

✨ Blog’s 主页: 白乐天_ξ( ✿>◡❛)
🌈 个人Motto:他强任他强,清风拂山冈!
💫 欢迎来到我的学习笔记!

什么是Llama3.1?
Llama3.1 是 Meta(原 Facebook)公司开发的一款超大型语言模型。它的发布时间是在2024 年 7 月 23 日,模型系列包括 Llama3.1 8b、Llama3.1 70b 和 Llama3.1 405b。
| 性能与特点 | 详情 |
|---|---|
| 1. 处理能力提升 | 长文本处理能力增强,所有三款模型都具备改进的 128k 上下文长度,相比之前版本增加了 12 万个标记(token),模型容量是上一版本的 16 倍。多语言能力进步,提升了在英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语等八种语言对话场景中的推理能力。 |
| 2. 语言理解与推理能力 | 更好地理解上下文,可从长篇文本中获取更多信息以做出更明智决策并生成更细致回应。强大的逻辑推理能力,能灵活把握语义关联,合理引申和过渡话题。 |
| 3. 运算及专业领域表现 | 在数学运算、工具使用等专业领域有不错表现,可精准进行复杂计算和操作。 |
| 4. 应用领域 | 内容生成,如故事、文章和诗歌等。聊天机器人与虚拟助手,增强对话能力。语言翻译,提供多语言即时高质量翻译。代码生成,协助开发人员。医疗与科研,辅助疾病预测和药物发现等。 |
下面我们开始学习部署 Llama3.1 的 8B 版本,该版本至少需要GPU显存16G。
本次部署的测试环境:
<font style="color:rgba(60, 60, 67, 0.78);">ubuntu 