前言
StarRocks存算分离表中,垃圾回收是为了删除那些无用的历史版本数据,从而节约存储空间。考虑到对象存储按照存储容量收费,因此,节约存储空间对于降本增效尤为必要。
在系统运行过程中,有以下几种情况可能会需要删除对象存储上的数据:
- 用户手动执行了删除库、表、分区等命令,如执行了 drop table、drop database 以及 drop partition 等命令
- 随着系统内 Compaction 任务不断进行,合并之前的数据文件可以被安全回收
目前在 StarRocks 的存算分离表存储在对象存储上的文件类型包含如下几种:
- Segment 文件:导入过程中会产生数据文件,存算分离的数据文件格式与存算一体保持一致
- Txn Log 文件:StarRocks 存算分离实现中,每次导入或者 Compaction 都会产生一次事务,每个 Tablet 在数据写入的最后阶段都会产生一个 Txn Log 文件,记录本次导入新增的数据文件列表
- Tablet Meta 文件:StarRocks 每次导入或者 Compaction 都会产生全局唯一的版本。而 Tablet Meta 文件在事务提交阶段产生,存储 Tablet 特定版本的元数据信息,其中主要记录了该版本所有可见的数据文件名
本文旨在描述 StarRocks 存算分离表垃圾回收的原理,会针对上述两种数据清理场景分别描述其内部原理,帮助开发和运维人员能更好地理解并根据实际需要做出合适的配置,以在性能和成本方面取得平衡。
数据多版本技术
在介绍数据清理之前,我们有必要先介绍下目前 StarRocks 存算分离的数据多版本技术,以便更好地理解垃圾数据回收原理。
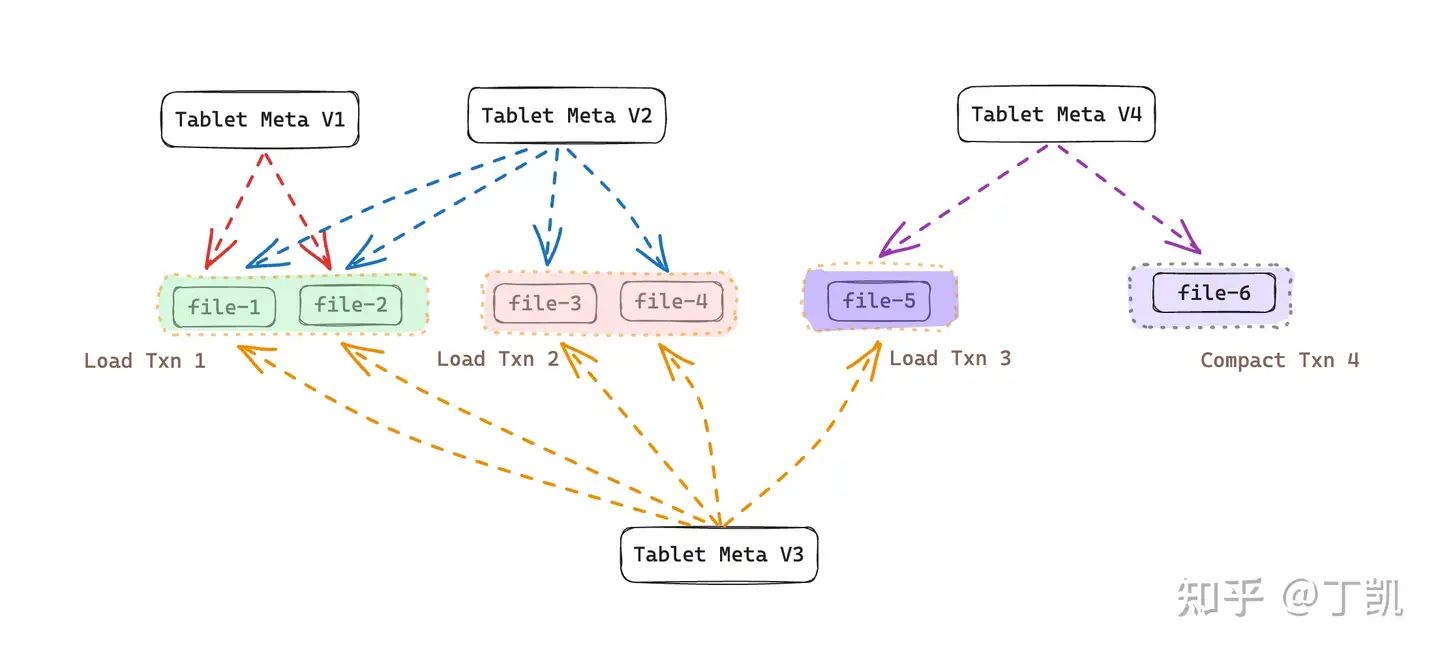
StarRocks 存算分离版本中,数据在对象存储上的组织结构如下图所示:
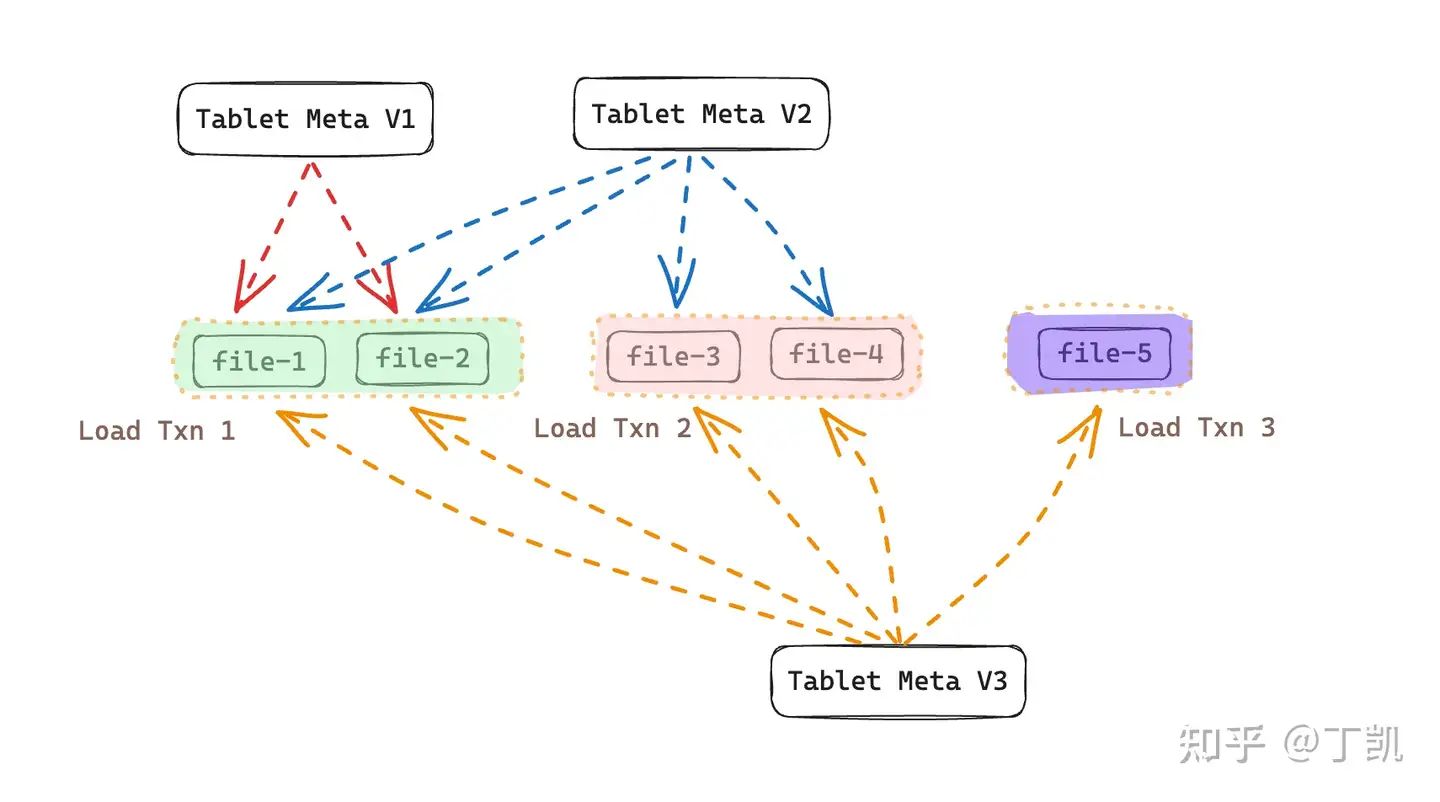
上图中共产生了三次数据导入事务,其中:
