //to_string是将不同类型的数据变成字符串 tmp += to_string(right - left) + ret[left];left = right;}ret = tmp;}return ret;}
};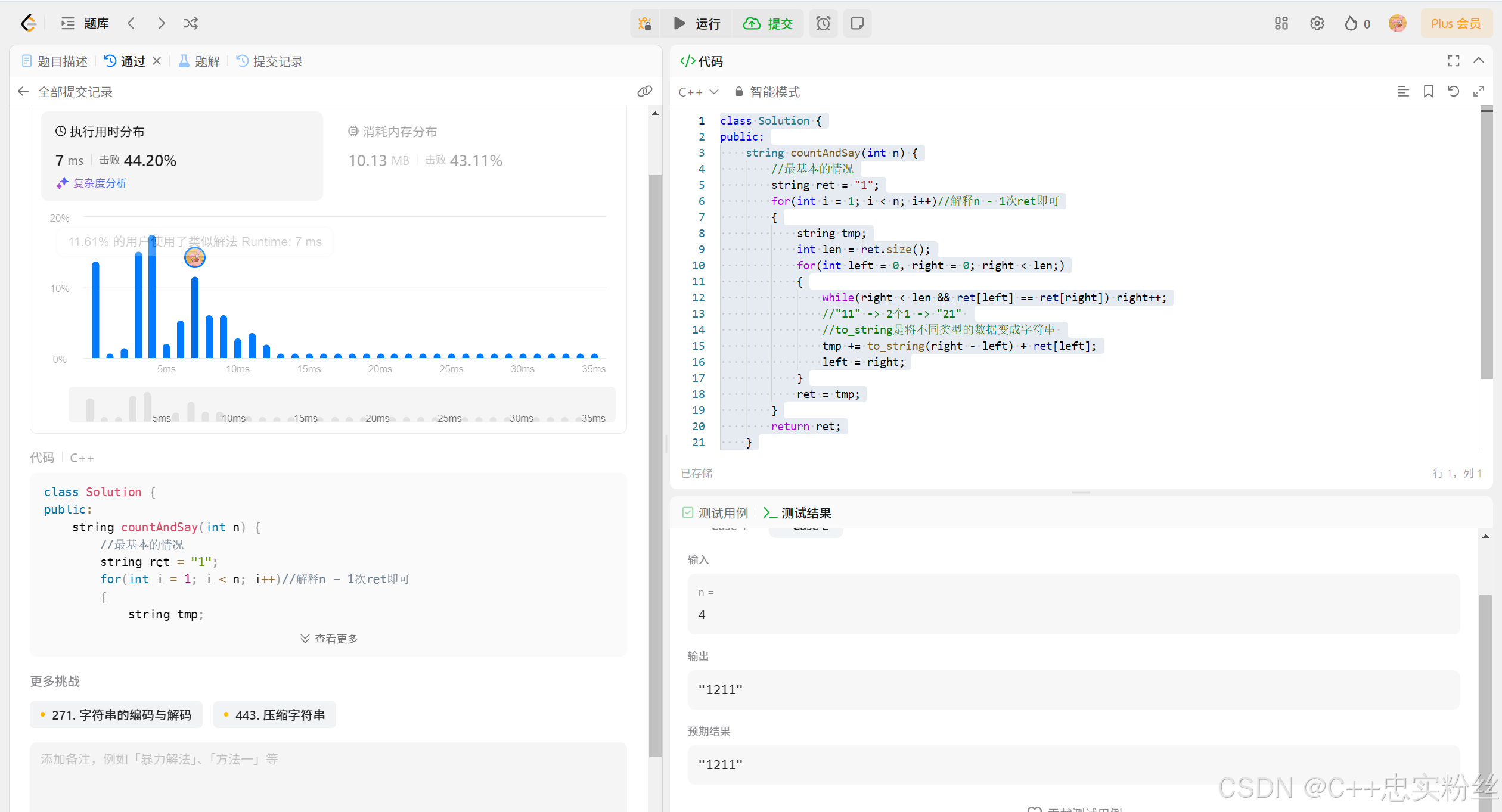
结果分析 :
1. 每次迭代的过程都是对当前字符串的描述,并将描述生成的字符串用于下一次迭代。
2. 时间复杂度 : 虽然每一项的描述可能导致字符串长度的增加,但由于字符的重复性,时间复杂度为 O(2 ^ n),也就是说随着 n 的增大,生成过程的复杂度会迅速增加。
3. 这个算法的实现既高效又简单,利用了字符串的基本操作和简单的逻辑判断,能够有效生成** "count and say" * *序列。