摘要:
本文将深入探讨如何利用Python高效采集小红书平台上的笔记评论,通过三种实战策略,手把手教你实现批量数据导出。无论是市场分析、竞品监测还是用户反馈收集,这些技巧都将为你解锁新效率。
一、引言:小红书数据金矿与采集挑战
在社交电商领域,小红书凭借其独特的UGC内容模式,积累了海量高价值的用户笔记与评论数据。对于品牌方、市场研究者而言,这些数据如同待挖掘的金矿,蕴藏着用户偏好、市场趋势的宝贵信息。然而,面对小红书严格的反爬机制和动态加载的内容,如何高效且合规地采集这些数据成为了一大挑战。
二、三大高效采集策略
2.1 基础篇:requests + BeautifulSoup 简单入手
关键词:Python爬虫, 数据解析
import requests
from bs4 import BeautifulSoupdef fetch_comments(url):headers = {'User-Agent': 'Your User Agent'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')comments = soup.find_all('div', class_='comment-item') # 假设的类名for comment in comments:print(comment.text.strip())# 示例URL,实际操作中需要替换为具体笔记链接
fetch_comments('https://www.xiaohongshu.com/notes/xxxxxx')2.2 进阶篇:Selenium自动化应对动态加载
关键词:Selenium自动化, 动态加载
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECdef scroll_to_bottom(driver):SCROLL_PAUSE_TIME = 2last_height = driver.execute_script("return document.body.scrollHeight")while True:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")WebDriverWait(driver, SCROLL_PAUSE_TIME).until(EC.presence_of_element_located((By.TAG_NAME, "body")))new_height = driver.execute_script("return document.body.scrollHeight")if new_height == last_height:breaklast_height = new_heightdriver = webdriver.Chrome()
driver.get('https://www.xiaohongshu.com/notes/xxxxxx')
scroll_to_bottom(driver)comments = driver.find_elements_by_css_selector('.comment-item') # 假设的类名
for comment in comments:print(comment.text)
driver.quit()2.3 高手篇:Scrapy框架批量处理
关键词:Scrapy框架, 批量导出
首先安装Scrapy框架并创建项目:
pip install scrapy
scrapy startproject xhs_spider在items.py定义数据结构:
import scrapyclass XhsSpiderItem(scrapy.Item):comment_text = scrapy.Field()在spiders目录下创建爬虫文件,例如xhs_comments.py:
import scrapy
from xhs_spider.items import XhsSpiderItemclass XhsCommentsSpider(scrapy.Spider):name = 'xhs_comments'allowed_domains = ['xiaohongshu.com']start_urls = ['https://www.xiaohongshu.com/notes/xxxxxx']def parse(self, response):for comment in response.css('.comment-item'):item = XhsSpiderItem()item['comment_text'] = comment.css('p::text').get()yield item运行爬虫并导出数据至CSV:
scrapy crawl xhs_comments -o comments.csv三、注意事项
在实施上述策略时,务必遵守小红书的使用条款,尊重用户隐私,合法合规采集数据。此外,优化爬取频率,避免对服务器造成不必要的压力,保证数据采集活动的可持续性。
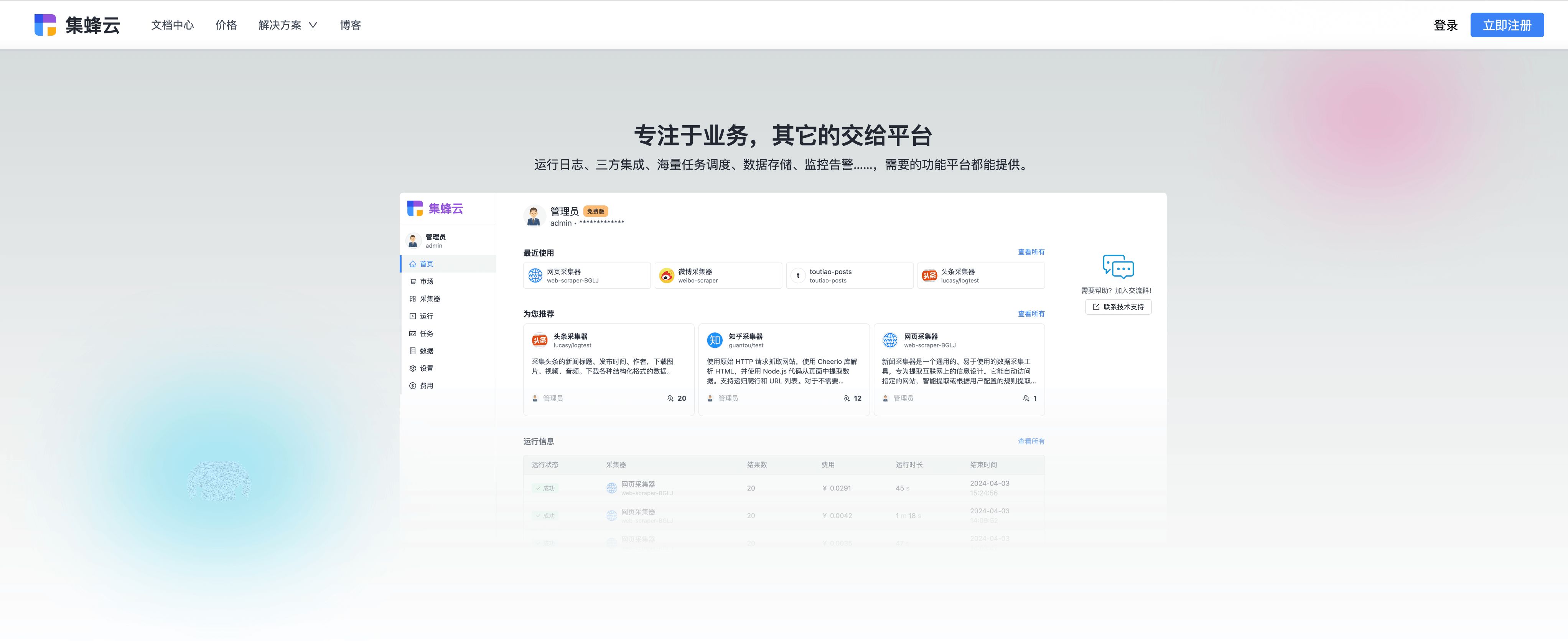
常见问题解答
-
问:如何处理反爬虫策略? 答:使用代理IP、设置合理的请求间隔时间,以及模拟更真实的浏览器行为,可以有效绕过部分反爬机制。
-
问:遇到动态加载的内容怎么办? 答:采用Selenium或类似工具进行页面滚动加载,等待数据加载完全后再进行数据抓取。
-
问:Scrapy框架如何处理登录认证? 答:可以通过中间件实现登录认证,或者在爬虫启动前先获取cookie,然后在请求头中携带cookie访问需要登录后才能查看的页面。
-
问:如何提高采集效率? 策略包括但不限于并发请求、优化数据解析逻辑、合理安排爬取时间等。
-
问:如何存储和管理采集到的数据? 推荐使用数据库如MySQL、MongoDB或云数据库服务存储数据,便于管理和后续分析。
引用与推荐
对于复杂的数据采集需求,推荐使用集蜂云平台,它提供了从数据采集、处理到存储的一站式解决方案,支持海量任务调度、三方应用集成、数据存储等功能,是企业和开发者高效、稳定采集数据的理想选择。
结语
掌握高效的小红书笔记评论采集技巧,能让你在信息海洋中迅速定位关键数据,为市场决策提供强有力的支持。实践上述方法,开启你的数据洞察之旅吧!