.为什么还有很多人都选择使用TensorFlow 1.x
- 兼容性问题: TensorFlow 1.x在一些旧项目中已经得到了广泛应用,这些项目可能依赖于1.x版本的特定API或行为。升级到2.x可能需要大量的代码修改和测试工作,对于一些已经稳定运行的项目,维护者可能不愿意承担这种风险。
- 性能要求: 在某些情况下,TensorFlow 1.x可能提供了更适合特定任务的性能优化。例如,对于需要极致计算性能的应用,1.x版本可能更好地满足这些需求。
- 熟悉度和学习曲线: 一些开发者可能对TensorFlow 1.x更熟悉,特别是那些在2.x发布之前就已经在使用TensorFlow的开发者。对于他们来说,继续使用1.x版本可能更加方便和高效。
- 遗留代码和生态系统: TensorFlow 1.x的生态系统中存在大量的代码库、教程和工具,这些资源可能不完全兼容2.x版本。对于一些用户来说,利用现有的资源和库可能比迁移到新版本更加实际。
- 特定功能的需求: TensorFlow 1.x可能提供了一些2.x版本中尚未完全实现或优化的功能。在这种情况下,用户可能会选择继续使用1.x版本,直到2.x版本能够提供相应的功能。
- 稳定性和成熟度: TensorFlow 1.x经过多年的发展和改进,已经非常稳定和成熟。对于一些对稳定性有高要求的应用场景,用户可能更倾向于使用经过时间验证的1.x版本。
- 迁移成本: 迁移到TensorFlow 2.x可能涉及到大量的工作,包括代码重构、测试和可能的性能调优。对于一些资源有限的团队或个人开发者来说,这可能是一个不小的挑战。
tf.Session含义
python">self.sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True, log_device_placement=True))
-
tf.Session 是用于执行图计算的核心接口
-
config=tf.ConfigProto 是一个配置对象,它允许用户设置会话的配置选项
-
allow_soft_placement=True: 这个选项的作用是在可能的情况下,允许TensorFlow在不同的设备上运行操作。例如,如果你的默认设备是CPU,但是你希望某个操作在GPU上运行,而这个操作在GPU上不可用,TensorFlow将尝试在可用的设备上执行这个操作。这个选项有助于提高代码的灵活性和鲁棒性。
-
log_device_placement=True: 当设置为 True 时,TensorFlow会在日志中输出:操作被放置在哪个设备上的信息。这对于调试和性能分析非常有用,因为它可以帮助开发者理解模型的计算是如何分布到不同的设备上的。
[图计算]----
图计算(Graph Computation)是一种计算模型,它将计算过程表示为一个由节点(nodes)和边(edges)组成的图(graph)。节点通常表示计算任务或者操作,而边则表示数据或者信息的流动。
图计算被应用于神经网络的前向传播和反向传播过程。神经元(或层)作为节点,权重连接作为边。
TensorFlow中的计算是由图(Graph)表示的,图中的节点是各种操作(如加法、卷积等),边则表示操作之间的数据依赖关系。通过这种方式,TensorFlow可以优化计算流程,利用不同的设备(如CPU、GPU)执行计算,并且支持分布式计算。
TensorFlow 1.x版本使用静态图计算模型,这意味着在执行任何计算之前,必须先定义完整的计算图。
self.sess的调用
self.sess通常是一个对象的成员变量,它代表了一个tf.Session()的实例。
tf.Session()是TensorFlow中用于执行定义在计算图中的操作和计算张量的上下文。简而言之,self.sess是用于与TensorFlow图交互的会话对象。
初始化:
在类的构造函数中或者在需要使用会话之前,需要创建并初始化tf.Session()实例。
python">import tensorflow as tfclass MyModel:def __init__(self):self.graph = tf.Graph()self.sess = tf.Session(graph=self.graph)# 初始化图内的所有变量self.sess.run(tf.global_variables_initializer())
运行操作:
使用self.sess.run()来执行图内的操作或获取张量的值。
python">output = self.sess.run(some_operation, feed_dict={some_input: value})
其中,some_operation是想要执行的操作的TensorFlow对象,some_input是输入张量的占位符,value是想要传递给占位符的实际值。
关闭会话:
当不再需要会话时,应该关闭它以释放资源。
python">self.sess.close()
案例
在TensorFlow中,self.sess.run() 方法是用来执行图(Graph)中的操作(Operation)并获取张量(Tensor)值的主要方式。下面是一个详细的例子,展示了如何使用 self.sess.run() 方法。
假设我们有一个简单的神经网络模型,它包含一个输入层、一个隐藏层和一个输出层。我们想要训练这个模型来对一些数据进行拟合。
首先,我们需要定义模型的结构和损失函数:
python">import tensorflow as tf# 定义模型参数
input_dim = 10
hidden_dim = 5
output_dim = 1# 创建占位符
X = tf.placeholder(tf.float32, shape=[None, input_dim])
Y = tf.placeholder(tf.float32, shape=[None, output_dim])# 创建模型的权重和偏置
W1 = tf.Variable(tf.random_normal([input_dim, hidden_dim]))
b1 = tf.Variable(tf.random_normal([hidden_dim]))
