简介
今年V3/N3已经发布,但考虑到没有公布太多的细节,我依据手册在“ARM发布新一代高性能处理器”一文中对微架构有阐述,本文主要简单分析ARM V2的一些微架构内容。
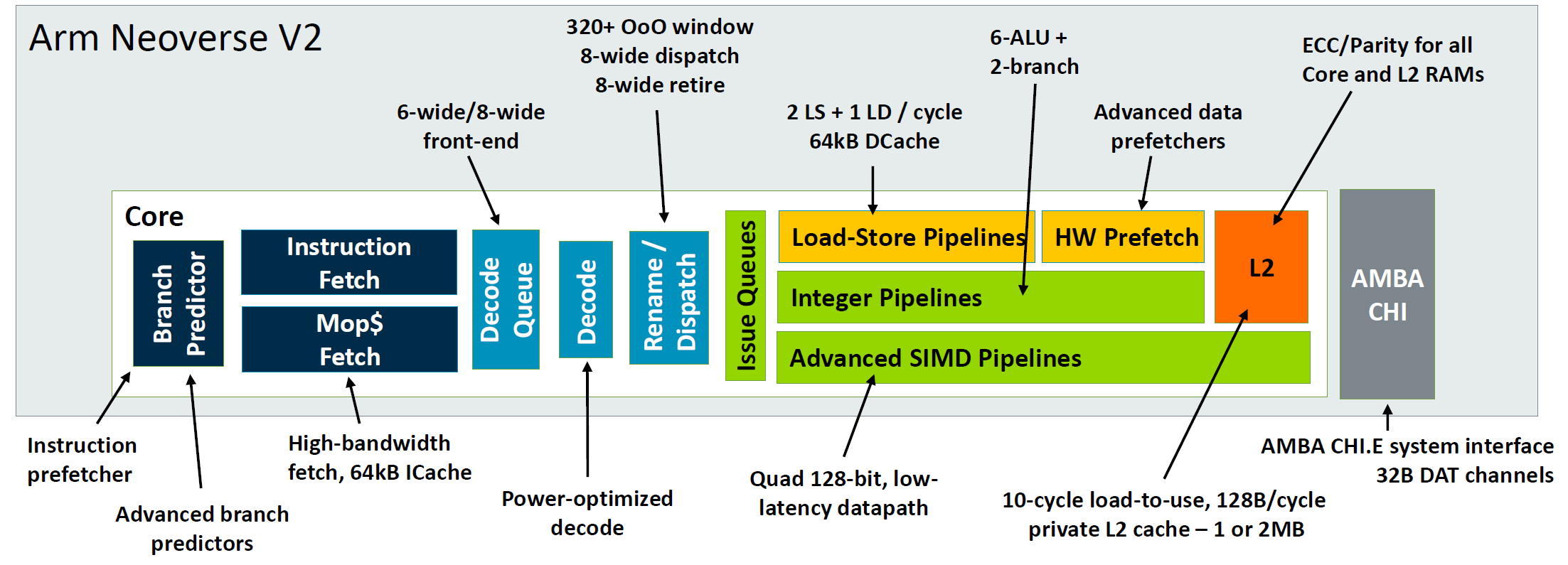
IFU
1、每个cycle预测两个分支,这个特性在服务器系列中是N2/V2刚有的,实现难度还是挺大的,复杂度相对比较高,需要平衡的东西比较多。
2、实现了uOp Cache,对于RISC指令集而言,这个选择不是很常见,尽管在N2/V2系列刚实现这个特性,但实际移动端早在A77就开始采用这个微架构,今年发布的V3/N3放弃了uOp Cache这个设计。可能是考虑到功耗问题,再加上优化了ICache和其它IFU方面的特性提升比较可观,对比下uOp Cache收益没有牺牲的面积和功耗大,所以放弃了。