22.04 python 3.12 cuda 12.1 pytorch 2.4.0</font>
部署流程
创建实例
- 进入丹摩DAMODEL|让AI开发更简单!算力租赁上丹摩!店家开始创建实例:
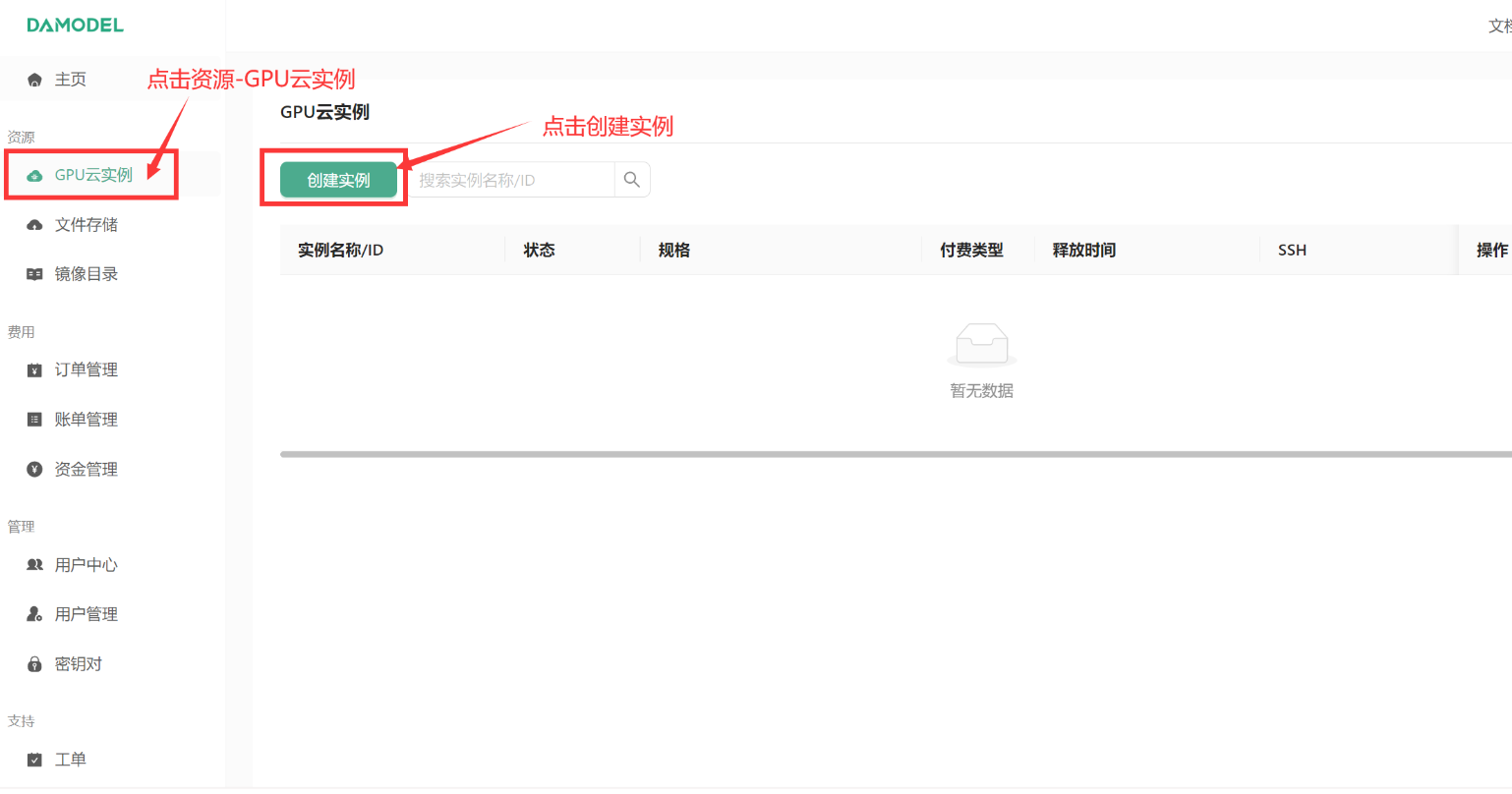
-
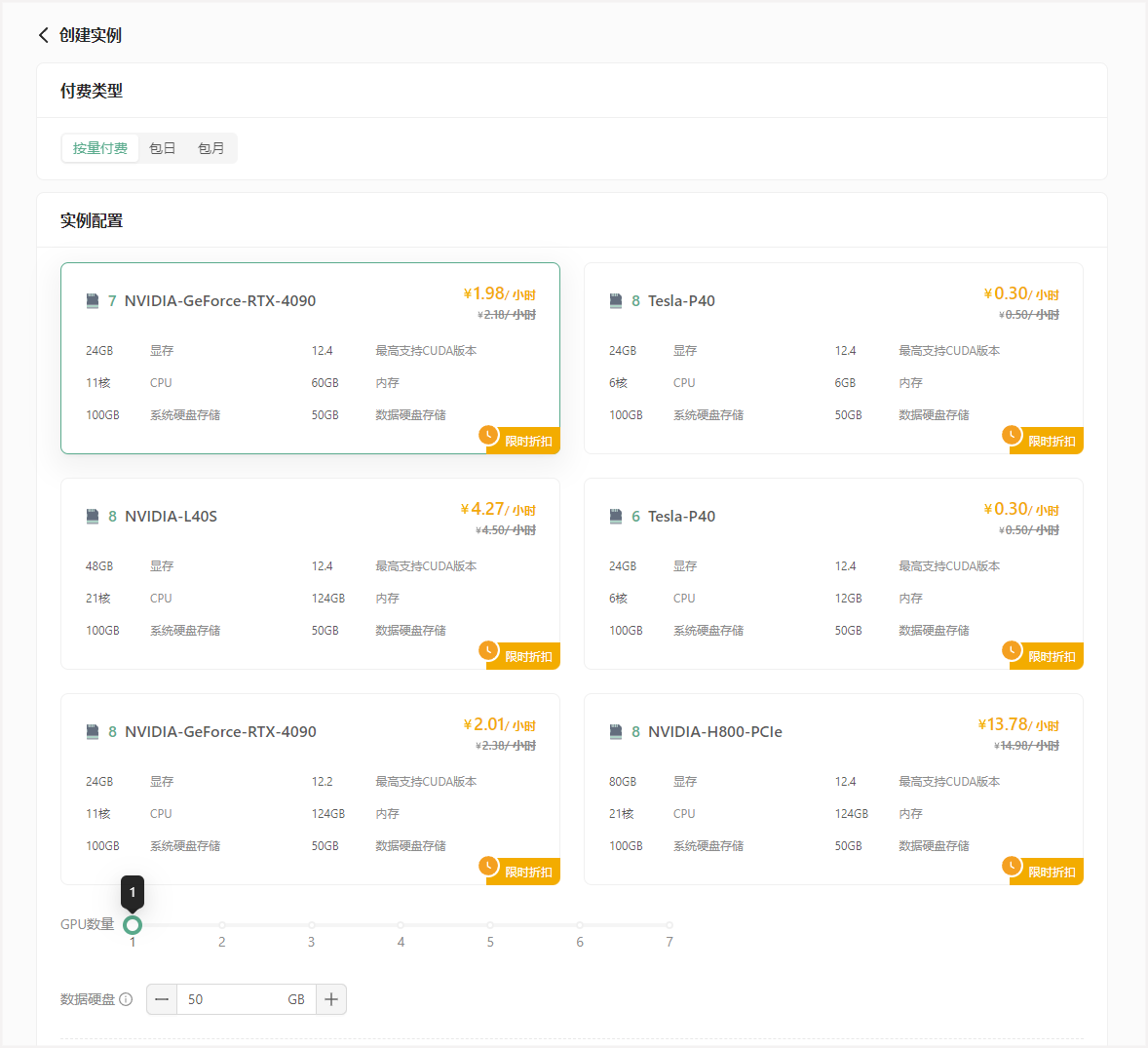
进入创建页面后,首先在实例配置中选择付费类型。一般短期需求可以选择按量付费或者包日,长期需求可以选择包月套餐;
-