- Load Txn 1: 在事务数据写入阶段,生成了新数据文件 file 1 & file 2,该事务提交后生成了 Tablet Meta V1,其中记录该版本可见的文件列表为 {file-1, file-2}
- Load Txn 2: 在事务数据写入阶段,生成了新数据文件 file 3 & file 4。在提交时,根据前一个版本(即 Tablet Meta V1)然后加上本次导入事务生成的新数据文件(file-3 & file-4),生成了新的 Tablet Meta V2,因此,该版本可见的文件列表为 {file-1, file-2, file-3, file-4}
- Load Txn 3: 在事务写入阶段,产生了新数据文件 file 5。该事务提交时,根据前一个版本(即 Tablet Meta V2)然后加上本次导入事务生成的新数据文件(file-5),产生了新的 Tablet Meta V3,因此,该版本的可见文件列表为 {file-1, file-2, file-3, file-4, file-5}
除了用户导入事务产生了新的数据版本,在存算分离架构中,系统后台 Compaction 任务也会产生新数据版本。Compaction 的目的有二: 1). 将多个版本的小文件合并为大文件,减少查询时的随机 IO 次数,2). 消除重复数据记录,减少数据总量。
在存算分离表中,每次 Compaction 同样会产生一个全新的版本。依然以上面为例,假如在上面 Txn 3 之后新的事务 Txn 4 为一次 Compaction 任务,并且将 file1 ~ file4 这4个文件合并成为 file-6,那么该事务提交时,生成的新版本 Tablet Meta V4 内记录的文件列表为 {file-5, file-6}。
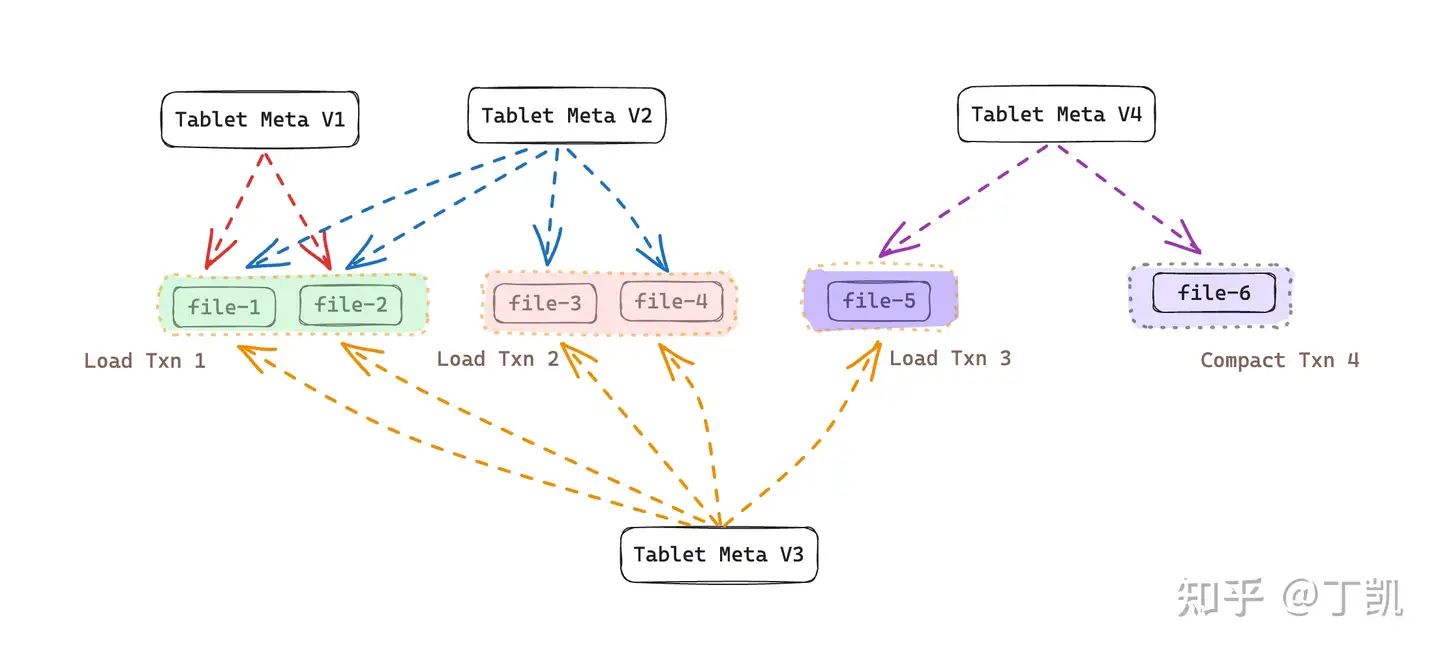
观察上例并思考可知,如果系统在运行过程中一直不会进行 Compaction。那么系统中的数据文永远也无法被删除。试想上例中我们即使将 Tablet Meta V1,Tablet Meta V2 文件删除,但我们无法删除 file-1、file-2、file-3 以及 file-4,因为这些文件依然被 Tablet Meta V3 所引用。