3、增加了TAGE预测器以及BTB的容量,这就属于常规的升级了,基本是一些参数化的升级,更细节的算法优化不是很清楚。
4、给间接指令设计了单独的预测器,这里有历史遗留问题,由于N和V系列实际也是A系列演变而来,出于经典的A76微架构,一开始移动端和服务器端区分不明显,所以之前间接预测器和移动端一样都是混合的。而服务器端由于间接指令占比相对较多,移动端微架构是确定是间接指令之后再查找IBTB的设计方案(为了节约面积功耗)可能不那么适合服务器端了,即使是解耦设计,也不太容易覆盖住间接指令预测带来的延迟。
6、取指队列也从原来的16entry升级到现在的32entry。
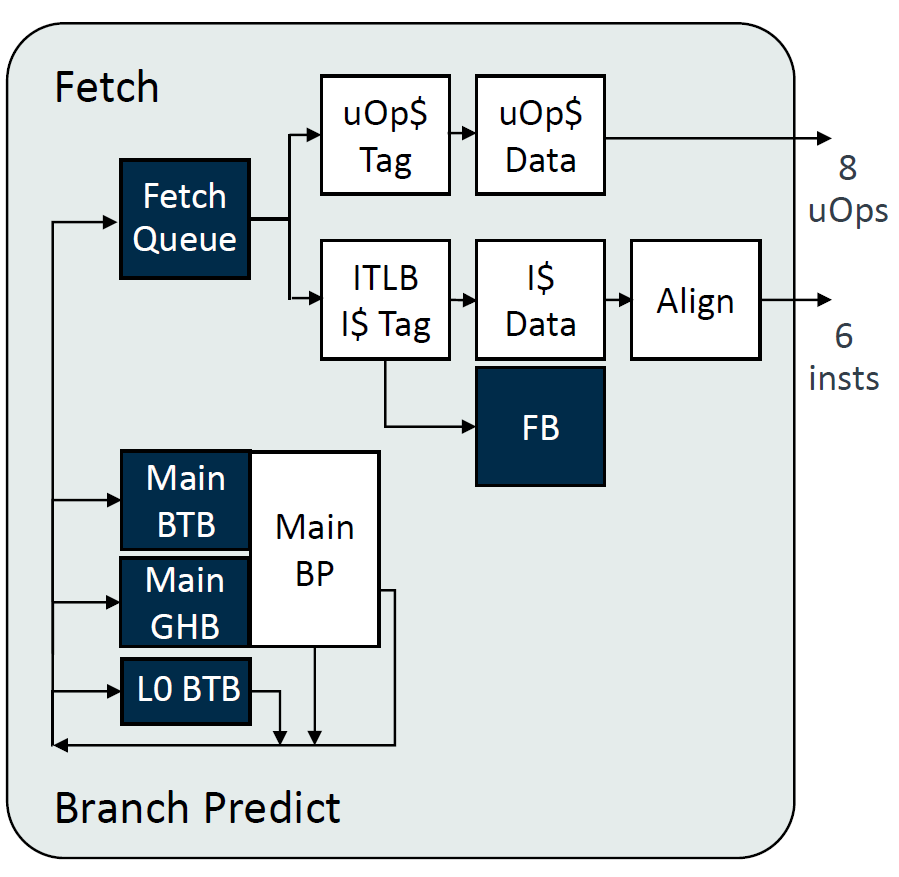
Decode/Rename/Dispatch
Decode/Rename/Dispatch细节没有更多的信息,decode宽度提升到6,由于uOp Cache的存在,命中uOp Cache可以低延迟的发出8 uOps。