1999年Dan Kegel在发表的论文中提出了The C10K problem,这篇论文对传统服务器架构处理大规模并发连接时的挑战进行了详细描述,并提出了一些解决方案和优化技术。这里的C指的是Concurrent(并发)的缩写,C10K问题是指怎么在单台服务器上并发一万个请求。如果你分析过性能问题一定会注意到,性能极限通常受到一个或多个资源的限制,比如内存、文件句柄个数、网络带宽、CPU等。这里讨论的前提是机器的物理资源和系统配置能够满足一万个请求。在这个前提下,网络并发主要关注两个方面:一是应用程序和操作系统内核之间如何进行IO事件通知,二是应用程序进程或线程的分配方式。
I/O模型
阻塞vs非阻塞、同步vs异步
你可能经常看到某某项目用的同步非阻塞模型、某某项目用的异步非阻塞模型,所以在正式讨论I/O模型前,还是先对齐一下关于阻塞、非阻塞以及同步、异步的概念吧。
阻塞、非阻塞指的是系统调用时“等待数据准备好”这个动作。比如read时候,如果内核判定数据还没准备好:
- 内核让应用进程一直等待,直到数据准备好才通知应用进程就是阻塞;
- 内核立即通知应用程序说数据没准备好,你先干别的吧,就是非阻塞。
同步、异步指的是“内核空间与用户空间复制数据”这个动作。比如read时候,如果内核判定数据还没准备,过一段时间数据来了:
- 内核通知应用进程你来读取数据吧,应用程序再次系统调用将数据读走就是同步;
- 内核将数据拷贝到用户空间后再通知应用进程,数据已经拷贝好了直接用吧,就是异步。
I/O模型详解
Stevens在《UNIX 网络编程 卷1》一书的6.2章节介绍了五种 I/O 模型。以下模型以UDP接收报文为例来说明这五种I/O 的工作方式。
> 阻塞式I/O
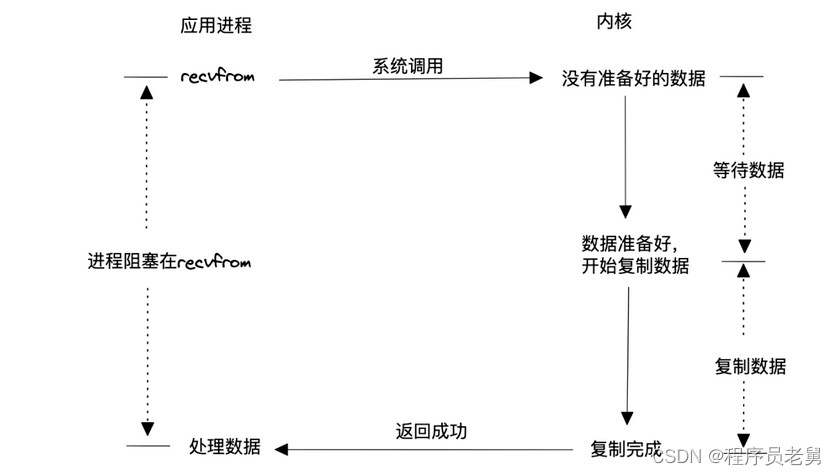
该模型使用最简,用户进程调用读取数据系统后就一直等待,直到内核数据准备好,并将数据从内核空间拷贝到用户空间后,调用结束。这种模型效率显然的低下,因为这种模型会导致两种可能结果:
- 为每个请求分配一个进程或线程,那么高并发意味着内核要调度的进程或线程数量很庞大,调度、上下文切换等开销会使系统性能降低。
- 固定数量的进程或线程处理请求,那么这些进程或线程全被被占用后,新请求就只能等了。
该模型低效的根本原因在于阻塞,内核数据没有准备好的时候,用户态进程明明可以干其他活的,现在只能白白等待。
>非阻塞式 I/O
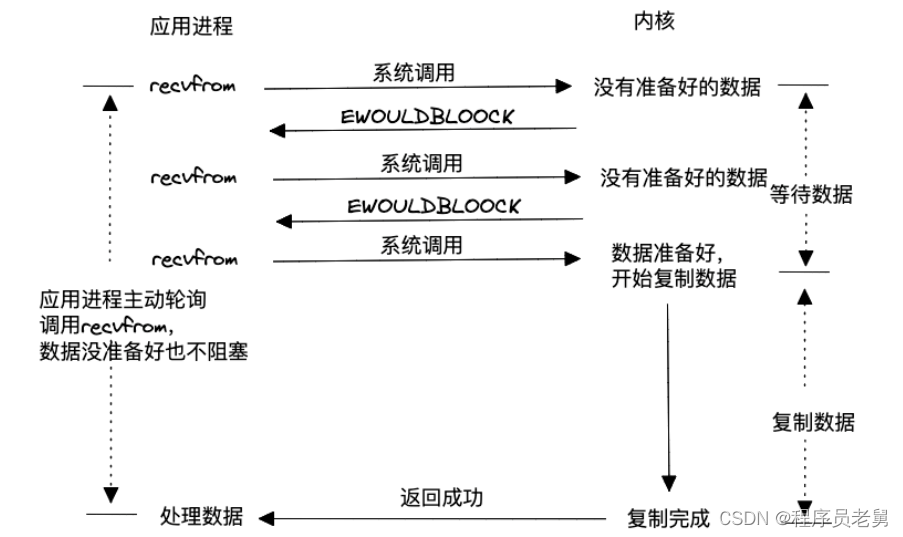
这种模型通过非阻塞的方式与内核打交道,如果内核中数据还未准备好,就立刻返回给用户进程,用户进程就可以先干别的事情,过一段再进行读数据的系统调用,直到内核数据准备好,并将数据拷贝到用户空间。相比于阻塞的模型,这种非阻塞+主动轮询的模型避免了用户进程白白等待内核准备数据的时间,所以效率有所提升,但是因为每次轮询都是系统调用,所以上下文切换变多了,因此性能也不高。
>I/O 复用
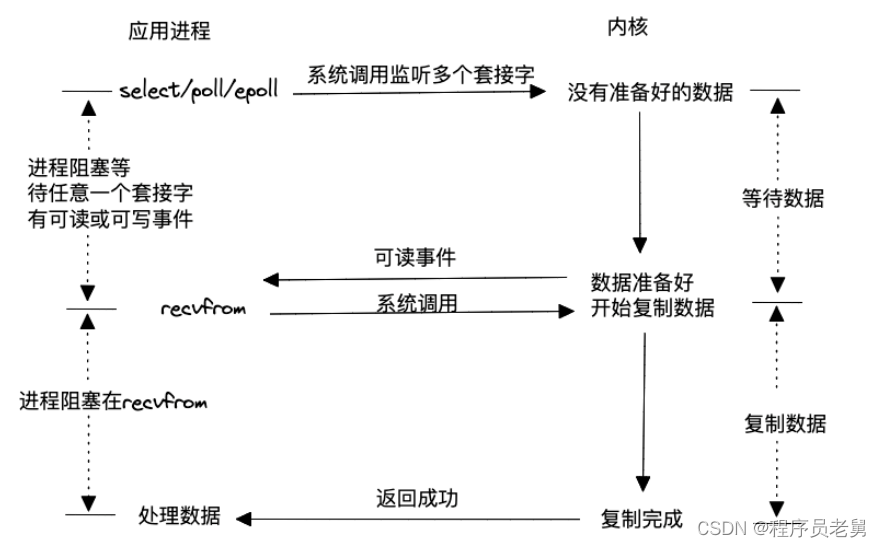
既然不停主动查询内核数据是否准备好这件事会引起系统性能下降,那能不能通过注册+通知的方式呢?这就是大名鼎鼎的I/O复用模型。该模型允许用户态通过一个进程将所有相关的读写事件(使用select、poll或epoll)注册到内核,然后内核会主动通知用户态进程,一旦任意一个或多个请求的读写数据准备好。这种方式在单个进程或线程中同时处理多个I/O通道的就绪状态被称为I/O多路复用。使用I/O多路复用既不会阻塞处理请求的进程,也不会因为轮询内核数据是否准备好而导致过多的系统调用,因此具有高效的特点。然而,需要注意的是,一旦内核通知应用进程数据准备就绪,仍然需要通过系统调用触发数据的读取过程。
Linux内核对这种模型的支持非常完善,因此许多高性能服务器在Linux环境中广泛采用这种模式。
>信号驱动式 I/O
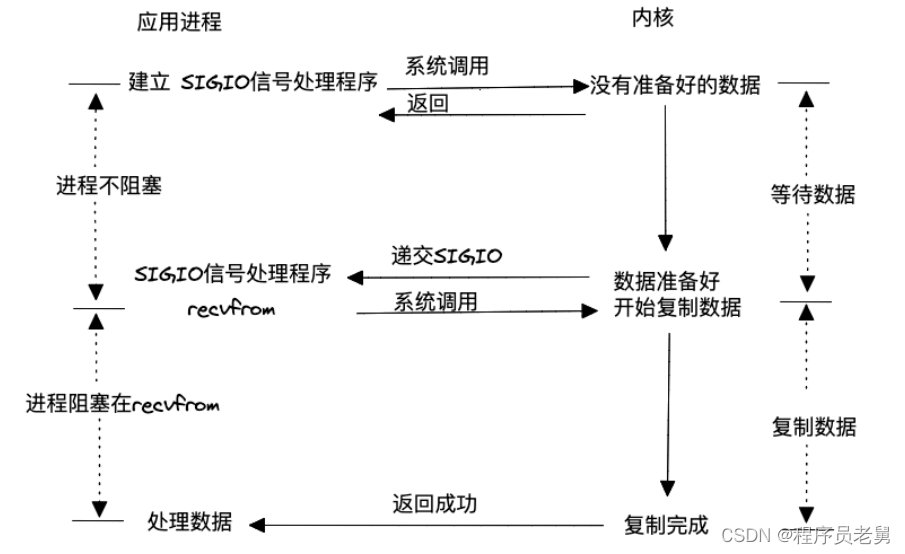
