SQL语法
CREATE TABLE
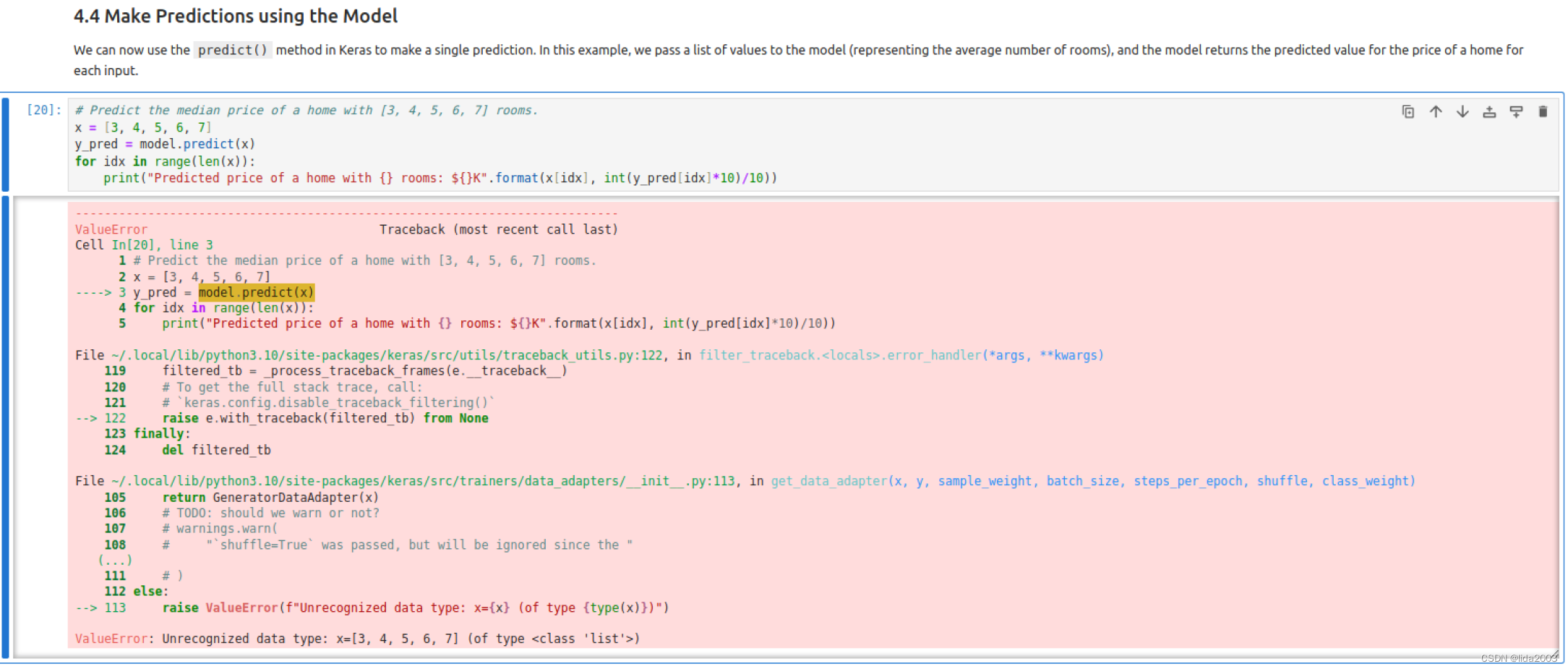
sql">CREATE TABLE table_name (column_1 datatype,column_2 datatype,column_3 datatype
);ALTER TABLE
sql">ALTER TABLE table_name ADD column_name datatype;UPDATE TABLE
sql">UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;sql">UPDATE table_1 SET column_1 = "value_1" where column_2 = "value_2"ALTER TABLE table_1 DROP PARTITION (p_date = "20240501")
ALTER TABLE table_1 CHANGE COLUMN col_old col_new col_type;DELETE TABLE
sql">DELETE FROM table_name WHERE conditionINSERT TABLE
sql">INSERT INTO table_name (column_1, column_2, column_3) VALUES (value_1, 'value_2', value_3)DROP TABLE
sql">DROP TABLE table_name;SELECT basics
IN用法、Between用法、LIKE用法、NOT LIKE用法
sql"># select ... from ... where ...