Decode Queueyou由16提升到32,增加了Rename Checkpoint以及优化了Rename Rebuild。
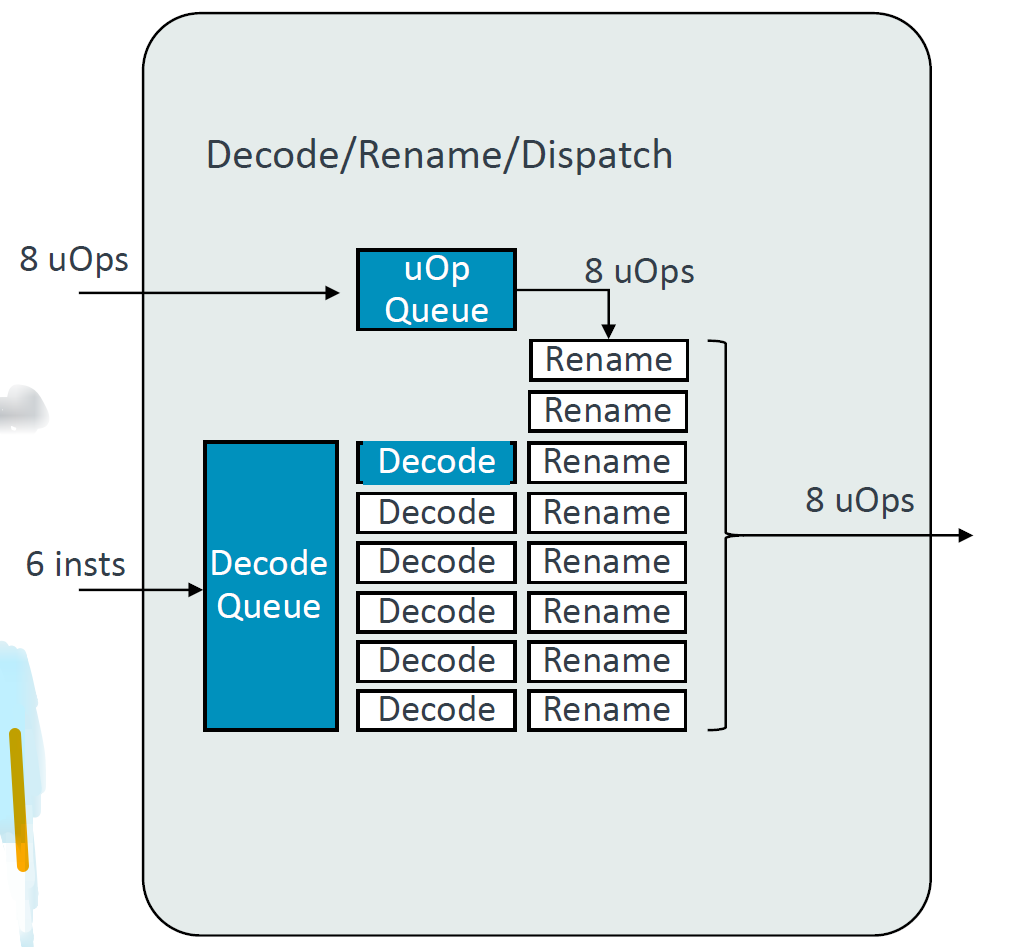
Issue/Execute
增加了2个单周期ALUs,增加Issue Queues,SX/MX从20增到22entries,VX从20增加到28entries等等。
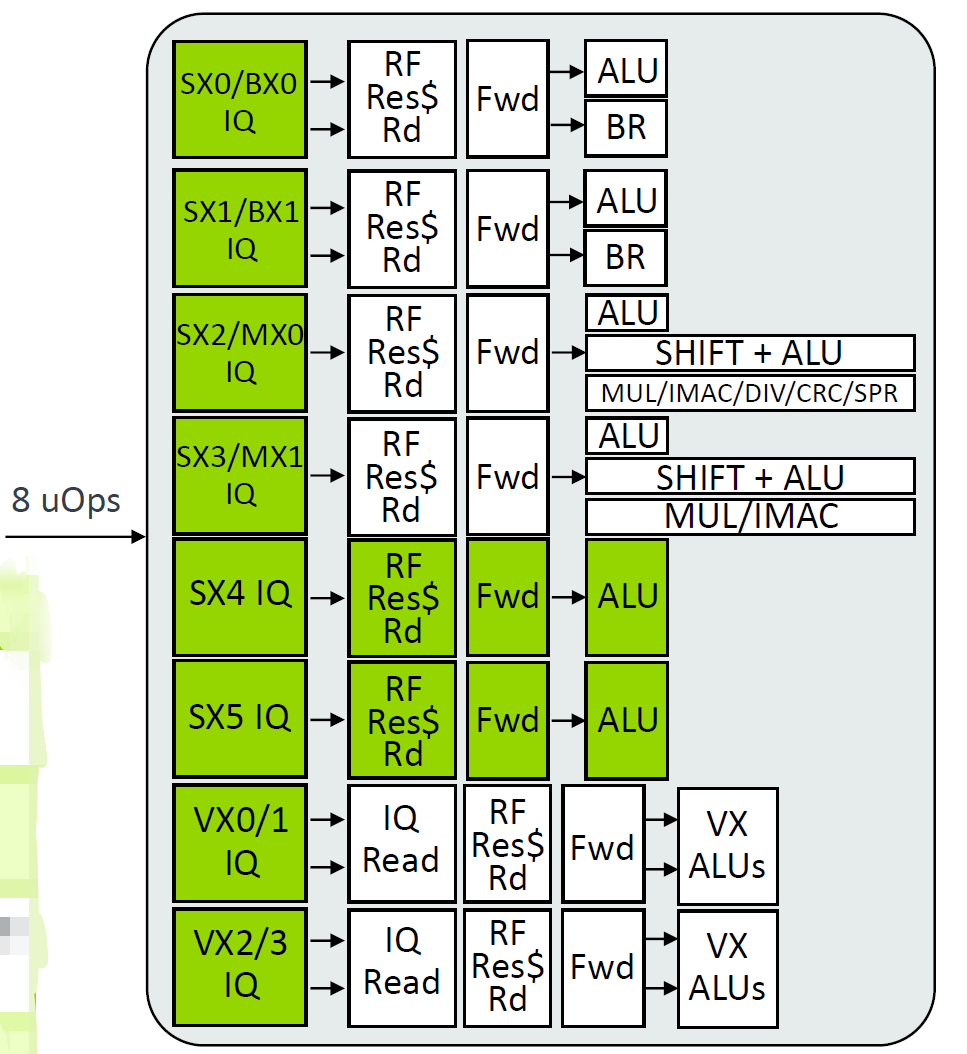
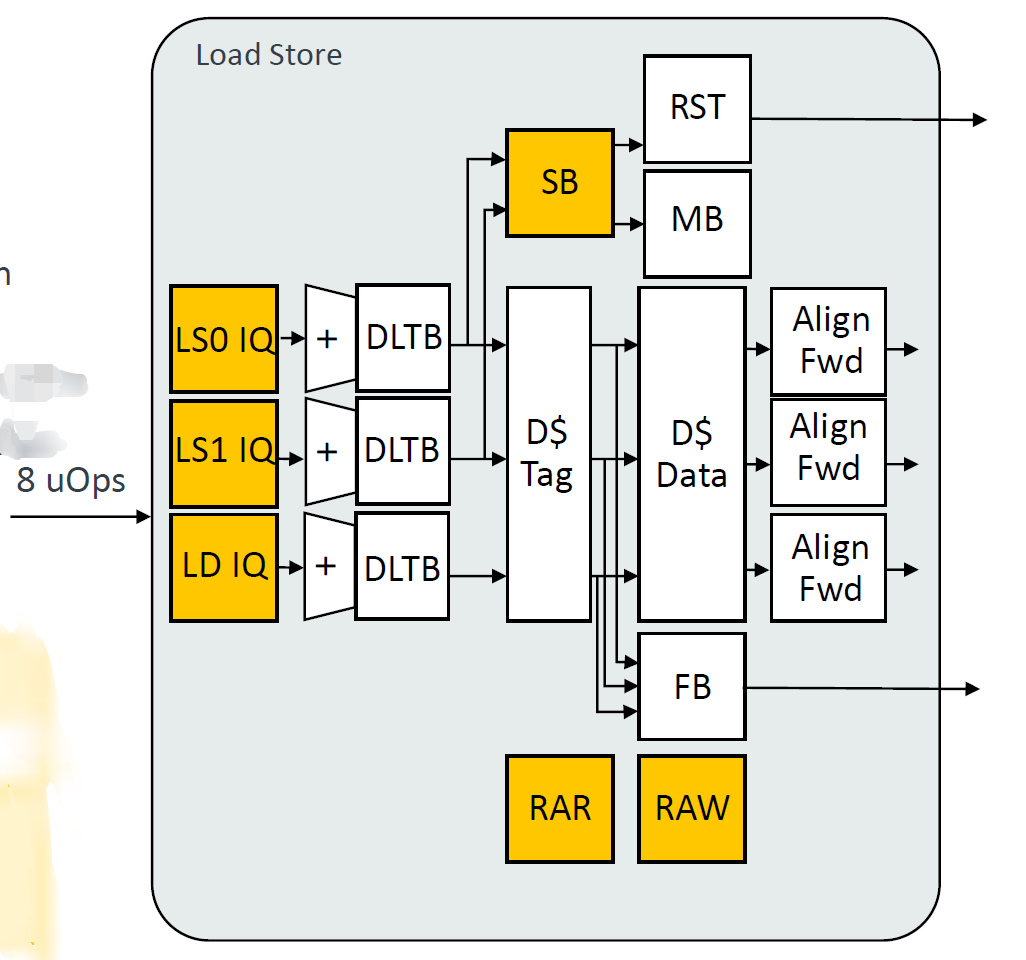
LSU
1、增加DTLB数量至48entry。
2、DCache将PLRU替换算法改为RRIP,ARM常用的替换算法,NRU/PLRU/RRIP,L1 Cache使用PLRU更多,更重视L1 Cache的时候会牺牲更多资源在替换算法上。