I/O复用模型中是用一个进程(select、poll或epoll)阻塞或轮询所有请求的数据是否准备好,从而让所有请求进程的处理都不会阻塞。信号驱动式则没有这个复用的I/O进程,每个请求进程自己去内核注册,然后等数据准备好内核通知应用进程去处理。这种模型应用套接字处理的实践场景为基于UDP的NTP服务,几乎没有在TCP上的应用,因为对于TCP来说信号产生过于频繁,而且并没有告诉应用程序发生了什么事件,比如下面条件均会导致TCP套接字产生SIGIO信号:
- 监听套接字某个连接请求已经完成;
- 某个断链请求已经发起;
- 某个断链请求已经完成;
- 某个半连接已经关闭;
- 数据到达套接字;
- 数据已经从套接字发出;
- 发生某个异步错误。
>异步 I/O
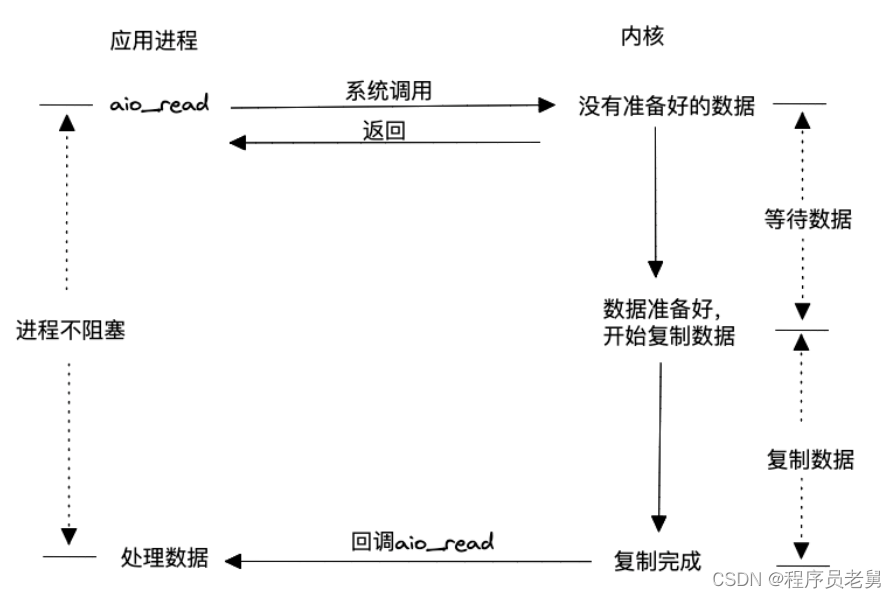
前面几种方式,无论是阻塞还是非阻塞,从内核空间到用户空间复制数据的动作都是在内核通知用户进程后,用户进程再通过系统调用触发完成的,因此都属于同步操作。而异步I/O模型则不同,它允许用户态进程通过系统调用读取数据后,即使内核数据未准备好,也会立即返回给用户进程,告知数据未准备好,让用户进程可以执行其他操作。当数据准备好后,内核会将数据从内核空间拷贝到用户态,并直接回调用户进程,将数据送到用户进程手中。这种模型不仅具备非阻塞特性,还能进一步减少系统调用的次数,因此在理论上相对于其他模型更加高效。需要注意的是,这种模型需要操作系统内核的支持。
在《UNIX网络编程卷1》一书中,截至书稿时,支持POSIX异步I/O的系统相对较少。由于早期Linux内核对网络异步I/O的支持不够成熟,在Linux环境下,大多数高性能网络服务器选择采用I/O复用的方式,如epoll。然而,从Linux内核5.0版本开始,引入了io_uring异步操作,随着该技术的成熟,越来越多的高性能网络服务器(例如nginx)开始支持使用这种异步I/O方式。
>如何简单理解5种I/O?