select population from world where name = 'Germany'
# IN 用法
select name, population from world where name in ('Sweden', 'Norway', 'Denmark')
# Between 用法
select name, area from world where area between 200000 and 250000
# LIKE 用法
select name, population from world where name like "Al%"
select name from world where name like '%a' or name like '%l'GROUP BY用法、HAVING用法
Hive中在group by查询的时候要求出现在select后面的列都必须是出现在group by后面
sql">#GROUP BY合并行和汇总数据
select continent, population from world group by continent#HAVING过滤由GROUP BY子句聚合的数据,得到有限记录集
select continent, population from world group by continent having population > 1000AVG、AS、COUNT、MAX、MIN
LIMIT用法,限制结果返回的行数
sql"># 返回前n行记录
select ... from ... limit n
# 返回从第m行开始的n行记录
select ... from ... limit m, nORDER BY用法【desc降序,asc升序】
sql">select name_1, name_2, name_3 from table_1 order by name_2 desc;
select name_1, name_2, name_3 from table_1 order by name_2 asc;JOIN用法【其中LEFT JOIN等同于LEFT OUTER JOIN】
sql"># INNER JOIN 【也叫 Inner Join,在两个表中选择具有匹配值的记录】
select * from table_1 as a join table_2 as b on a.id = b.id# LEFT JOIN 【返回左表的所有记录,以及右表的匹配记录。即使右表中没有匹配的记录,左表中的记录也会被返回。左表中的行如果在右表中没有匹配,那么右表的值将为 null】
select * from table_1 as a left join table_2 as b on a.id = b.id# RIGHT JOIN 【返回右表的所有记录,以及左表的匹配记录。与 LEFT JOIN 相反,这将返回右表的所有记录,即使在左表中没有匹配的记录。右表中的行如果在左表中没有匹配,那么左表的列就会有 null】
select * from table_1 as a right join table_2 as b on a.id = b.id# FULL OUTER JOIN 【返回所有在其中一个表中有匹配的记录。因此,如果左表中有一些记录在右表中没有匹配,这些记录将被包括在内。同时,如果右表中有一些记录在左表中没有匹配,这些记录也会被包括在内】
Select table_1.name, table_2.id from table_1 full outer join table_2 on table_1.name = table_2.name order by table_1.id
CASE WEHN ... THEN ... ELSE ... END用法
sql">selectcasewhen play_cnt < 2000 then 1when play_cnt < 4000 then 2else 3end play_num
fromtable_1
wherecolumn_1 = "value_1"CONCAT用法
- concat()用于将多个字符拼接起来,CONCAT(str1,str2,…)
- concat_ws()函数用于在拼接的时候指定分隔符,CONCAT_WS(separator,str1,str2,…)
- group_concat()函数返回一个字符串结果,该结果由分组中的值连接组合而成
sql"># concat用法
select concat(str1, str2) from table_1 where column_1 = "value_1"
# concat_ws用法
selectconcat_ws("_",name_1,name_2,name_3)
fromtable_1
wherename_1 = "value_1"group_concat函数用法
sql">有表如下
+----------+----+--------------------------+
| locus | id | journal |
+----------+----+--------------------------+
| AB086827 | 1 | Unpublished |
| AB086827 | 2 | Submitted (20-JUN-2002) |
| AF040764 | 23 | Unpublished |
| AF040764 | 24 | Submitted (31-DEC-1997) |
+----------+----+--------------------------+sql">SELECT locus,GROUP_CONCAT(id) FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;
SELECT locus,GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;
SELECT locus,GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;CONCAT_WS(SEPARATOR ,collect_set(column)) 等同于 GROUP_CONCAT() 但是丧失排序性
SPLIT用法【HIVE】
在Hive中,可以使用内置的函数split来将一个字符串按照指定分隔符分割;split函数返回的结果是一个数组类型,因此在进行一些操作时需要将其转换为其他适合的数据类型,例如字符串或结构体等。可以使用函数concat_ws、explode、array等函数来进行转换。
sql">split(str, regex)select split(name_1, ',') from table_1 where name_2 = "value_2"EXPLODE用法
将列表中的数据展开
sql">select explode(name_1) from table_1Lateral View Explode
使用Hive中的LATERAL VIEW关键字来进行表的展开操作,并将展开的结果作为一列结果集中的元素。这种操作在Hive中被称为“表的侧视图转换(Lateral View Explode)”。
sql">selecta.name_1, photo_id
fromtable_1 a LATERAL VIEW explode(split(a.name_2, ',')) exploed_table as photo_id
wherea.name_1 = "value_1"WITH ... AS ... 用法
with as 用法 - 知乎
# 单个别名
with tmp as (select * from table_1)
# 多个别名
with
tmp as (select * from table_1)
tmp2 as (select * from table_2)
...