现在论文常讲的更“细粒度”的替换算法,在实际工程中见的更频繁了。例如初始化区分历史,将数据或者指令视作不等价等。简单讲,有一种观点是不全部强调命中率,更强调整体的性能,举个简单的例子,有些数据不命中,对其miss系统损失的代价更高,即使依据频繁访问原则“它”应该被踢掉,但由于“它”地位更高,所以不将“它”替换掉。或者有观点,识别数据本身的特性以及访问频率等情况综合去考量替换问题,这无疑会消耗更多的资源,对于路数更多的L2可能使用类似“细粒度”的替换算法收益更高。但现在ARM L1 Cache也开始逐步使用相对复杂的替换算法。
其它就是一些常规的参数级别的升级,例如2LS,1LD,一些buffer深度给出了升级。
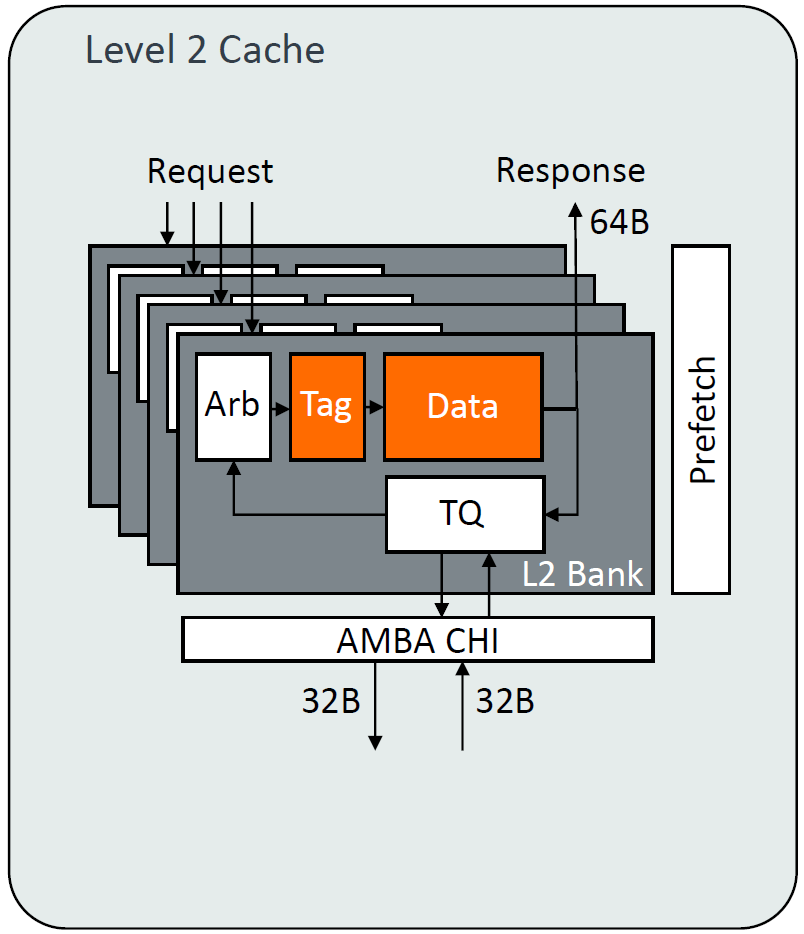
L2
8路,2MB,和1MB的延迟一致(比较前版本),替换算法使用6-state RRIP。单个bank每2cycle读或写64B,共计4bank。
总结
arm的微架构给我的感觉是细节特别多,很多微小的特性都会抓取去优化,这是国内很多公司不具备的,国际一线的CPU公司,微架构方向的优化每年提升都放缓了,更多的是面向特定场景的优化,反而是工艺的提升以及SoC系统级微架构的提升对芯片系统的影响更大了。当然国内对CPU微架构的设计依然相对落后一些,即使在“参数上”追上了国际水平,并且抛开一些生态问题,实际“面积”“功耗”以及常规情况下的性能依旧有不少的提升空间(国内有些CPU性能出于宣传的角度,不少是在特定情况下测试的),当然以上的总结只是亦安个人的观点,很多是基于自己的感觉,大家见仁见智。



![[数据集][目标检测]街头摊贩识别检测数据集VOC+YOLO格式758张1类别](https://i-blog.csdnimg.cn/direct/661724e63a6b435d8806320704b39ea8.png)