但有了数据合并(Compaction)后,情况就变得不一样了。上例中,由于发生了一次 Compaction(上图中的 Txn 4),将 file-1、file-2、file-3、file-4 合并生成了新文件 file-6 并生成了新的 Tablet Meta V4,由于 file-1 至 file-4 中的内容已经在 file-6 中存在,因而,一旦版本 V1、V2、V3 不再被访问,file-1、file-2、file-3、file-4 便可以被安全删除。此时的数据版本情况如下图所示:
因此,综合上面的讨论,我们可以发现,只有在 Compaction 完成后原始的数据文件方可被删除(但 Tablet Meta 文件的清理依赖其他规则)。
目前我们在 Tablet Meta 组织上采用了一种高效方法:
对于 Compaction 事务, 我们会在其产生的 Tablet Meta 中记录本次合并任务的输入文件列表,这样,下次我们在清理该 Tablet Meta 时即可安全删除这些输入文件。
仍然以上面为例,Compaction Txn 4 在生成的 Tablet Meta V4 中记录了本次合并任务的输入文件 file-1、file-2、file-3、file-4。这样,下次系统清理掉 Tablet Meta V4 之后,拿到这个文件列表,便可以安全删除。
但这种删除方式也依赖一个前提:即 Tablet Meta 按照版本顺序删除,不可乱序。试想一下,上面的例子中,我们在删除版本 V4 时必须确保 V3 已经被安全删除。否则,访问 V3 时就会发现 file-1 这些已经被删除了。
工程实现
本章节主要描述当前垃圾数据清理的工程实现原理。
FE 后台清理线程
当前存算分离表的垃圾回收任务以 Partition 为单位执行,由 FE 节点构建清理任务并交由 CN 节点执行。具体来说,FE 会同时为若干个活跃 Partition 创建 Vacuum 任务,然后下发至 CN 执行。
