根据上一篇文章我们学会的如何使用请求库和编写请求函数,这一次我们来学习一下爬虫常用的小技巧。
自定义Headers
Headers是请求的一部分,包含了关于请求的元信息。我们可以在requests调用中传递一个字典来自定义Headers。代码如下
python">import requests
headers = {'User-Agent': 'My Custom User Agent','Accept': 'application/json','Authorization': 'Bearer YOUR_ACCESS_TOKEN','Content-Type': 'application/json'
}
res = requests.get(url='https://www.baidu.com/', headers=headers)
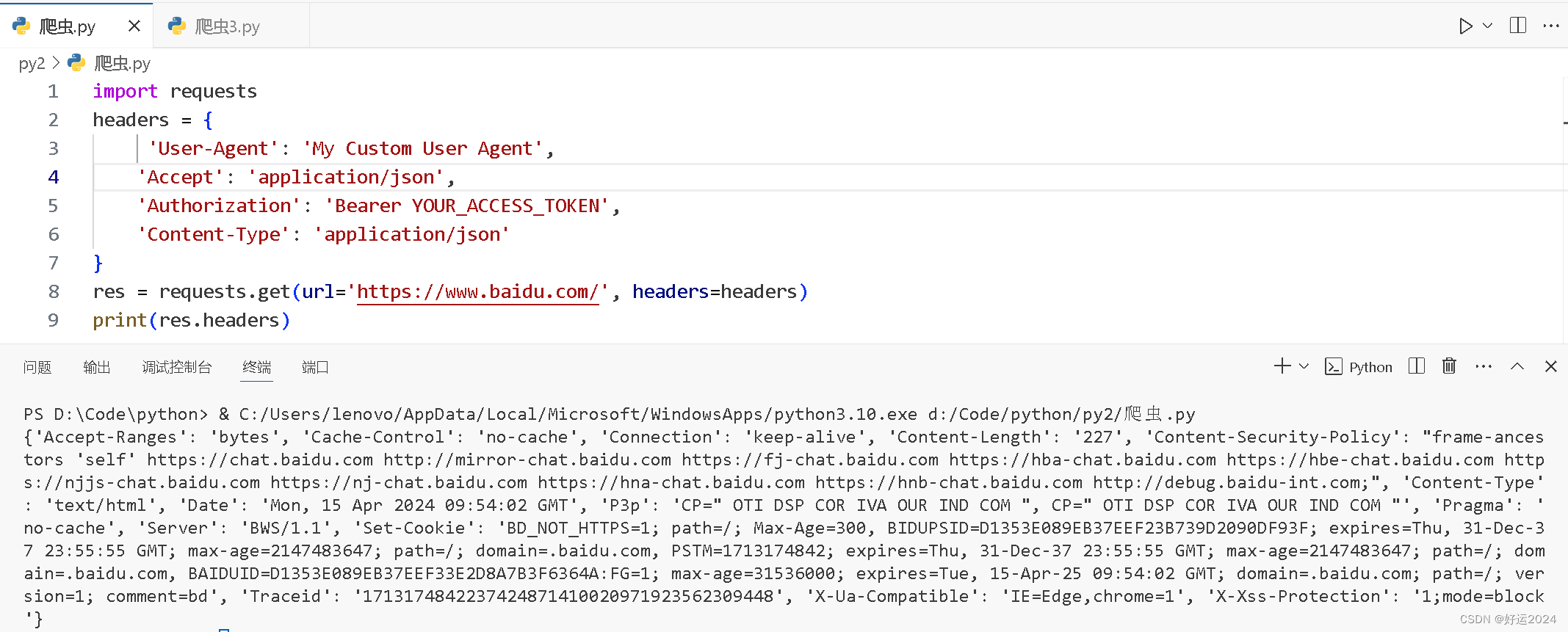
print(res.headers)输出结果
如果输出的代码看不懂,可以看下面代码对比图片读懂代码。
这些头部信息对于开发者和网络管理员来说非常重要,因为它们提供了关于服务器响应和行为的详细信息。理解这些头部可以帮助你更好地处理HTTP请求和响应,以及优化Web应用程序的性能和安全性。
python">{'Accept-Ranges': 'bytes', //指示服务器支持的请求范围类型
'Cache-Control': 'no-cache', //指定了响应的缓存策略'Connection': 'keep-alive', //指示连接是否应该在请求完成后保持打开状态'Content-Length': '227', //响应内容的字节长度
//定义了哪些内容可以被加载到页面上,以及页面可以与哪些外部资源交互。这个头部用于提高安全性,防止跨站脚本(XSS)攻击'Content-Security-Policy': "frame-ancestors 'self' https://chat.baidu.com http://mirror-chat.baidu.com https://fj-chat.baidu.com https://hba-chat.baidu.com https://hbe-chat.baidu.com https://njjs-chat.baidu.com