引言
PostgreSQL作为一款高度可扩展的企业级关系型数据库管理系统,其内置的分区表功能在处理大规模数据场景中扮演着重要角色。本文将深入探讨PostgreSQL分区表的实现逻辑、详细实验过程,并辅以分区表相关的视图查询、分区表维护及优化案例,以揭示这一功能的强大之处。
一、PostgreSQL分区表实现逻辑
1.1. 分区类型详解
PostgreSQL支持两种主要的分区类型:
• 范围分区(Range Partitioning)
根据表中某一列的值范围将表分割成若干个分区。例如,我们可以按照时间字段(如日期)创建按年、季度或月份的范围分区。

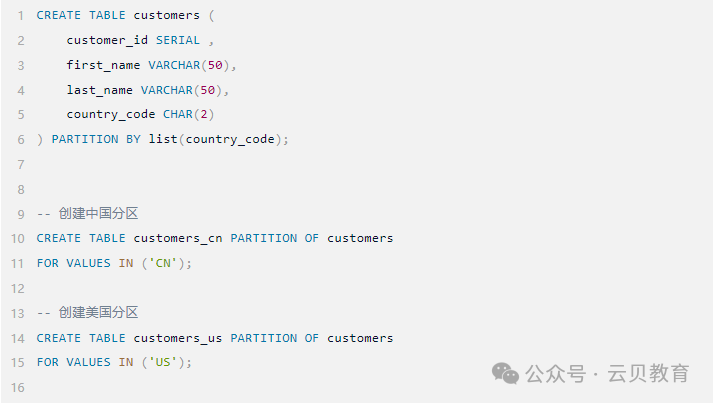
• 列表分区(List Partitioning)
根据某一列的特定值列表来划分分区。例如,可以根据国家/地区的枚举值进行列表分区。
• hash分区(hash Partitioning)
根据某一列的特定值列表来划分分区。例如,可以根据国家/地区的枚举值进行列表分区。

查看表结构

插入数据,查看数据分布

二、分区表维护操作
2.1 添加分区
示例:添加range分区

2.2 删除分区

2.3 ATTACH分区
ATTACH操作:ATTACH操作用于将一个已存在的表作为分区添加到一个分区表中。这样做的好处是可以将预先填充好数据的表作为分区快速加入到分区表体系中,或者在需要调整分区布局时将一个表转换为分区表的分区。

其中:
• partitioned_table:已存在的分区表名。
• new_partition_table:要作为分区添加的已存在的表名,该表应具有与partitioned_table相同的结构,并且其数据应符合所指定的分区范围。
• FOR VALUES IN (partition_range):指定新分区所对应的分区键值范围。partition_range应与分区表的分区策略相匹配。
示例:
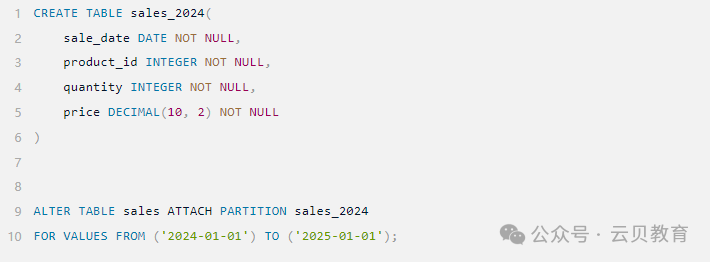
假设有一个按年份分区的销售表sales,现在有一张名为sales_2024的表,里面存储了2024年的销售数据,希望将其作为sales表的一个分区。