Leader FE 节点上存在后台 Vacuum 线程,周期性运行,每次运行时:
1. 筛选出当前需要执行 Vacuum 的 Partition
2. 为筛选出的 Partition 构造 Vacuum 任务,交由 FE 端线程池处理这些任务
3. FE 端线程池可同时执行若干任务(由参数控制),每个任务都会下发给 Partition 内 Tablet 所在的 BE 执行
在步骤 2 中构造的 Vacuum 任务中,最关键的参数有三:
minRetainVersion: 控制 CN 端执行时需要保留的最小版本号。FE 决定了某个分区可以最多保留多少个历史版本。避免 CN 执行时清理过猛,将历史版本清理过多,造成正在进行中的查询访问历史版本数据失败。
graceTimestamp: 控制多长时间内产生的 Tablet Meta 不会被清理,避免在高频导入场景下,刚刚产生的 Tablet Meta 被立即回收
minActiveTxnId: 用于回收 Txn Log 文件
FE 为需要 Vacuum 的 Partition 构造好 VacuumRequest 发往 CN 节点,接下来 CN 节点只需要负责执行任务即可
CN 执行垃圾回收
CN 只需要负责执行 FE 下发的 VacuumRequest 即可。目前 Vacuum 任务复用了 RELEASE_SNAPSHOT 线程池(该线程池在存算分离集群上无用,因而可直接复用)。由于该线程池工作线程数量较少(默认为5),这可能在一定程度上影响清理速度,需要特别注意。
清理 Tablet Meta 文件
清理 Tablet Meta 实际上主要是清理如下内容:
- Tablet Meta 文件(即从对象存储上删除特定版本的 Tablet Meta 文件)
- 如果该版本是由 Compaction 事务产生,便可以收集到 Compaction 所对应的输入 Segment 文件,以便接下来删除(参考上面的例子,删除 Tablet Meta V4 的时候可以获取可以删除的数据文件 file-1 ~ file-4)
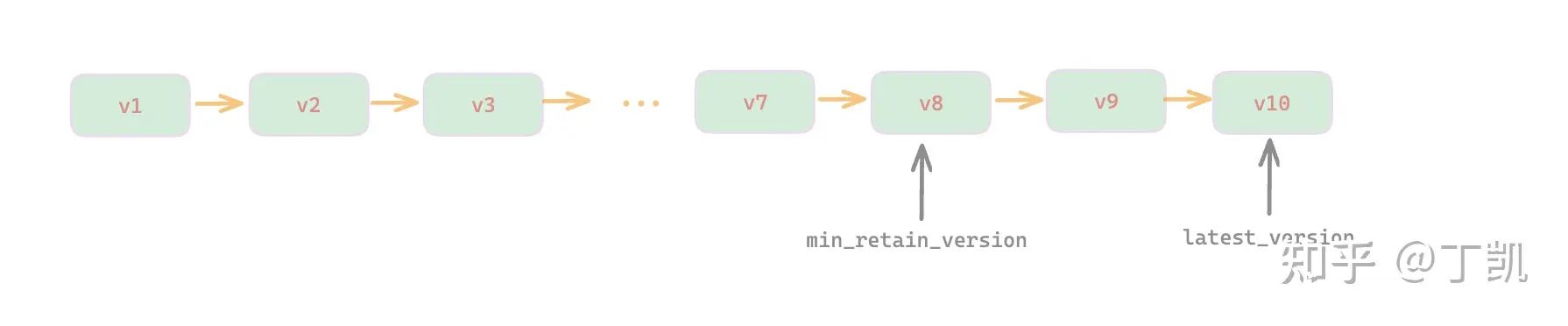