https://nj-chat.baidu.com https://hna-chat.baidu.com https://hnb-chat.baidu.com http://debug.baidu-int.com;", 'Content-Type': 'text/html', //响应内容的媒体类型'Date': 'Mon, 15 Apr 2024 09:46:00 GMT', //响应生成的日期和时间'P3p': 'CP=" OTI DSP COR IVA OUR IND COM ", CP=" OTI DSP COR IVA OUR IND COM "', //公共隐私政策项目(P3P)的头部,用于定义网站的隐私策略'Pragma': 'no-cache', //与Cache-Control类似,Pragma是一个HTTP/1.0的缓存指令,no-cache表示响应不应该被缓存。'Server': 'BWS/1.1', //服务器软件的名称和版本'Set-Cookie': 'BD_NOT_HTTPS=1; path=/; Max-Age=300, BIDUPSID=F36C5CA8D21142BD74B5207C59287DBD; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, PSTM=1713174360; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, BAIDUID=F36C5CA8D21142BD2FFC0E76C39C86DD:FG=1; max-age=31536000; expires=Tue, 15-Apr-25 09:46:00 GMT; domain=.baidu.com; path=/; version=1; comment=bd', //设置一个或多个Cookie,用于维持用户会话、跟踪用户行为等'Traceid': '1713174360037795661812152107203751720698', //服务器为请求生成的唯一追踪ID,用于调试和日志记录'X-Ua-Compatible': 'IE=Edge,chrome=1', //指示服务器支持的浏览器兼容性'X-Xss-Protection': '1;mode=block'} //浏览器的安全头部,用于启用XSS保护机制
