目的
数据库使用SQL 语言查询数据,数据库的记录中要有一个关键字段(通常称为主键字段,它的值在数据库列表中是唯一的),数据记录是结构化的.
如果你需要根据数据记录的内容来查询数据记录,就需要通过Select 语句在数据库中历遍所有的数据记录。对于非结构化的文档数据库而言,可能某些属性嵌入在记录值的文本中,就显得非常复杂了。
例如 查询年龄在10岁到18岁的学生 的数据比较简单,但是如果查询查询读过《西游记》的学生,可能就比较难一点。除非你设置一个字段包含书籍的列表。
同样的,对于商品数据库而言,商品的信息大量是非结构化的数据。例如产品信息中可能包含了用途的字段,内容是“该产品主要用于修补汽车轮胎” 。当需要查找 ”修补轮胎的胶水“,就需要查找产品分类名称为”胶水“,用途为”该产品主要用于修补汽车轮胎“ 。使用SQL 时要一字不差才行。
为了提高查询的效率,SQL 数据库只能采取添加关键字的方式来实现,比如添加 ”汽车“,”修补“,”轮胎“ 几个关键字,或者将产品的分类做的非常细。
SQL 查询方法要求非常严苛,缺乏了灵活性。在一些分类系统中(Catalog System)。查询信息非常刻板,令人恼火。
解决方案
为了解决这些问题,基于大预言模型的向量数据库应运而生。
需要用于 AI 的非结构化数据集的数量只会继续增长,那么您如何处理数百万个向量呢?这就是向量嵌入和向量数据库发挥作用的地方。这些向量在称为嵌入的连续多维空间中表示,该空间由嵌入模型生成,专门用于将向量数据转换为嵌入。向量数据库用于存储嵌入模型的输出并对其进行索引。向量嵌入是数据的数值表示,根据语义含义或几乎任何数据类型的类似特征对数据集进行分组。
例如,以“car”和“vehicle”这两个词为例。它们都具有相似的含义,即使它们的拼写不同。为了使 AI 应用程序能够实现有效的语义搜索,“car”和“vehicle”的向量表示必须捕获它们的语义相似性。在机器学习方面,嵌入表示编码此语义信息的高维向量。这些向量嵌入是推荐、聊天机器人和 ChatGPT 等生成式应用程序的支柱。
向量数据库能够将向量存储为高维点并进行检索。这些数据库增加了额外的功能,可以高效、快速地查找 N 维空间中的最近邻。开发人员将文档生成的向量索引到向量数据库中。这样的话,他们便可通过查询相邻向量来找到相似的内容。
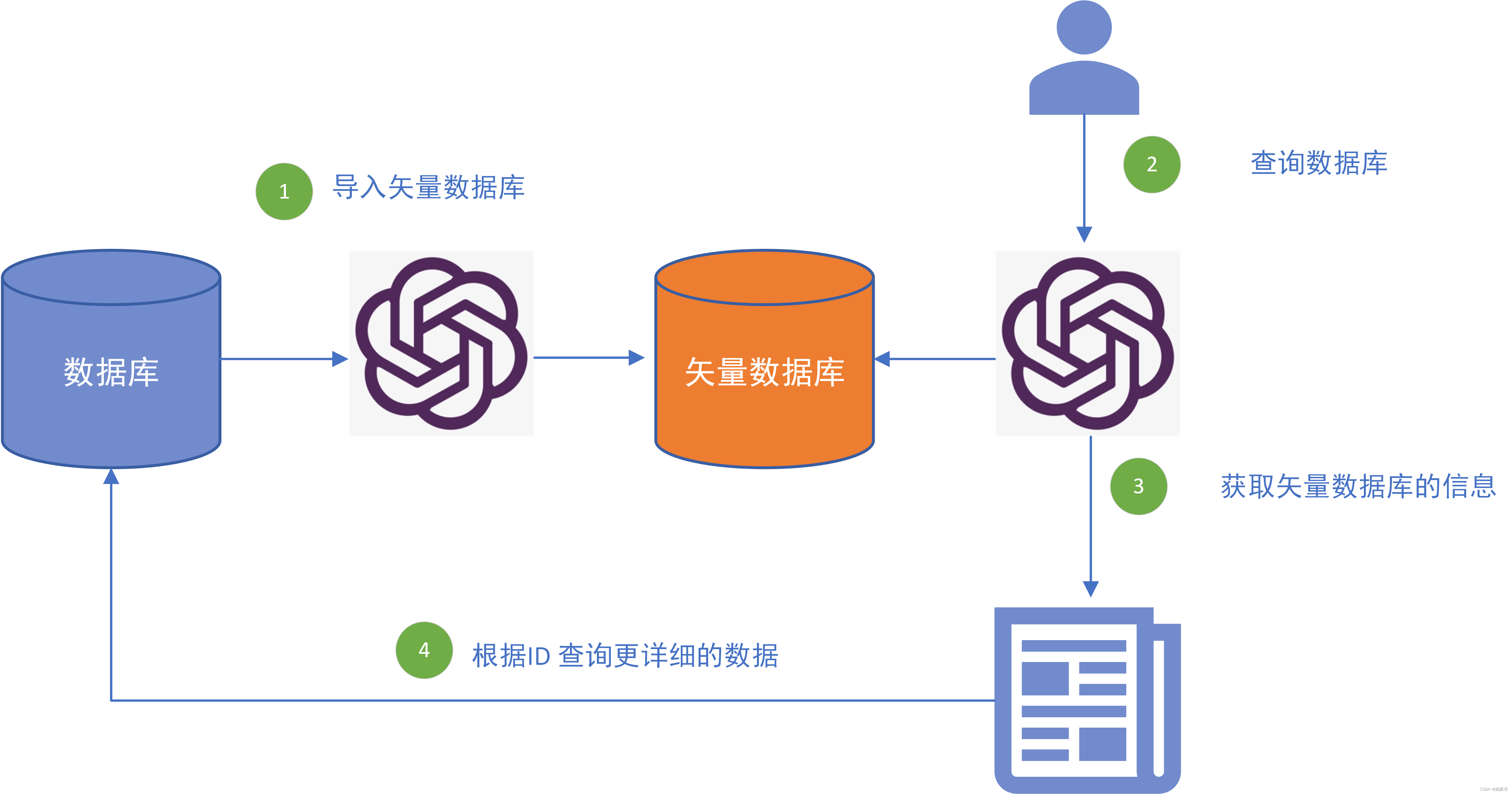
在大模型应用Embedding 技术将许多文档切片,然后生成矢量数据库,将文档中的内容转换为矢量数据库的内容,当对话机器人提问时,通过查询矢量数据库获取最相近的知识,由大模型回答问题。流程如下图所示。

针对数据库查询而言,我们如何生成矢量数据库的内容呢?我的解决思路是将数据库的所有记录读出来,作为文档喂给矢量数据库。 并且将数据库记录的ID 作为矢量数据库的ID。
实验方法
实验使用三个程序完成,原始数据存储在mongoDB 数据库中,矢量数据库使用开源的Chroma。
mongoDB 上添加产品信息
