文章目录
- springCloudSleuth简介
- 链路追踪?
- SpringCloudSleuth
- 术语
- 链路示意图
- zipkin
- 依赖
- 配置
springCloudSleuth简介
链路追踪?
什么是链路追踪?就是将一次分布式请求还原成调用链路,将一次分布式请求的调用情况集中展示,如各个服务节点的耗时、具体请求的服务器、各节点的请求状态等,主要是用于分布式系统进行问题定位
SpringCloudSleuth
SpringCloudSleuth是SpringCloud提供的一套分布式服务跟踪的解决方案,并且支持zipkin
术语
- span 跨度:基本工作单元,span使用一个64位的id唯一标识,还包含有描述、时间戳、span 父id等,根span被称为root span,该span的id与trace id相等
- trace 跟踪:一组共享root span的span组成的树状结构称为trace,trace中的所有span都共享该trace的id
- annotation 标注:annotation用来记录事件的存在,其中核心annotation用来定义请求的开始和结束
- CS(Client Sent 客户端发送):客户端发起一个请求,该annotation描述了span的开始
- SR (Server Received服务端接收):服务器端获得请求并准备处理它,使用SR减去CS时间戳,可以得到网络延迟
- SS (Server Sent 服务端发送):该annotation表示完成请求处理,使用SS减去SR时间戳,可以得到服务端处理请求的时间
- CR (Client Received 客户端接收):span结束标识,客户端成功接收到服务端的响应,CR减去CS时间戳,可以得到客户端发送请求到服务器响应的时间
链路示意图
一条链路根据TraceId唯一标识,SpanId标识发起的请求信息,各span通过parentId串联起来
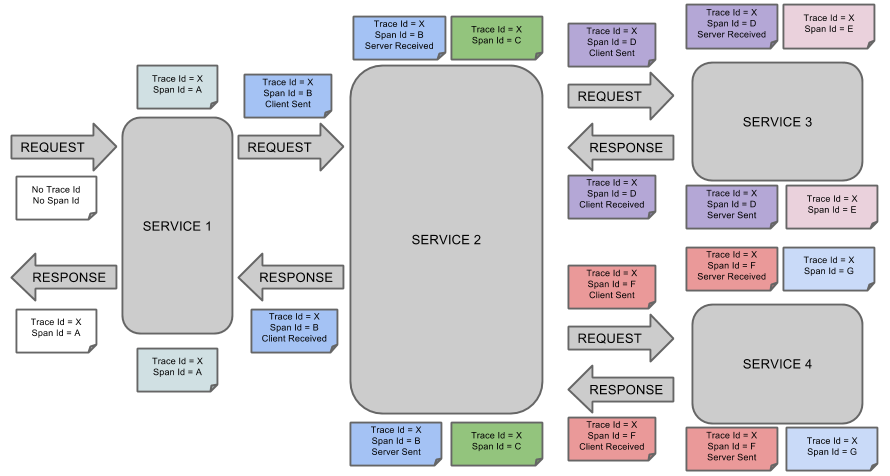
TraceId类似于树结构的Span集合,表示一条调用链路,作为链路的全局唯一标识
Span表示调用链路的来源,之间存在着父子关系,上游span是下游span的父span,一个span就是一次请求信息
zipkin
Zipkin是Twitter开源的分布式跟踪系统,主要功能是收集系统的时序数据,从而追踪微服务架构的系统延时等问题。架构中包含Reporter,Transport,Colletor,Storage,API,UI几个部分
Reporter
集成在每个服务的代码中,负责Span的生成,带内数据(traceid等)的传递,带外数据(span)的上报,采样控制
Transport
为带外数据上报的通道,zipkin支持http和kafka两种方式
Colletor
负责接收带外数据,并插入到集中存储中
Storage
为存储组件,适配底层的存储系统,zipkin提供默认的in-memory存储,并支持Mysql,Cassandra,ElasticSearch存储系统
API
提供查询、分析和上报链路的接口。接口的定义见zipkin-api
UI
用于展示页面展示
依赖
<!-- 链路跟踪 包含sleuth和zipkin -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置
spring:# 链路跟踪zipkin:base-url: http://localhost:9411 #zipkin的地址sleuth:sampler:probability: 1 #采样率,1表示全部采集
之后进行访问就可以在zipkin中看到请求的调用链路了
参考文献
- springCloudSleuth简介