自定义Cookies
Cookies通常用于维持用户的会话状态。我们可以通过cookies参数在requests调用中传递一个RequestsCookieJar对象或者一个字典来自定义Cookies。代码如下
python"># 导入requests库
import requests
# 自定义cookies
cookies = {'cookies_are':'working'}
# 发起请求
res = requests.get(url='http://httpbin.org/cookies', cookies=cookies)
# 打印响应内容
print(res.text)这个代码主要用来维持会话状态
输出结果

提示:自定义Cookies在爬虫中通常用于维持会话(如登录)、绕过防爬机制、跟踪用户行为、处理Cookies限制等。
重定向(allow_redirects)
在HTTP请求中,重定向是指服务器指示客户端去访问另一个URL的响应。重定向是一种常见的Web机制,用于URL变更、负载均衡、内容移动等场景。
HTTP状态码中,301(Moved Permanently)、302(Found)、303(See Other)、307(Temporary Redirect)和308(Permanent Redirect)都是表示重定向的响应码
在网络请求中,我们常常会遇到状态码是3开头的重定向问题,在Requests中是默认开启允许重定向的,即遇到重定向时,会自动继续访问,这个行为由llow_redirects参数来控制。
使用
allow_redirects参数的场景包括:
- 当你知道URL已经更新,并且想要直接访问新URL时,可以禁用重定向,以获取重定向响应中的新URL。
- 当你需要分析重定向链时,可以通过禁用重定向并检查
response.history来获取所有的重定向记录。- 当服务器返回的重定向可能包含敏感信息或不安全的内容时,禁用重定向可以防止客户端无意中访问这些URL。
通过灵活使用
allow_redirects参数,可以更好地控制requests库的行为,以适应不同的网络请求场景。
重定向是一种服务器端行为,它通过将用户的请求从一个URL重定向到另一个URL来提供更好的用户体验和管理网站内容。重定向可以有以下作用:
-
网站更改:当网站管理员决定更改网站的URL结构或移动页面时,重定向可以确保现有的链接仍然有效,并将用户正确地引导到新的位置。
-
域名重定向:当网站有多个域名时,可以使用重定向将用户引导到主要域名,以确保所有流量都指向一个位置。
-
防止重复内容:重定向可以确保用户访问正确的标准化URL,从而避免搜索引擎索引多个相同内容的URL。
-
统一资源:对于移动设备和桌面设备,可以使用重定向将用户引导到适合其设备的不同版本的网站。
在网络编程中,允许重定向可以确保客户端能够跟随服务器发送的重定向指令,从而获得正确的资源。
简单代码如下
python">#导入requests模块
import requests
#发送请求 允许重定向
response = requests.get('http://example.com', allow_redirects=True)
#输出响应内容
print(response.url)
注意:重定向(False=关闭重定向,True=开启重定向
输出结果:
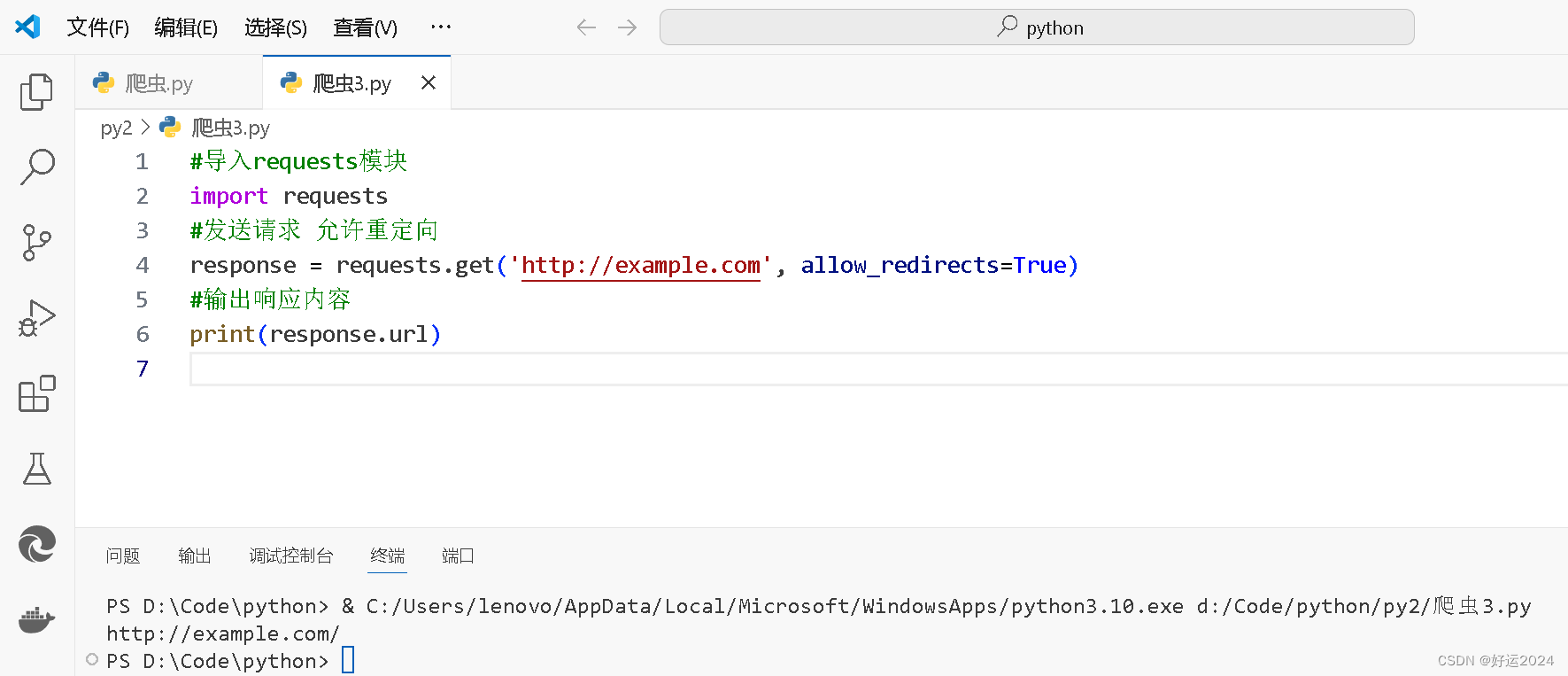
最后一行打印出了响应的URL,这对于检查是否发生了重定向是很有用的。
重定向有许多操作,这里选用一个简单的部分,能够让大家一眼看懂
禁止证书验证(verify)
在爬虫过程中,SSL证书是用于在客户端(爬虫)和服务器之间建立安全通信的重要工具。而需要SSL证书验证有以下原因:
-
数据加密: SSL证书确保了客户端和服务器之间的数据传输是加密的。这意味着即使数据在传输过程中被拦截,攻击者也无法轻易读取或修改数据内容。
-
身份验证: SSL证书还用于验证服务器的身份。当爬虫访问一个使用SSL证书的服务器时,它可以检查证书是否由受信任的证书颁发机构(CA)签发,以及证书中的信息是否与服务器声称的身份匹配。这有助于防止中间人攻击和欺诈网站。
-
信任和声誉: 使用有效的SSL证书可以提高网站的信誉和用户的信任度。对于爬虫来说,确保与信任的服务器通信可以提高爬取数据的质量和安全性。
-
遵守法规: 某些法律法规要求网站和服务必须使用SSL证书来保护用户数据。作为爬虫开发者,遵守这些法规可以避免潜在的法律问题。
-
浏览器和库的要求: 现代浏览器和网络库(如