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client['productDB']
collection = db['product']
"""
documents = []
documents.append({"name":"motor","brand":"sanyo","manufacture":"sanyo motor company","feature":{"current":"10A","voltage":"48V","power":"120Kw","speed":"1200"}})
documents.append({"name":"DCmotor","brand":"maxon","manufacture":"maxon","feature":{"current":"5A","voltage":"24V","power":"10W","speed":"2400"}})
documents.append({"name":"servo motor","brand":"inovance","manufacture":"inovance","feature":{"current":"2A","voltage":"24V","power":"80W","speed":"4800"}})
"""
#collection.insert_many(documents)
for data in collection.find():print ("Model"+str(data))print(data["_id"])生成矢量数据库
from langchain.vectorstores import Chroma
from langchain.chat_models import ErnieBotChat
from langchain.embeddings import ErnieEmbeddings
from langchain.docstore.document import Document
import os
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client['productDB']
collection = db['product']
os.environ['ERNIE_CLIENT_ID'] ="xxxxx"
os.environ['ERNIE_CLIENT_SECRET'] ="xxxx"
db_path = "./product_vector" #索引库名称
embeddings = ErnieEmbeddings(ernie_client_id='FAiHIjSQqH5gAhET3sHNTkiH',ernie_client_secret='wlIBmWY4d2Zvrs0GyQbT3JeTXV6kdub4',
)
#loader = PyPDFLoader("example_data/text.pdf")
#docs = loader.load()
#print("Loadded....")