这里需要特别说明的一点是,对于某个特定 Tablet 的 Meta 文件的清理是往前回溯进行的。具体来说,FE 的 VacuumRequest 中记录了最大可回收版本号(min_retain_version),CN 节点处理时就从该版本开始逐步向前回溯。
例如下例中,假如最新的版本为 v10,且系统配置保留最近的3个版本,那么 min_retain_version 便是 v8,按照规则就是从 v7 开始向前回溯直到 v1。另外,在回溯时我们还会获取 Meta 文件的最后创建时间,如果没有超过一个特定的间隔(grace_timestamp),那也暂时不回收该 Tablet Meta 文件。
之所以采用这种前向回溯的方式的原因在于:
- 避免 list 所有 Meta 文件,因为 list object 调用在对象存储上效率非常低下
- 避免从前往后扫描时需要不断获取 Tablet 每个 Meta 文件的内容以获得 Compaction Input(假如 Meta 文件出现 cache miss,就会产生一次对象存储访问,效率低下)
不妨举个例子说明,如下图所示:
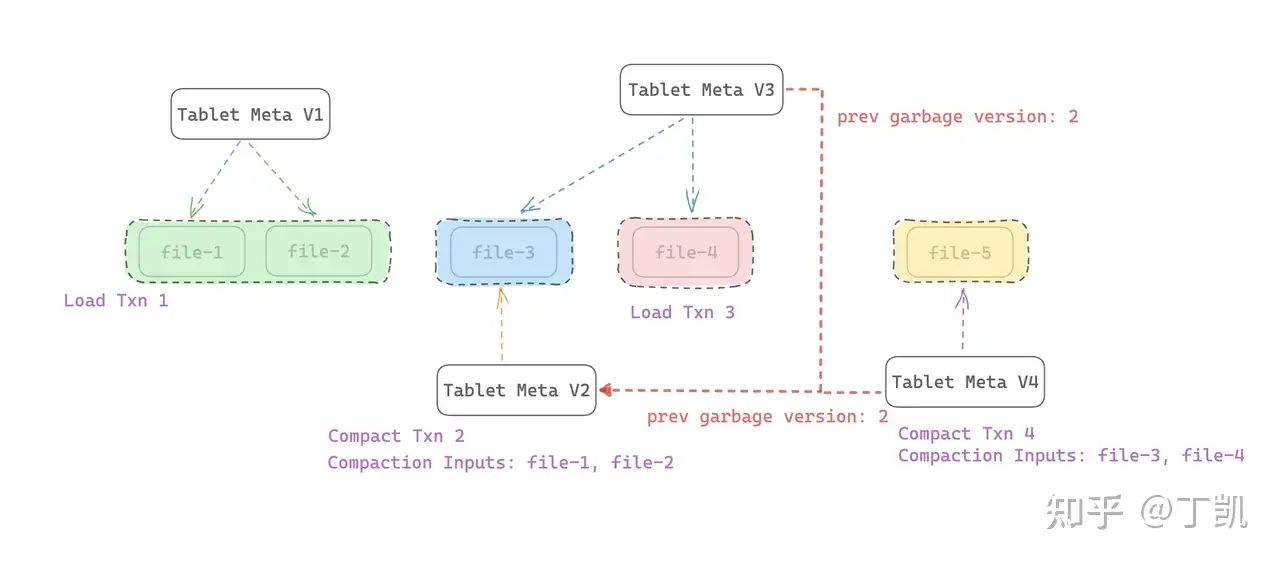
当前系统中有 4 次事务,其中
- Load Txn 1:导入事务,产生数据文件 file-1、file-2,该事务生成的 Meta V1 内记录文件为 {file-1, file-2}
- Compaction Txn 2:Compaction 事务,将 file-1、file-2 合并为新文件 file-3,该事务生成的 Meta V2 内记录文件为 {file-3},同时记录了 Compaction Inputs 为 {file-1, file-2}
- Load Txn 3:导入事务,产生数据文件 file-4,该事务生成的 Meta V3 内记录文件为 {file-3, file-4}
- Compaction Txn 4:数据合并事务,将 file-3、file-4 合并为新文件 file-5,该事务生成的 Meta V4 内记录文件为 {file-5}, 同时记录了 Compaction Inputs 为 {file-3, file-4}