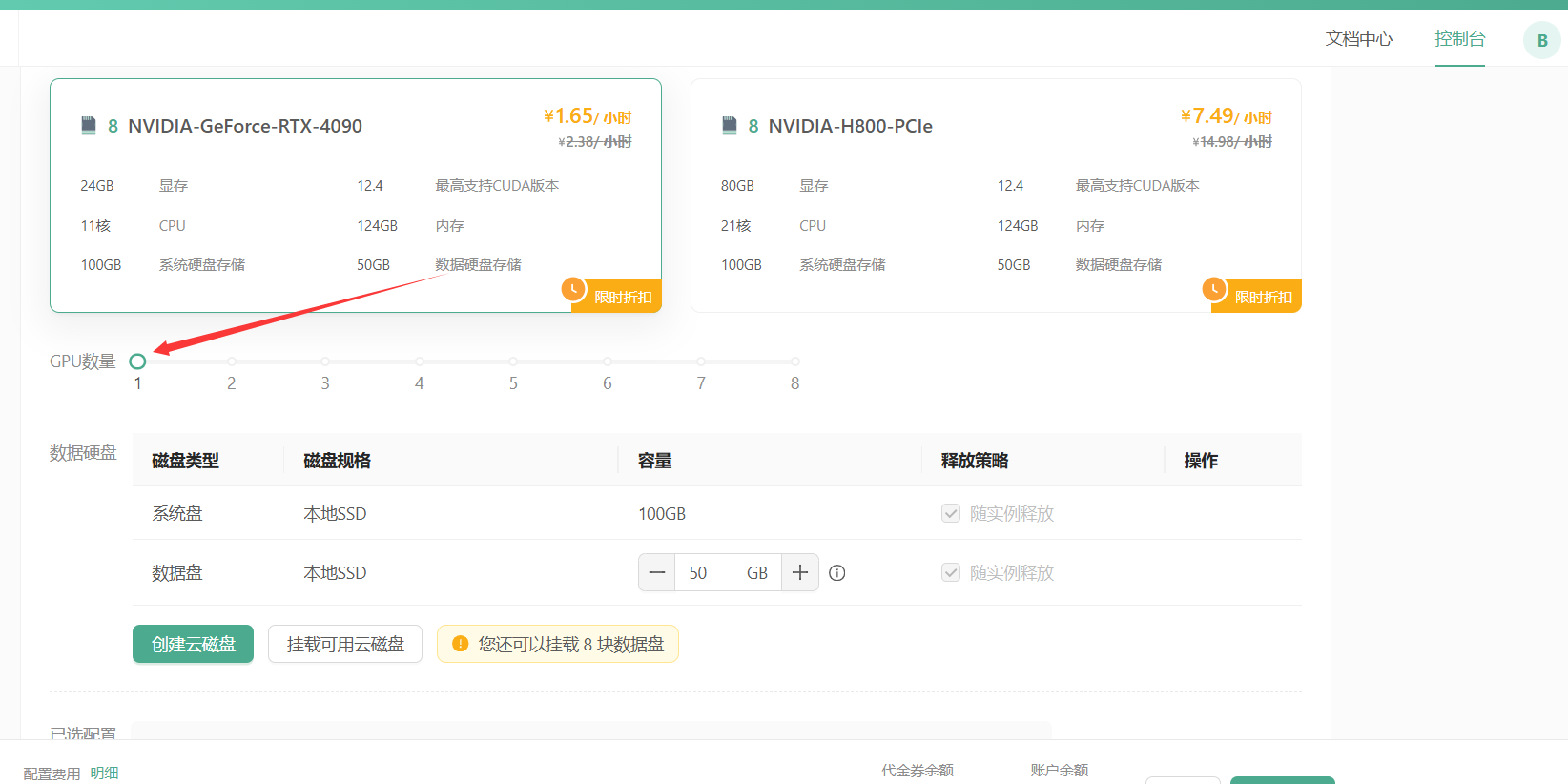
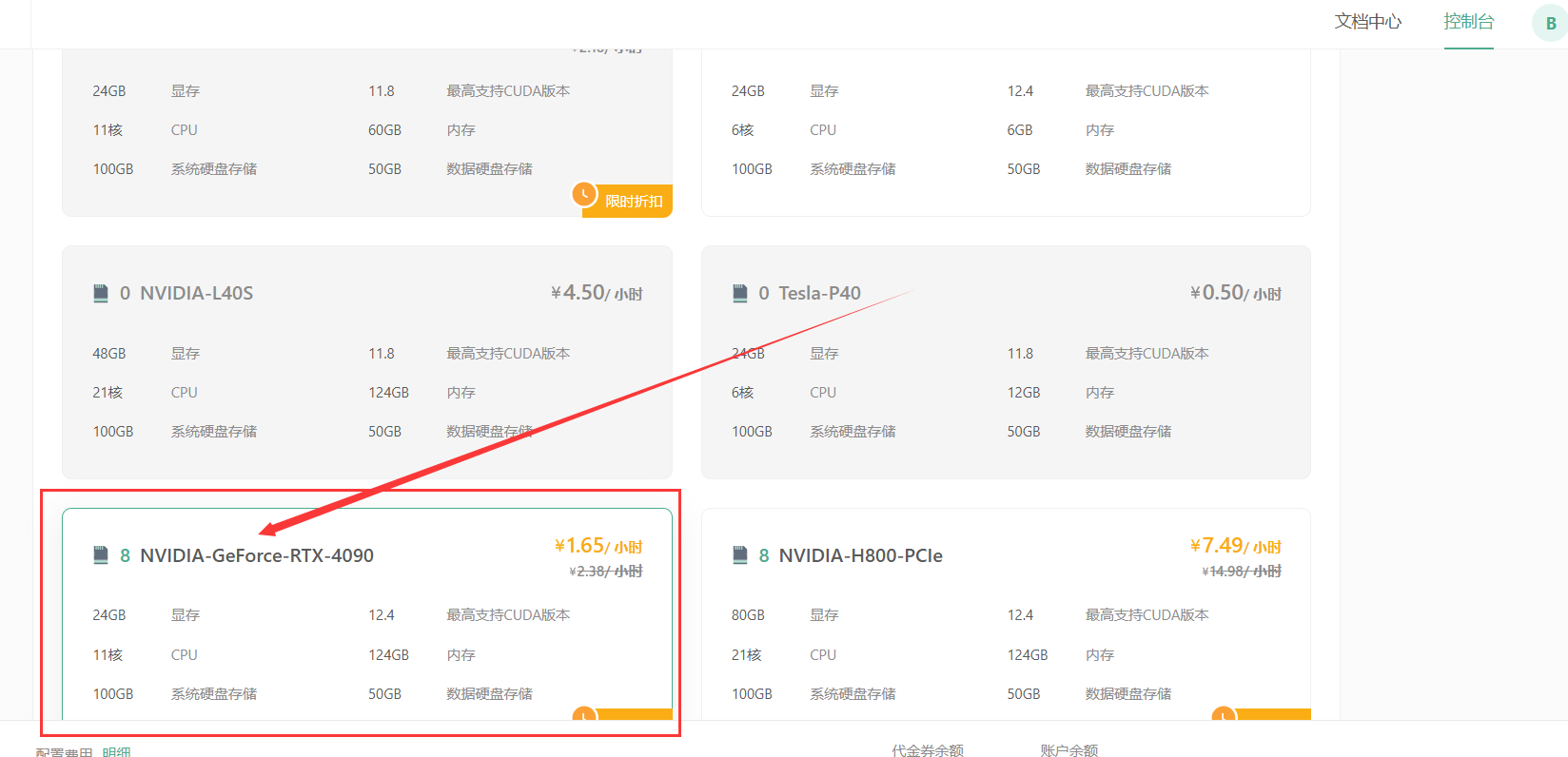
其次选择GPU数量和需求的GPU型号,首次创建实例推荐选择:
- 按量付费–GPU数量1–NVIDIA-GeForc-RTX-4090,该配置为60GB内存,24GB的显存(本次测试的LLaMA3.1 8B 版本至少需要GPU显存16G)
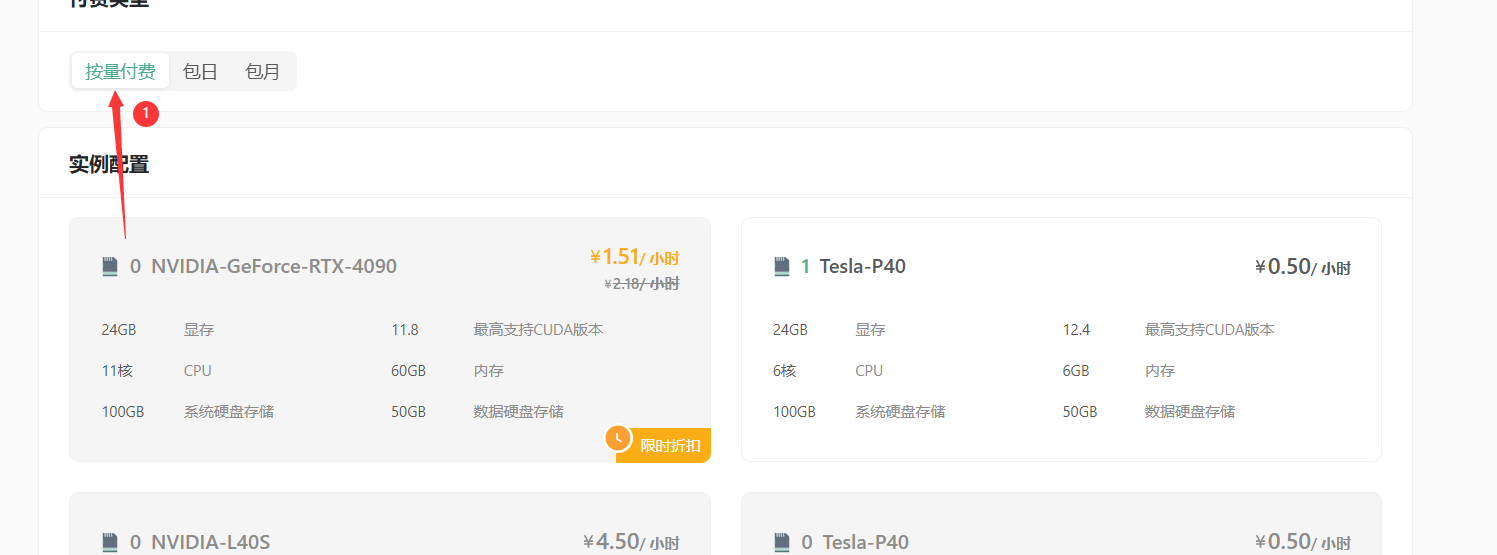
4.