下面通过一个例子对比一下5种模型,顾客是应用进程,餐饮人员为内核,餐桌为应用进程的数据buffer:
- 阻塞式I/O:交完钱也要在窗口排队,等师傅做好,将饭端给你,你再端到自己餐桌。
- 非阻塞式I/O:交完钱你就可以离开窗口玩一会了,窗口有个屏幕,你过一会跑过来看一下自己的饭好了没,直到饭做好,自己端到自己的餐桌。
- I/O复用:好几个同学都把饭卡交给你,你一个人跑到窗口排队刷卡,谁的饭好了,你就打电话给谁,让他自己将饭端到餐桌。
- 信号驱动式I/O:你去窗口手机刷卡后就可离开了,饭做好会通过手机通知你,然后自己过去将饭端到餐桌。
- 异步I/O:去窗口点餐后,告诉服务员你在哪个餐桌就可以离开了,饭做好,服务员会将饭帮你端到餐桌。
进程/线程分配
进程和线程的创建、调度都需要系统开销。在高并发系统中,为每个请求分配一个进程或线程会对性能产生不利影响。为了克服这个问题,高性能的网络模型通常采用进程池或线程池来管理进程或线程。进程/线程池的设计目的是降低创建和销毁进程/线程的频率,并限制系统中总进程/线程的数量,以减少内核调度的开销。
常用高性能模式
- reactor 模式
《The Design and Implementation of the Reactor》一文详细介绍了reactor模式的工作方式,简单来说,reactor模式=I/O复用 + 进程池/线程池。
- proactor模式
《Proactor: An Object Behavioral Pattern for Demultiplexing and Dispatching Handlers for Asynchronous Events》一文详细介绍了proactor模式的工作方式,简单来说,proactor模式=异步I/O+ 进程池/线程池。
惊群效应
对于TCP请求来说,最理想的情况是每个事件每次从池中唤醒一个进程或线程去执行,这样既不需要等待又不会引起竞争。用一个进程或线程专门负责处理accept事件,然后将接下来的事件继续分发给其他worker处理是可行的。有一些模型(比如nginx)存在多个进程或线程监听同一个端口的情况,如果不加处理会出现一个accept事件唤醒所有worker进程的情况,即惊群效应。为了应对惊群效应,早期nginx引入了accept_mutex的机制,竞争到锁的worker才会执行accept操作,从而避免所有worker都被唤醒。Linux3.9 版本后提供了reuseport更好的解决了多个进程或线程监听同一个端口引起的惊群问题,简单说就是内核帮你轮询,而不用在应用层面竞争了。
更快、更强大的网络模型
欲望是永无止境的,有人提出The C10K problem问题,就有人提出The C10M problem,前文中的讨论基本都是围绕用户态进程和内核的交互优化,既然和内核交互容易导致性能瓶颈,那为何不旁路掉内核协议栈呢?所以有了更快的网络方案,比如DPDK、XDP、甚至硬件加速等。
粉丝福利, 免费领取C/C++ 开发学习资料包、技术视频/项目代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发/音视频开发/Qt开发/游戏开发/Linuxn内核等进阶学习资料和最佳学习路线)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