试想下,如果按照顺序遍历的方式清理,那么我们首先:
- 要通过 list object 获取起始版本号,为 V1,产生一次对象存储的 list object 调用
- 以 V1 为起始版本号,逐个递增开始获得 Meta 文件,且对于每个 Meta 文件都需要读取内容,获得 Compaction Input Files 字段,取得可以被清理的数据文件列表,那么本例中就需要执行 4 次,如下:
打开并读取 Tablet Meta V1,获取 Compaction Input Files,然后清理
打开并读取 Tablet Meta V2,获取 Compaction Input Files,然后清理
打开并读取 Tablet Meta V3,获取 Compaction Input Files,然后清理
打开并读取 Tablet Meta V4,获取 Compaction Input Files,然后清理
这里需要访问 V1 ~ V4 这所有 Tablet Meta,而获取 Tablet Meta 文件内容可能是一个较为耗时的动作(假如 Tablet Meta Cache Miss 时就需要访问对象存储)。
而通过从后往前的回溯遍历方式就可以避免上述问题,但前提是需要构建好一个前向回溯链。
为了构造前向回溯链,我们做了一个优化,在每个 Tablet Meta 中记录了前一次 Compaction Txn 的版本号(prev_garbage_version),例如在本例中,Tablet Meta V3 中记录了该字段为 V2,而 Tablet Meta V4 由于拷贝自 Tablet Meta V3,因此 prev_garbage_version 字段值便也为 V2。
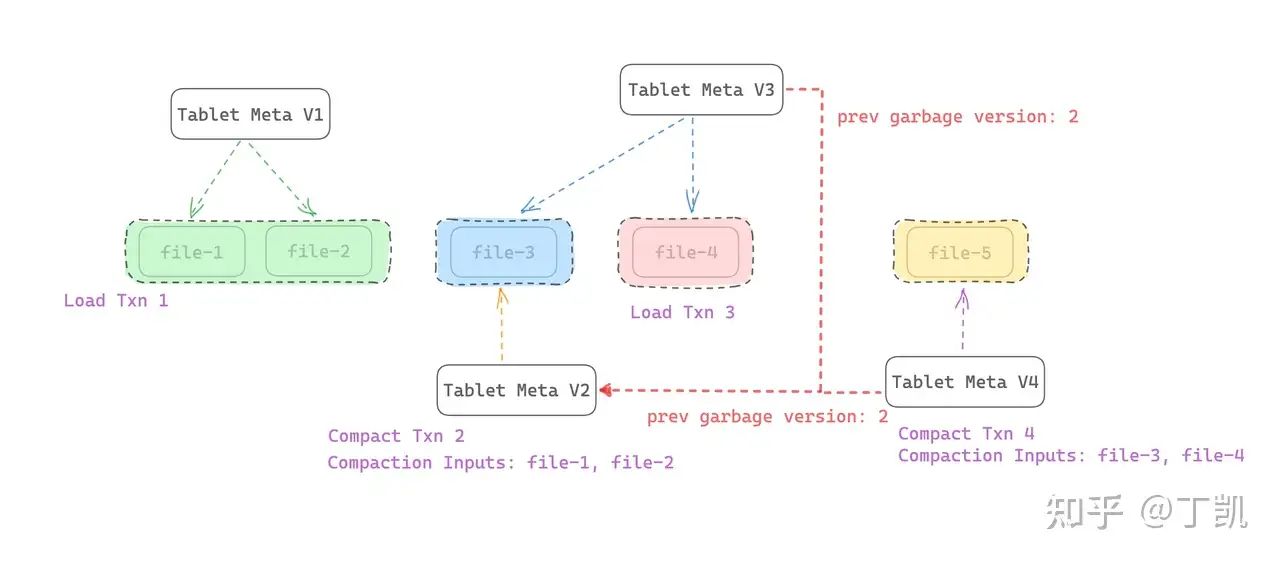