-
接下来配置数据硬盘的大小。每个实例默认附带了50GB的数据硬盘,首次创建可以就选择默认大小50GB。
注意: 如果您通过官方预制方式下载模型,建议扩容至60GB。
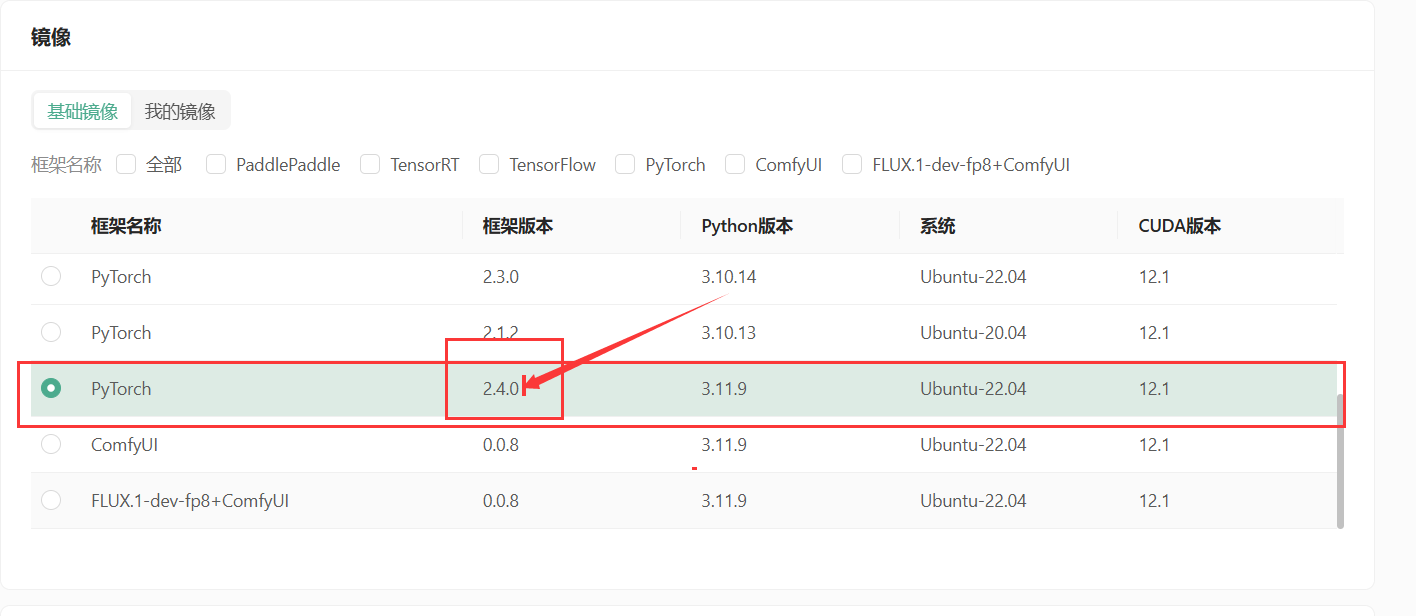
- 继续选择安装的镜像,选择PyTorch 2.4.0。
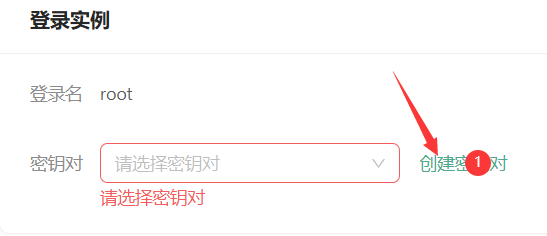
- 为保证安全登录,创建密钥对,输入自定义的名称,然后选择自动创建并将创建好的私钥保存的自己电脑中并将后缀改为.pem,以便后续本地连接使用。

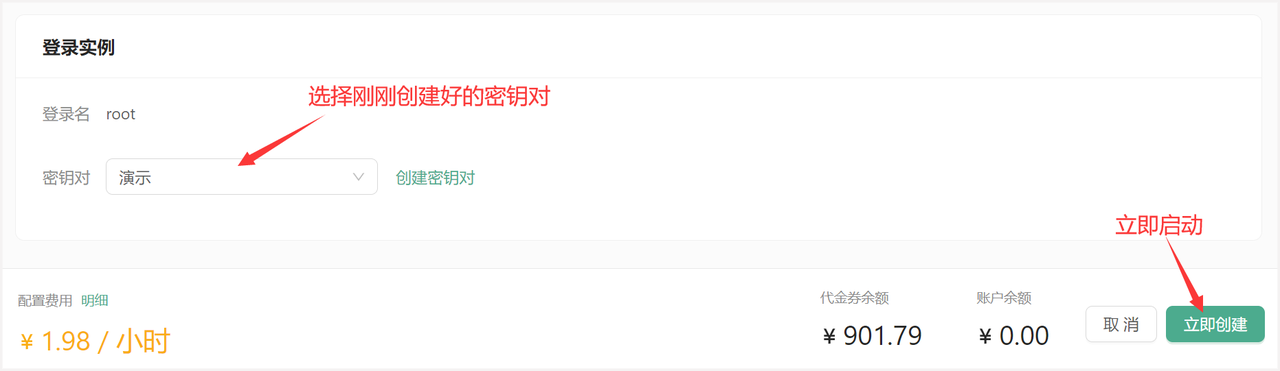
- 创建好密钥对后,选择刚刚创建好的密钥对,并点击立即创建,等待一段时间后即可启动成功!
例如我创建的时“BaiLetian”。

点击立即创建:
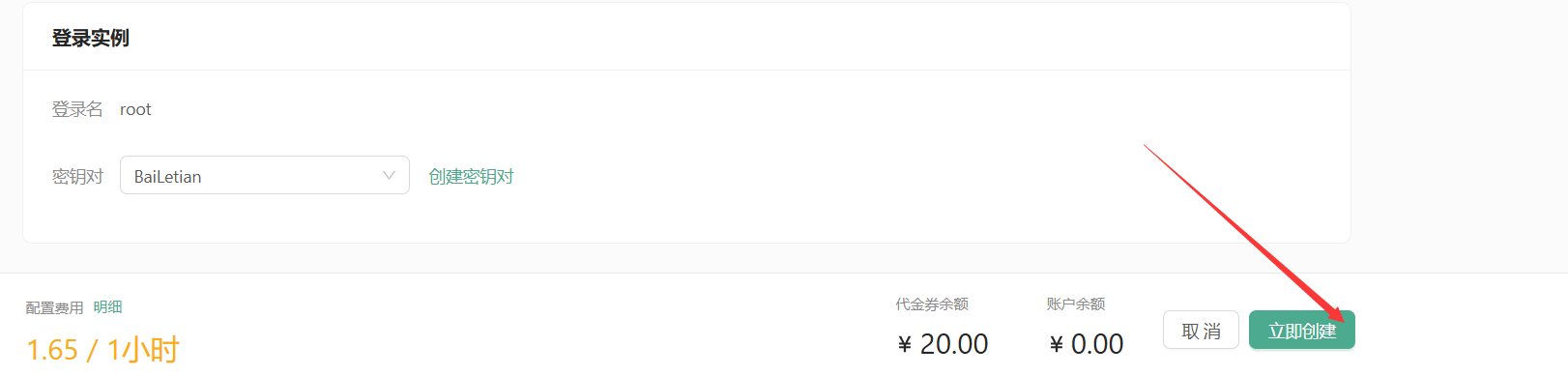
登录实例
1. 等待实例创建成功,在 GPU云实例 中查看实例信息:
JupyterLab 界面:
- 登录后一般会在 /root/workspace 目录下,服务器各个路径具体意义如下:
/:系统盘,替换镜像,重置系统时系统盘数据都会重置。/root/workspace:数据盘,支持扩容,保存镜像时此处数据不会重置。/root/shared-storage:共享文件存储,可跨实例存储。
SSH登录
SSH登录一般需要以下 4 个信息:- 用户名:
<font style="color:rgb(60, 60, 67);">root</font>; - 远程主机域名或IP(这里使用host域名):实例页面获取;
- 端口号:实例页面获取;
- 登录密码或密钥(这里使用密钥):前面创建实例时保存到本地的密钥。
在实例页面获取主机host和端口号:

复制结果类似如下:
ssh -p 31729 root@gpu-s277r6fyqd.ssh.damodel.com
//gpu-s277r6fyqd.ssh.damodel.com 即主机host,31729 为端口号。
部署LLama3.1
1. 我们使用 `conda` 管理环境,DAMODEL示例已经默认安装了 `conda 24.5.0` ,直接创建环境即可:
conda create -n llama3 python=3.12
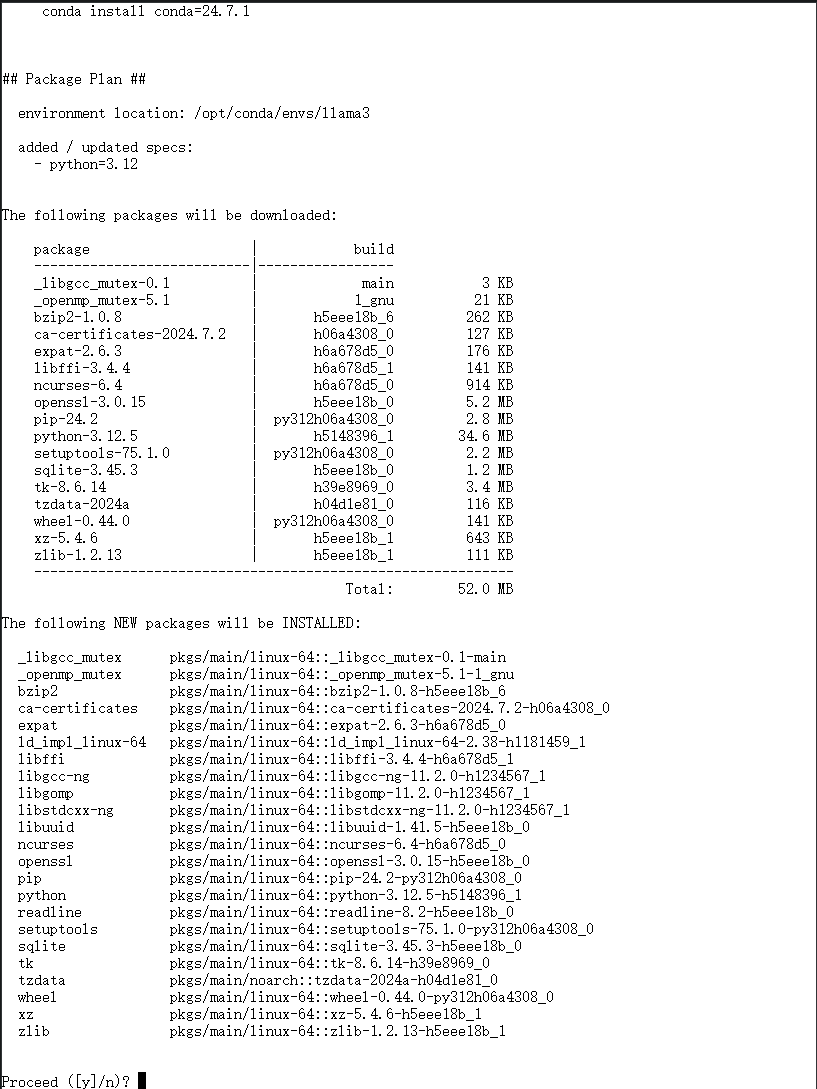
- 环境创建好后,使用如下命令切换到新创建的环境:
conda activate llama3
- 继续安装部署LLama3.1需要的依赖:
pip install langchain==0.1.15
pip install streamlit==1.36.0
pip install transformers==4.44.0
pip install accelerate==0.32.1
- 安装好后,下载
Llama-3.1-8B模型,平台已预制Llama-3.1-8B-Instruct模型,执行以下命令即可内网高速下载:
wget http://file.s3/damodel-openfile/Llama3/Llama-3.1-8B-Instruct.tar
- 下载完成后解压缩
/Llama-3.1-8B-Instruct.tar
tar -xf Llama-3.1-8B-Instruct.tar