m_docs=[]
m_ids=[]
for data in collection.find():#print("model"+str(data))m_docs.append(Document(page_content="this is an product struct data in json :"+str(data)))m_ids.append(str(data["_id"]))
print(m_ids)
print(m_docs)
vectorstore = Chroma.from_documents(documents=m_docs,ids=m_ids,persist_directory=db_path, embedding=ErnieEmbeddings())查询产品
from langchain.vectorstores import Chroma
from langchain.chat_models import ErnieBotChat
from langchain.embeddings import ErnieEmbeddings
from langchain.chains import RetrievalQA
from langchain import PromptTemplateimport os
os.environ['ERNIE_CLIENT_ID'] ="xxxx"
os.environ['ERNIE_CLIENT_SECRET'] ="xxxx"
db_path = "./product_vector" #索引库名称
embeddings = ErnieEmbeddings(ernie_client_id='FAiHIjSQqH5gAhET3sHNTkiH',ernie_client_secret='wlIBmWY4d2Zvrs0GyQbT3JeTXV6kdub4',
)llm_model = ErnieBotChat(model_name='ERNIE-Bot', #ERNIE-Boternie_client_id='FAiHIjSQqH5gAhET3sHNTkiH',ernie_client_secret='wlIBmWY4d2Zvrs0GyQbT3JeTXV6kdub4',temperature=0.75,)
vectorstore = Chroma(persist_directory="./product_vector",embedding_function=embeddings)# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
print("RAG....")
prompt_template = """参考内容如下:
---------------------
{context}
---------------------
请根据上面内容,回答下面这个问题: {question}
如果无法根据上面内容回答问题,请如实说明,我不知道:"""PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT, "verbose":True}
qa = RetrievalQA.from_chain_type(llm=llm_model,chain_type="stuff",retriever=retriever,chain_type_kwargs=chain_type_kwargs)query = "查找 功率为 80W产品的电机"ret = qa.run(query)
print(ret)结果
runfile('E:/yao2024/python2024/untitled2.py', wdir='E:/yao2024/python2024')
RAG....
Number of requested results 4 is greater than number of elements in index 3, updating n_results = 3> Entering new StuffDocumentsChain chain...> Entering new LLMChain chain...
Prompt after formatting:
参考内容如下:
---------------------
this is an product struct data in json :{'_id': ObjectId('661f838f21552cd009b44b48'), 'name': 'servo motor', 'brand': 'inovance', 'manufacture': 'inovance', 'feature': {'current': '2A', 'voltage': '24V', 'power': '80W', 'speed': '4800'}}this is an product struct data in json :{'_id': ObjectId('661f838f21552cd009b44b46'), 'name': 'motor', 'brand': 'sanyo', 'manufacture': 'sanyo motor company', 'feature': {'current': '10A', 'voltage': '48V', 'power': '120Kw', 'speed': '1200'}}this is an product struct data in json :{'_id': ObjectId('661f838f21552cd009b44b47'), 'name': 'DCmotor', 'brand': 'maxon', 'manufacture': 'maxon', 'feature': {'current': '5A', 'voltage': '24V', 'power': '10W', 'speed': '2400'}}
---------------------
请根据上面内容,回答下面这个问题: 查找 功率为 80W产品的电机
如果无法根据上面内容回答问题,请如实说明,我不知道:> Finished chain.> Finished chain.
根据提供的JSON数据内容,我们可以找到功率为80W的电机产品。以下是符合这一条件的产品信息:```json
{'_id': ObjectId('661f838f21552cd009b44b48'),'name': 'servo motor','brand': 'inovance','manufacture': 'inovance','feature': {'current': '2A','voltage': '24V','power': '80W','speed': '4800'}
}
```
这款产品的名称为"servo motor",品牌为"inovance",制造商为"inovance",功率为80W。其他特性包括电流为2A,电压为24V,转速为4800。结束语
大模型支持下的分类数据库智能查询在企业应用中非常广泛,比如 物料管理,产品管理,生命周期管理,B2B 电商,知识库,技术文档查询等等。
大语言模型的横空出世将快速地改变软件的架构,数据存储方式。这是我们值得注意的,