回收时,首先获得 Tablet Meta V4,假如判断其为安全可删除的,接下来找到 prev_garbage_version,这里记录为 V2,因而,这里便可以跳过 Tablet Meta V3,直接找到 Tablet Meta V2,获得其 Compaction inputs,也可以被安全删除。而由于 Tablet Meta V2 内的 prev_prev_garbage_version 为空,因此,便不再需要往前回溯了。这样,就避免了打开 Tablet Meta V1 和 Tablet Meta V3,就获得了所有 Compaction 事务的 Input Files。
清理 Segment 文件
垃圾回收的核心在于回收无用数据文件,而根据上文的基本原理可知,删除数据文件一般发生在清理那些 Compaction 事务产生的 Tablet Meta 文件时,这些文件中记录了当次 Compaction 的输入文件列表,由于这些文件已经被成功合并生成了新的文件,因此,这些原始输入文件可以被安全删除了。
因此,对于 CN 节点来说,就非常简单了,在上面的清理 Tablet Meta 文件时,捎带获取到 Tablet Meta 文件中记录的 Compaction Input Files 内容,然后就可以安全删除。
考虑到一般对象存储提供了批量删除文件接口,CN 在清理 Segment 文件时也进行了批量删除,由参数 lake_vacuum_min_batch_delete_size 控制批次大小。
清理 Txn Log 文件
Txn Log 文件在数据导入过程中产生,记录本次导入或者 Compaction 过程中产生的新文件。正常情况下,Txn Log文件一般在事务提交后即被删除。但异常时该文件可能会残留,也依赖后台的 Vacuum 任务来统一清理。
CN 清理时首先通过 list objects 来获得当前所有的 Txn Log 文件(由于 Txn Log 文件存储在单独 log/ 目录下,对象数较少,list 效率一般不会成为大问题),然后从文件名中解析出 tablet id 和 txn id 信息,接下来判断该 Txn Log 文件是否可以被安全删除,原理也比较简单:
判断该txn id是否比当前系统中的最小活跃事务id更小(min active txn id),如果是,那么意味着该事务一定在 FE 上已经结束了(要么已提交,要么已回滚),此时 Txn Log 即可被安全删除。
删除表和分区
StarRocks 目前有如下几种方式来删除表和分区:
drop table xxx;
drop table xxx force;
drop partition xxx;
drop partition xxx force;
前者实现了回收站机制,删除的表会先放入回收站,直到一段时间后才开始真正删除。而后者则立即删除,无任何缓冲时间。
当前实现中,删除表会触发我们物理删除表上的所有数据,而从对象存储删除数据是一个非常耗时的动作。我们将两种删除模式进行统一,都统一为后台异步清理模式。用户提交的删除表命令会立即返回成功,后台线程会慢慢删除表的物理数据。
删除表
删除分区的实现原理同删除表基本一致,也都是将待删除的分区加入回收站中,而 FE 后台线程则会不断地从回收站中取出需要被删除的 table,执行真正的删除动作。
真正的数据删除在 deleteFromRecycleBin 内实现,对于存算分离内表,对于一个表进行物理删除时,内部也是按照分区为单位逐个进行删除,因为我们当前最新的版本是按照分区为粒度组织数据目录,如下所示:
${cluster_uuid}/${db_id}/${table_id}/${partition_id}
而删除最终是调用了 CN 节点的 drop_table 的 RPC 接口来执行真正的数据删除。
真正删除时,通过调用 remove_all 来直接将分区目录下面的所有文件一次性删除,效率较高。而且,可以发现,这里的删除任务会被提交到一个独立的线程池来执行。
删除分区
删除分区的实现原理同删除表基本一致,也都是将待删除的分区加入回收站中,然后在回收站后台慢慢清理。最终的清理也是调用 CN 节点的 drop_table 的 rpc 接口来完成真正的数据删除。这个已经在前面描述过,这里就不再赘述。
缓存清理
当前的实现中,回收对象存储的垃圾数据文件时并不会同步删除缓存,缓存淘汰依赖自身的 LRU 机制。