LuaJIT源码分析(六)语法分析
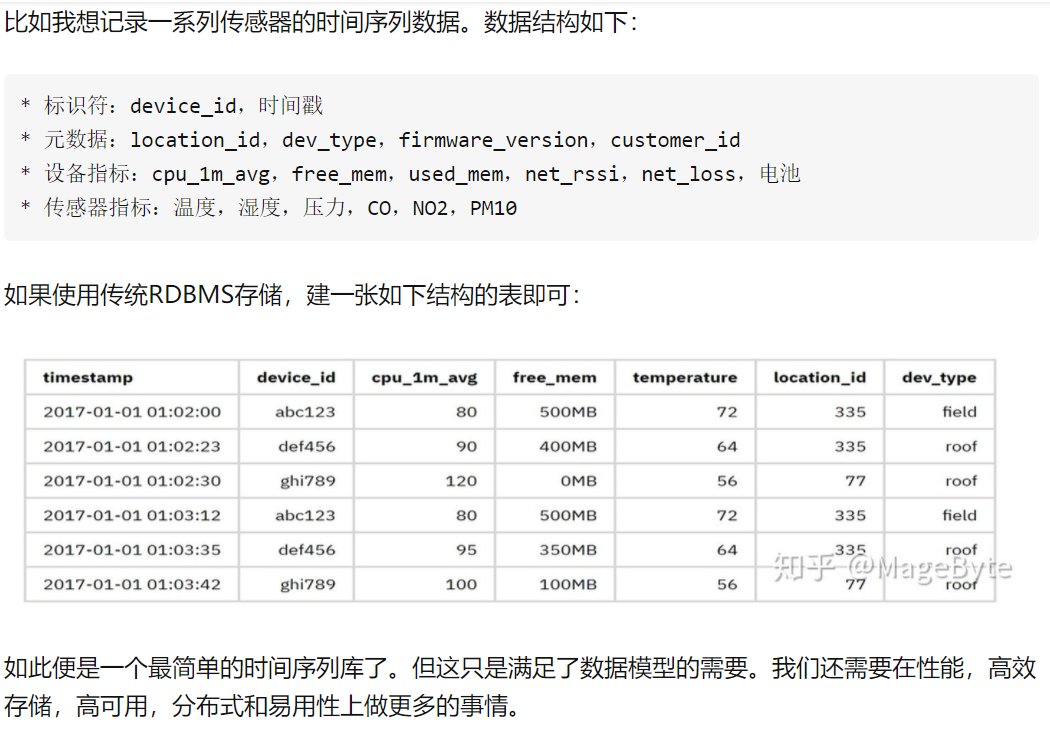
lua虚拟机在编译lua脚本时,在对源代码进行词法分析之后,还需要进行语法分析,把源代码翻译成字节码。lua 5.1完整的语法描述如下:

LuaJIT采用的是递归下降的解析方式,也就是自顶向下开始解析。LuaJIT的语法分析过程并不会显式地生成语法树,而是直接生成对应的字节码。上述EBNF描述中,{}包住的部分表示可以出现0次或者多次,[]包住的部分表示可以出现0次或者1次,大写字母开头(如Name,String,Number)和字体加粗的部分表示lua词法分析的token,它们不能继续用子表达式来进行描述。
通过语法描述,我们可以知道,lua代码是以chunk为单位组成的,chunk又是由若干语句(statement)组成的,statement又分为普通的statement和最后结尾的last statement组成。所谓的last statement,就是看是否包含return或者break关键字。也就是说,如果在解析chunk的时候,看到了return或者break,则说明chunk要结束了。但是last statement是可选的,如果last statement不存在的情况下,又要如何判断chunk是否结束呢?通过观察statement的规则,可以发现chunk只能以关键字end,else,elseif或者until结尾。LuaJIT解析chunk的代码如下:
// lj_parse.c
/* A chunk is a list of statements optionally separated by semicolons. */
static void parse_chunk(LexState *ls)
{int islast = 0;synlevel_begin(ls);while (!islast && !parse_isend(ls->tok)) {islast = parse_stmt(ls);lex_opt(ls, ';');lj_assertLS(ls->fs->framesize >= ls->fs->freereg &&ls->fs->freereg >= ls->fs->nactvar,"bad regalloc");ls->fs->freereg = ls->fs->nactvar; /* Free registers after each stmt. */}synlevel_end(ls);
}
其中parse_isend函数就是处理普通statement的情况:
// lj_parse.c
/* Check for end of block. */
static int parse_isend(LexToken tok)
{switch (tok) {case TK_else: case TK_elseif: case TK_end: case TK_until: case TK_eof:return 1;default:return 0;}
}
parse_stmt函数负责解析所有的statement,如果是last statement返回1。
/* Parse a statement. Returns 1 if it must be the last one in a chunk. */
static int parse_stmt(LexState *ls)
{BCLine line = ls->linenumber;switch (ls->tok) {case TK_if:parse_if(ls, line);break;case TK_while:parse_while(ls, line);break;case TK_do:lj_lex_next(ls);parse_block(ls);lex_match(ls, TK_end, TK_do, line);break;case TK_for:parse_for(ls, line);break;case TK_repeat:parse_repeat(ls, line);break;case TK_function:parse_func(ls, line);break;case TK_local:lj_lex_next(ls);parse_local(ls);break;case TK_return:parse_return(ls);return 1; /* Must be last. */case TK_break:lj_lex_next(ls);parse_break(ls);return !LJ_52; /* Must be last in Lua 5.1. *//* fallthrough */default:parse_call_assign(ls);break;}return 0;
}
lua5.1的语法总共支持13种statement,通过当前token,就可以把大部分statement区分开,例如上述的代码,就把statement划分为了9种情况分别处理。可以看到,除了for,local,以及赋值函数调用statement之外,其他的statement通过当前的token就能区分。我们以if语句为例,来看一下一般的解析过程:

// lj_parse.c
/* Parse 'if' statement. */
static void parse_if(LexState *ls, BCLine line)
{FuncState *fs = ls->fs;BCPos flist;BCPos escapelist = NO_JMP;flist = parse_then(ls);while (ls->tok == TK_elseif) { /* Parse multiple 'elseif' blocks. */jmp_append(fs, &escapelist, bcemit_jmp(fs));jmp_tohere(fs, flist);flist = parse_then(ls);}if (ls->tok == TK_else) { /* Parse optional 'else' block. */jmp_append(fs, &escapelist, bcemit_jmp(fs));jmp_tohere(fs, flist);lj_lex_next(ls); /* Skip 'else'. */parse_block(ls);} else {jmp_append(fs, &escapelist, flist);}jmp_tohere(fs, escapelist);lex_match(ls, TK_end, TK_if, line);
}
LuaJIT是语法分析和代码生成一起进行的,因此这里包含了一些生成代码的逻辑,这里我们暂时先忽略。可以看到解析if语句的主逻辑并不复杂,首先解析第一个if和then,然后再不断地尝试解析elseif,最后再去解析可选的else。解析条件表达式和then之后的block的逻辑位于parse_then这个函数:
// lj_parse.c
/* Parse condition and 'then' block. */
static BCPos parse_then(LexState *ls)
{BCPos condexit;lj_lex_next(ls); /* Skip 'if' or 'elseif'. */condexit = expr_cond(ls);lex_check(ls, TK_then);parse_block(ls);return condexit;
}
接下来看一下稍微麻烦一点的for语句。它需要再多看一个token,如果token为赋值运算符=,说明是数值for语句,否则是通用for语句,for的语法图如下:

// lj_parse.c
/* Parse 'for' statement. */
static void parse_for(LexState *ls, BCLine line)
{FuncState *fs = ls->fs;GCstr *varname;FuncScope bl;fscope_begin(fs, &bl, FSCOPE_LOOP);lj_lex_next(ls); /* Skip 'for'. */varname = lex_str(ls); /* Get first variable name. */if (ls->tok == '=')parse_for_num(ls, varname, line);else if (ls->tok == ',' || ls->tok == TK_in)parse_for_iter(ls, varname);elseerr_syntax(ls, LJ_ERR_XFOR);lex_match(ls, TK_end, TK_for, line);fscope_end(fs); /* Resolve break list. */
}
同样稍微麻烦一点的还有local语句。它也需要前瞻一个token,判断到底是函数声明还是变量声明。

// lj_parse.c
/* Parse 'local' statement. */
static void parse_local(LexState *ls)
{if (lex_opt(ls, TK_function)) { /* Local function declaration. */ExpDesc v, b;FuncState *fs = ls->fs;var_new(ls, 0, lex_str(ls));expr_init(&v, VLOCAL, fs->freereg);v.u.s.aux = fs->varmap[fs->freereg];bcreg_reserve(fs, 1);var_add(ls, 1);parse_body(ls, &b, 0, ls->linenumber);/* bcemit_store(fs, &v, &b) without setting VSTACK_VAR_RW. */expr_free(fs, &b);expr_toreg(fs, &b, v.u.s.info);/* The upvalue is in scope, but the local is only valid after the store. */var_get(ls, fs, fs->nactvar - 1).startpc = fs->pc;} else { /* Local variable declaration. */ExpDesc e;BCReg nexps, nvars = 0;do { /* Collect LHS. */var_new(ls, nvars++, lex_str(ls));} while (lex_opt(ls, ','));if (lex_opt(ls, '=')) { /* Optional RHS. */nexps = expr_list(ls, &e);} else { /* Or implicitly set to nil. */e.k = VVOID;nexps = 0;}assign_adjust(ls, nvars, nexps, &e);var_add(ls, nvars);}
}
最后就是最麻烦的赋值函数调用statement,它们无法直接通过前瞻token就能判断,因为前缀表达式(prefixexp)可以一直递归无限长。不过通过分析语法规则可以发现,前缀表达式再怎么长,最基本的形式一定是Name或者(exp)。通过解析最基本的形式,就可以一直往外扩展,直到解析完成完整的前缀表达式。前缀表达式的语法图如下:

然后,如果下一个token是(,{或者String,就说明下面要解析的是args,也就是当前的statement是函数调用(functioncall);如果下一个token是:,则说明当前statement是带self语法糖的函数调用。除此之外的情况,就都按赋值语句的规则进行解析。
// lj_parse.c/* Parse call statement or assignment. */
static void parse_call_assign(LexState *ls)
{FuncState *fs = ls->fs;LHSVarList vl;expr_primary(ls, &vl.v);if (vl.v.k == VCALL) { /* Function call statement. */setbc_b(bcptr(fs, &vl.v), 1); /* No results. */} else { /* Start of an assignment. */vl.prev = NULL;parse_assignment(ls, &vl, 1);}
}/* Parse primary expression. */
static void expr_primary(LexState *ls, ExpDesc *v)
{FuncState *fs = ls->fs;/* Parse prefix expression. */if (ls->tok == '(') {BCLine line = ls->linenumber;lj_lex_next(ls);expr(ls, v);lex_match(ls, ')', '(', line);expr_discharge(ls->fs, v);} else if (ls->tok == TK_name || (!LJ_52 && ls->tok == TK_goto)) {var_lookup(ls, v);} else {err_syntax(ls, LJ_ERR_XSYMBOL);}for (;;) { /* Parse multiple expression suffixes. */if (ls->tok == '.') {expr_field(ls, v);} else if (ls->tok == '[') {ExpDesc key;expr_toanyreg(fs, v);expr_bracket(ls, &key);expr_index(fs, v, &key);} else if (ls->tok == ':') {ExpDesc key;lj_lex_next(ls);expr_str(ls, &key);bcemit_method(fs, v, &key);parse_args(ls, v);} else if (ls->tok == '(' || ls->tok == TK_string || ls->tok == '{') {expr_tonextreg(fs, v);if (ls->fr2) bcreg_reserve(fs, 1);parse_args(ls, v);} else {break;}}
}
到目前为止,statement层面算是分析完了,那么再往下走,就到了表达式(exp)层面了。解析表达式可能会遇到一元或是二元运算符,然后就会涉及到运算符的优先级和结合性。lua 5.1中的运算符从低到高的优先级如下:

其中,只有拼接..和乘方^是右结合性,其他均为左结合性。LuaJIT关于运算符优先级的定义如下:
// lj_parse.c
/* Priorities for each binary operator. ORDER OPR. */
static const struct {uint8_t left; /* Left priority. */uint8_t right; /* Right priority. */
} priority[] = {{6,6}, {6,6}, {7,7}, {7,7}, {7,7}, /* ADD SUB MUL DIV MOD */{10,9}, {5,4}, /* POW CONCAT (right associative) */{3,3}, {3,3}, /* EQ NE */{3,3}, {3,3}, {3,3}, {3,3}, /* LT GE GT LE */{2,2}, {1,1} /* AND OR */
};#define UNARY_PRIORITY 8 /* Priority for unary operators. */
可以看到,两个右结合性的运算符left字段均大于right字段。所谓的left和right,应当是指操作数是在运算符的左边还是右边,例如a … b … c,b受两个..运算符影响,但b在第一个运算符的右边(优先级为4),第二个运算符的左边(优先级为5),所以b要先跟第二个运算符进行计算。通过这种方式就能比较容易地实现结合性的逻辑。
同时,LuaJIT为了避免回溯,在解析二元运算符表达式时,每次只解析一个运算符,然后就开始递归,让子函数就解析剩下的表达式。例如exp1 op1 exp2 op2 exp3,第一次只解析exp1和op1,子函数负责解析exp2 op2 exp3。如果op2的左优先级大于op1的右优先级(这里就把结合性和优先级统一起来了),说明就是要先解析子函数;反之,子函数只会解析exp2 op2这一部分,把解析结果记录下来后直接返回,表示实际要解析的是exp1 op1 exp2,并且解析完之后下一个运算符是op2。这样做就能保证词法分析器一次扫描即可,无需回溯。
// lj_parse.c
/* Parse binary expressions with priority higher than the limit. */
static BinOpr expr_binop(LexState *ls, ExpDesc *v, uint32_t limit)
{BinOpr op;synlevel_begin(ls);expr_unop(ls, v);op = token2binop(ls->tok);while (op != OPR_NOBINOPR && priority[op].left > limit) {ExpDesc v2;BinOpr nextop;lj_lex_next(ls);bcemit_binop_left(ls->fs, op, v);/* Parse binary expression with higher priority. */nextop = expr_binop(ls, &v2, priority[op].right);bcemit_binop(ls->fs, op, v, &v2);op = nextop;}synlevel_end(ls);return op; /* Return unconsumed binary operator (if any). */
}
另外,一元运算符表达式,本质上也可以被认为是二元运算符表达式的特殊形式。例如-exp1 op exp2可能是exp1 op exp2之后的结果再取负,也可能是-exp1和exp2进行计算。
// lj_parse.c
/* Parse unary expression. */
static void expr_unop(LexState *ls, ExpDesc *v)
{BCOp op;if (ls->tok == TK_not) {op = BC_NOT;} else if (ls->tok == '-') {op = BC_UNM;} else if (ls->tok == '#') {op = BC_LEN;} else {expr_simple(ls, v);return;}lj_lex_next(ls);expr_binop(ls, v, UNARY_PRIORITY);bcemit_unop(ls->fs, op, v);
}
除了运算符表达式之外,剩余比较复杂的就是前缀表达式,表构造器表达式,和函数定义表达式了。前缀表达式我们前面已经分析过了,函数定义表达式和前面函数的statement类似。表构造器表达式(tableconstructor)的语法图如下:

Reference
[1] The Complete Syntax of Lua
[2] Railroad Diagram Generator