# 相当于构建临时表
with
e as (select * from table_1),
d as (select * from table_2)
select * from e, d where e.value = d.valuewith temp as (select*fromtable_1wherep_date = "20240415"
)
selectcount(*)
fromtempHive内置的json解析函数
get_json_object
【解析 json 的字符串 json_string, 返回 path 指定的内容。如果输入的 json 字符串无效,结果返回 NULL】
get_json_object(json_string, '$.column')json_tuple
【解析 json 的字符串 json_string, 同时指定多个 json 数据中的 column,返回对应的 value。如果输入的 json 字符串无效,结果返回 NULL】
json_tuple(json_string, column1, column2, column3 ...)selectt1.name,t1.age,t1.prefer,t1.height,t1.nation
from(selectjson_datafromtest_table1) t0 lateral view json_tuple(t0.json_data,'name','age','prefer','height','nation') t1 as name,age,prefer,height,nation;- get_json_object 函数的使用语法中,使用到$.加上 json 的 key;
- json_tuple 函数的使用语法中,不能使用$.加上 json 的 key,如果使用则会导致解析失败;
- json_tuple 函数与 get_json_object 函数对比,可以发现 json_tuple 函数的优点是一次可以解析多个 json 字段;
- 但是如果被要求解析的 json 是一个 json 数组,那么这两个函数都无法完成解析;
collect_list/collect_set函数
它们将分组中某列转换成一个数组返回, collect_list不去重, collect_set去重
select username, collect_list(video_name) from t_visit_video group by username ;
select username, collect_set(video_name) from t_visit_video group by username;
select username, collect_list(video_name)[0] from t_visit_video group by username;
array_join函数
在 Hive 中,array_join 函数用于将一个数组中的元素按照指定的分隔符连接成一个字符串。
sql">array_join(array, delimiter)
SELECT array_join(items, ',') FROM test;HIVE、Spark SQL、MySQL区别
Hive、Spark SQL和MySQL都使用SQL语言进行数据查询和操作,存在细微语法区别
sql">1. 变量的定义和使用
# Hive、Spark SQL中, 使用${}语法定义、使用变量
SET my_var = 'value'
select * from my_table where my_col = '${my_var}';
# MySQL中,使用@语法定义、使用变量
SET @my_var = 'value'
SELECT * from my_table where my_col = @my_var;2. NULL值比较
# 在Hive中,需要使用IS NULL或IS NOT NULL来比较NULL值
SELECT * FROM my_table WHERE my_col IS NULL;
# 在MySQL中,可以使用= NULL或!= NULL来比较NULL值
SELECT * FROM my_table WHERE my_col = NULL;3. 数据类型的格式转换
# 在Hive和Spark SQL中,需要使用CAST函数来显式转换数据类型
SELECT CAST(my_col AS INT) FROM my_table;
# 在MySQL中,需要使用CONVERT()函数来显式转换数据类型
SELECT CONVERT(my_col, INT) FROM my_table;4. 时间戳的格式化
# 在Hive和Spark SQL中,可以使用FROM_UNIXTIME()函数将时间戳格式化为可读的时间字符串
SELECT FROM_UNIXTIME(my_timestamp, 'yyyy-MM-dd HH:mm:ss') FROM my_table;
# 在MySQL中,可以使用DATE_FORMAT()函数将时间戳格式化为可读的时间字符串
SELECT DATE_FORMAT(FROM_UNIXTIME(my_timestamp), '%Y-%m-%d %H:%i:%s') FROM my_table;SUBSTRING_INDEX
regexp_replace(bs_key, '\\.jpg$', '')