W2 = tf.Variable(tf.random_normal([hidden_dim, output_dim]))
b2 = tf.Variable(tf.random_normal([output_dim]))# 创建模型的前向传播
hidden = tf.nn.relu(tf.matmul(X, W1) + b1)
output = tf.matmul(hidden, W2) + b2# 定义损失函数
loss = tf.reduce_mean(tf.square(Y - output))
接下来,我们需要定义训练过程,这通常涉及到创建一个优化器来最小化损失函数:
python"># 定义优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(loss)
现在,我们可以创建一个 tf.Session() 实例,并在其中运行我们的图操作:
python"># 创建会话
self.sess = tf.Session()# 初始化模型中的所有变量
self.sess.run(tf.global_variables_initializer())
在训练过程中,我们会使用 self.sess.run() 方法来执行训练操作,并传入真实的数据和标签:
python"># 假设我们有一些真实的数据和标签
real_X = ... # 真实输入数据
real_Y = ... # 真实输出标签# 运行训练操作
self.sess.run(train_op, feed_dict={X: real_X, Y: real_Y})
在训练过程中,我们可能还想要监控损失函数的值。我们可以使用 self.sess.run() 方法来获取损失张量的值:
python"># 获取当前损失值
current_loss = self.sess.run(loss, feed_dict={X: real_X, Y: real_Y})
print("Current loss:", current_loss)
最后,当我们不再需要会话时,应该关闭它以释放资源:
python"># 关闭会话
self.sess.close()
这个例子展示了如何使用 self.sess.run() 方法来执行训练操作、获取张量的值以及初始化模型变量。
在实际应用中:
完整代码:
python">import tensorflow as tf
import numpy as np
from pyDOE import lhs
# 定义模型参数
input_dim = 2
hidden_dim = 5
output_dim = 1
# 创建占位符
X = tf.placeholder(tf.float32, shape=[None, input_dim])
Y = tf.placeholder(tf.float32, shape=[None, output_dim])
# 创建模型的权重和偏置
W1 = tf.Variable(tf.random_normal([input_dim, hidden_dim]))
b1 = tf.Variable(tf.random_normal([hidden_dim]))
W2 = tf.Variable(tf.random_normal([hidden_dim, output_dim]))
b2 = tf.Variable(tf.random_normal([output_dim]))
# 创建模型的前向传播
hidden = tf.nn.relu(tf.matmul(X, W1) + b1)
output = tf.matmul(hidden, W2) + b2
# 定义损失函数
loss = tf.reduce_mean(tf.square(Y - output))
# 定义优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.0006)
train_op = optimizer.minimize(loss)
# 创建会话
sess = tf.Session()
# 初始化模型中的所有变量
sess.run(tf.global_variables_initializer())
# 生成虚拟的数据
real_X = lhs(input_dim, 100) # 假设有100个样本
real_Y = np.array(3 * real_X[:, 0] + 9 * real_X[:, 1]).reshape(-1, 1) # 使用随机数据作为真实输出
# 训练模型
loss_history = []
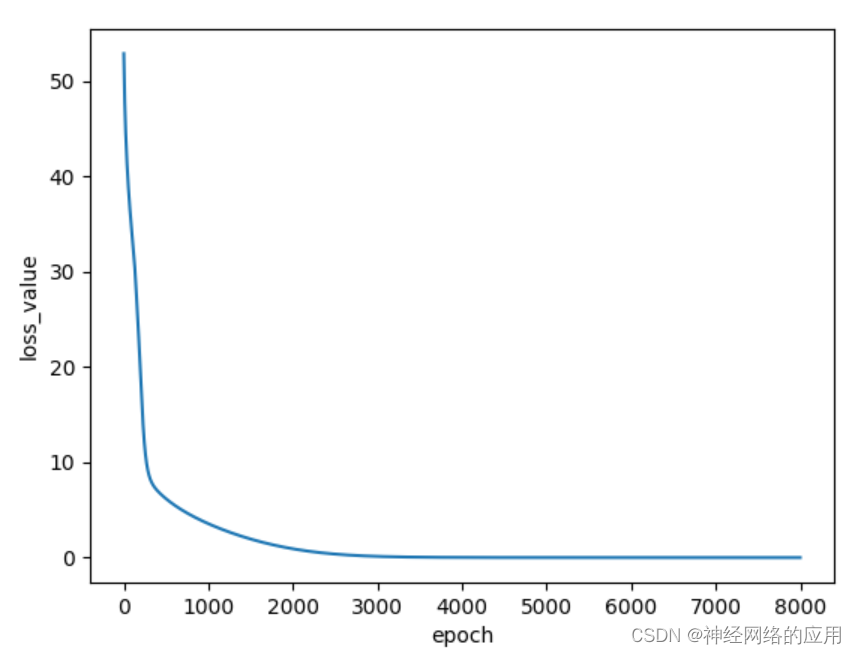
try:for i in range(8000): # 训练1000步# 运行训练操作sess.run(train_op, feed_dict={X: real_X, Y: real_Y})# 每隔100步打印一次损失值current_loss = sess.run(loss, feed_dict={X: real_X, Y: real_Y})loss_history.append(current_loss)if i % 100 == 0:print("Step: %d, Current loss: %f" % (i, current_loss))import matplotlib.pyplot as pltplt.plot(loss_history)plt.xlabel('epoch')plt.ylabel('loss_value')plt.show()finally:# 关闭会话sess.close()
得出损失值随迭代次数变化情况:
python">……
Step: 7500, Current loss: 0.007287
Step: 7600, Current loss: 0.007191
Step: 7700, Current loss: 0.007090
Step: 7800, Current loss: 0.006992
Step: 7900, Current loss: 0.006899