-- 假设sales_2024表已存在且结构与sales表相同,数据均为2024年的销售记录
2.3 DETACH分区
DETACH操作:DETACH操作用于从分区表中移除一个现有的分区。
这通常在需要临时独立处理某个分区的数据(如备份、迁移、清理等)或者调整分区布局时使用。
语法:
ALTER TABLE partitioned_table DETACH PARTITION existing_partition;
其中:
• partitioned_table:已存在的分区表名。
• existing_partition:要从分区表中分离出去的现有分区表名。
示例:假设要将sales表中存储2023年销售数据的分区sales_2023分离出来,以便单独进行数据清理。
![]()
注意事项:
• ATTACH与DETACH操作都会立即生效,对分区表结构进行更改。在执行这些操作时,应确保没有正在进行的事务依赖于被操作的分区。
• 分离出来的分区表仍保留其数据,可以独立进行查询、更新等操作。但在DETACH之后,该分区不再受分区表的查询优化等特性影响。
• 在ATTACH操作中,新分区表的数据应严格符合所指定的分区范围,否则可能会导致数据完整性问题或查询错误。
• 对于DETACH操作,确保在分离后对分区表的查询不受影响,可能需要调整查询条件或创建合适的索引。
2.4 自动扩建分区
请读者使用pg_partman插件完成
三、分区表优化示例
在处理海量数据的场景下,PostgreSQL的分区表功能成为了提升查询性能和管理效率的关键利器。案例背景一家电子商务公司拥有一个庞大的订单表,表中记录了历年来的所有订单数据。随着业务的发展,订单表的数据量已经达到了数十亿行,导致查询性能严重下滑,尤其在处理特定时间段的报表查询时,响应时间变得极其漫长。问题分析
1. 查询性能低下:由于订单表庞大,任何涉及到全表扫描的查询都会花费很长时间。
2. 数据维护困难:数据清理和归档工作复杂,难以对老旧数据进行高效管理。
分区表优化方案基于上述问题,我们采用了PostgreSQL的范围分区功能对订单表进行优化。
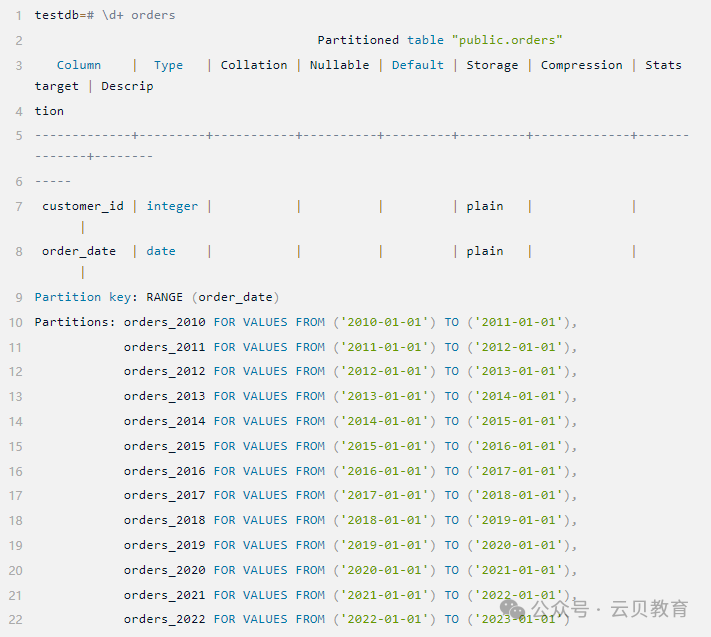
步骤一:创建分区表
首先我们决定按年份对订单表进行范围分区,每年一个分区:

-- 创建2010年至2022年的分区

--查看当前分区
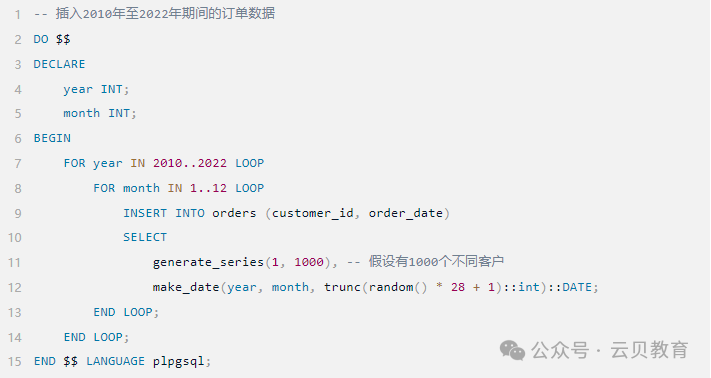
--模拟数据
步骤二:创建普通表

步骤三:对比性能
1)非分区表

2) 分区表
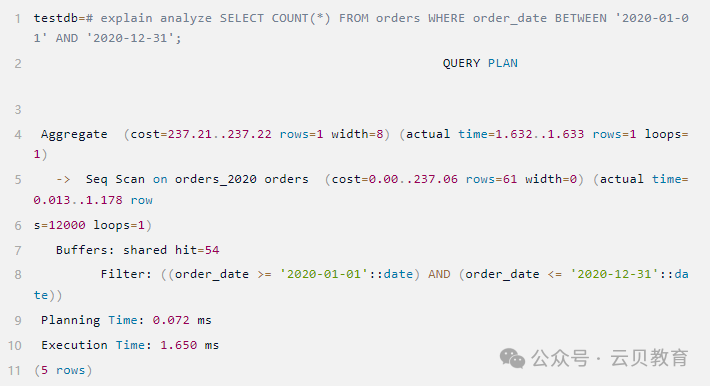
对比以上两个执行计划
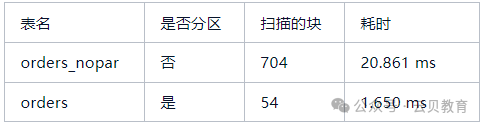
效果验证优化后,查询性能有了显著提升,因为查询仅针对特定年份的分区,避免了对整个大表的扫描。此外,数据维护工作也变得更加方便,可以直接操作单个分区进行数据清理和归档。
注: 本文为云贝教育 刘峰 原创,请尊重知识产权,转发请注明出处,不接受任何抄袭、演绎和未经注明出处的转载。