requests)默认要求使用SSL证书。如果没有有效的证书或证书验证失败,浏览器和库可能会拒绝连接或发出警告。 -
防止数据泄露: SSL证书有助于防止敏感数据(如登录凭据、个人信息等)在传输过程中被窃取。这对于爬取可能包含敏感信息的网站尤为重要。
简单案例代码
python">import requests# 关闭SSL证书验证
response = requests.get('https://www.baidu.com/', verify=False)这个代码用来关闭证书验证,通常情况下,不建议关闭,除非你信任这个网络环境,否则可能会数据泄密或者中间人攻击。大家自行验证即可😎(っ °Д °;)っ
输出结果
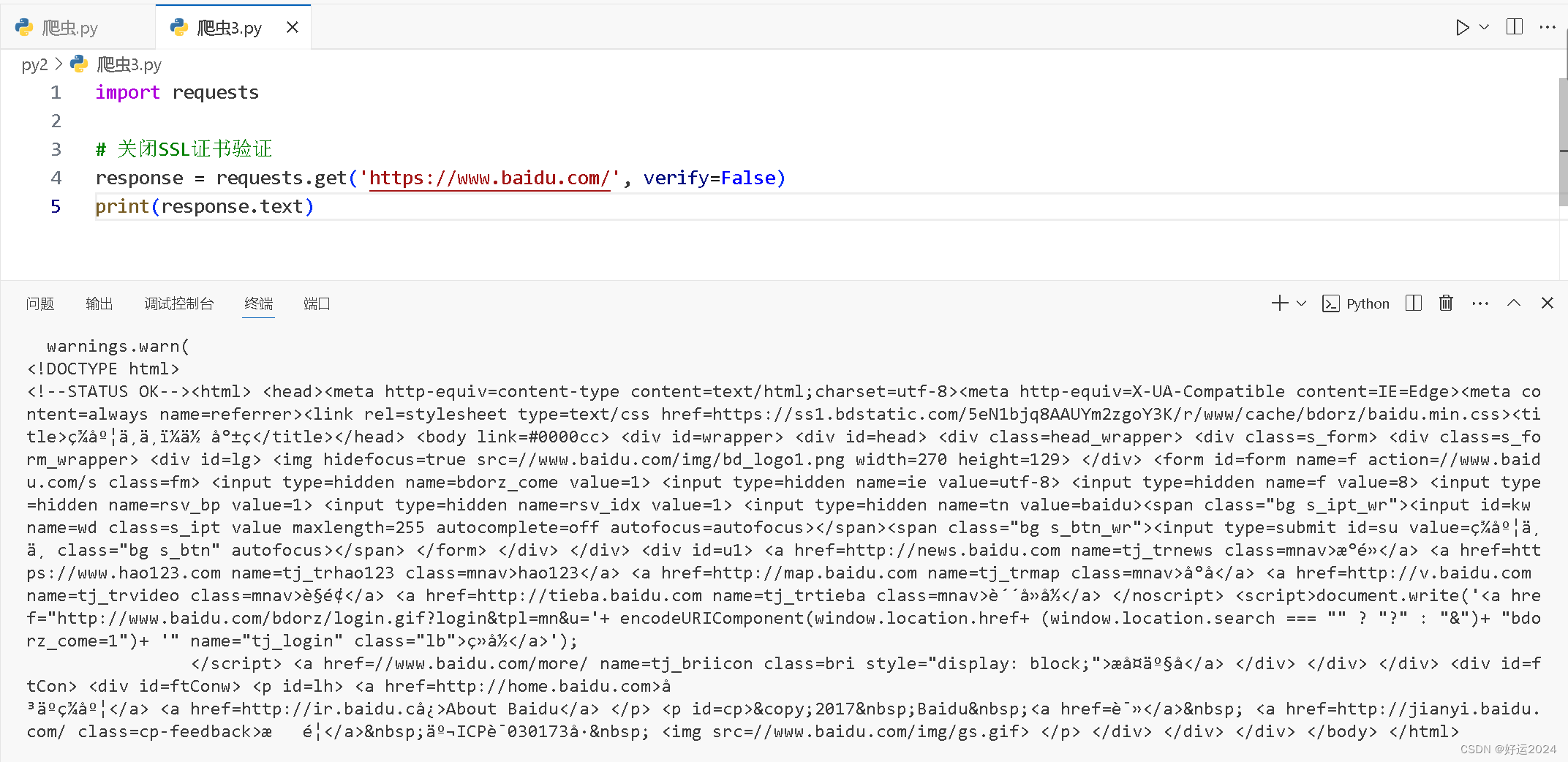
解释:输出的信息包含以下内容
-
InsecureRequestWarning: 这是一个警告,由
urllib3库发出,提示你的HTTPS请求没有进行证书验证。在Python 3中,如果你使用urllib3库进行HTTPS请求,而没有指定cert_reqs='CERT_REQUIRED'来启用证书验证,就会收到这个警告。这是因为没有证书验证的HTTPS请求容易受到中间人攻击(MITM),所以强烈建议启用证书验证以保证通信安全。 -
警告链接: 警告信息中提供了一个链接,指向
urllib3的官方文档,其中详细介绍了如何处理SSL警告和如何配置证书验证。 -
HTML内容: 这部分是百度首页的HTML源码片段。它包含了百度的登录链接、搜索框、导航链接以及其他一些页面元素。这个HTML片段可能是从网络请求的响应中提取出来的
设置超时(timeout)
超时时间应该根据目标服务器的响应速度和网络状况来合理设置。过短的超时时间可能导致不必要的超时异常,而过长的超时时间可能会导致爬虫效率降低。因此要合理设置,提高爬虫效率
python">import requests
# 设置超时
requests.get('https://www.baidu.com/', timeout=10)
print('ok')输出结果
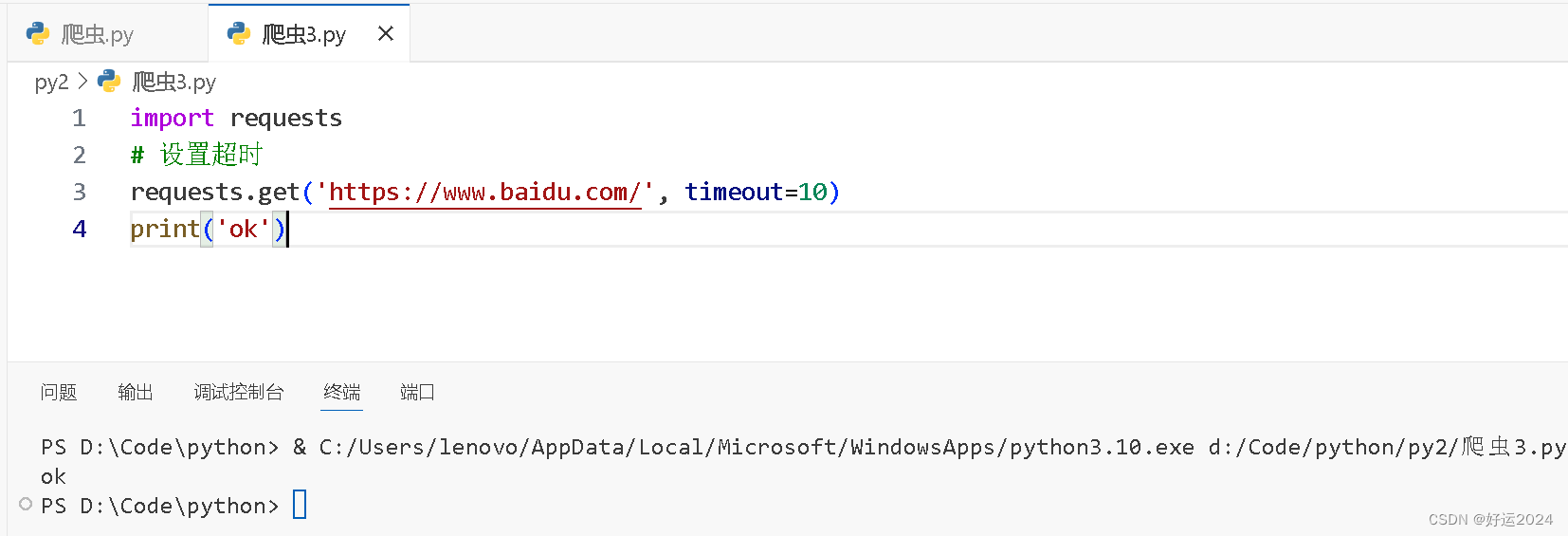
这表示爬虫没有超时,并成功响应信息。
 好了今日分享到此一游,各位点个赞,关注我不迷路
好了今日分享到此一游,各位点个赞,关注我不迷路