大家好,我们平时在做UI自动化测试的时候,经常会用到Chrome浏览器的无头模式(无界面模式),并且将测试代码部署到Linux系统中执行,或者平时我们写个爬虫爬取网站的数据也会使用到,接下来和大家分享一下在Linux系统中使用Chrome无头模式。
关于Linux常用命令,大家可以参考:作为测试人员的Linux常用命令
一、在Linux上安装Chrome浏览器
1、首先要先安装Chrome浏览器所需要的依赖包
yum install -y wget unzip libX11 GConf2 fontconfig安装完成后如下图:

2、下载Chrome浏览器
cd /opt
wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm

3、下载完成后通过yum安装
yum install -y google-chrome-stable_current_x86_64.rpm安装完成后如下图:
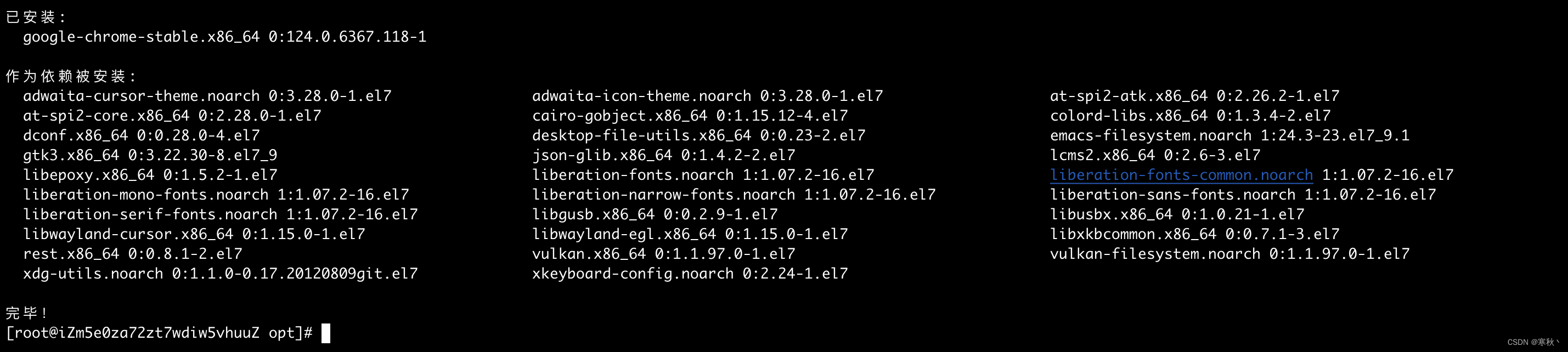
查看Chrome浏览器的版本,下载对应的webdriver,此处的浏览器版本为:124.0.6367.118
google-chrome --version
二、安装Chrome WebDriver
Chrome WebDriver下载地址(浏览器版本114之前):
https://chromedriver.storage.googleapis.com/index.html
Chrome WebDriver下载地址(浏览器版本123以后):
Chrome for Testing availability
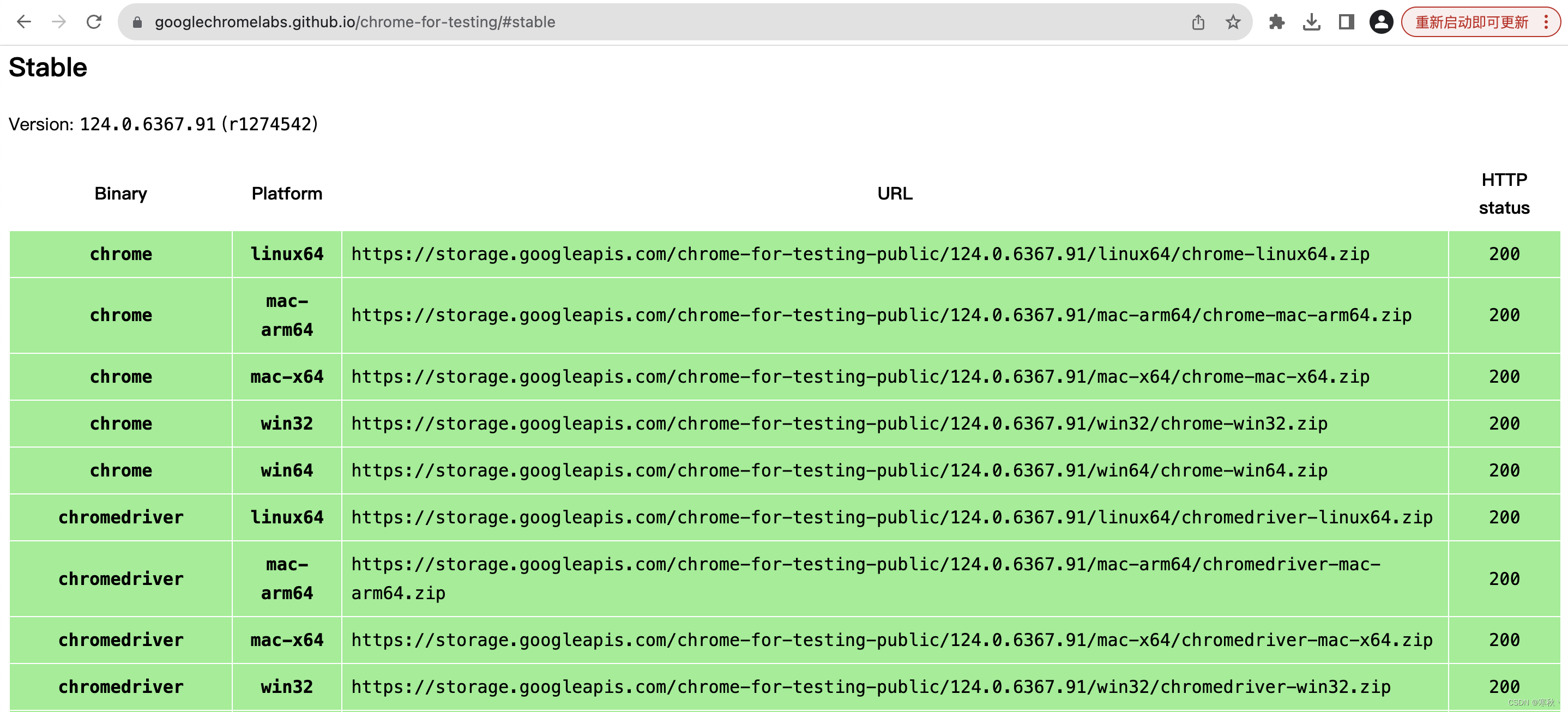
找到对应版本的WebDriver进行linux版本的下载,有时候没有对应版本的chromedriver则安装低一个版本的也可以。
此处,我得Chrome浏览器版本为 124.0.6367.118,找到对应版本的linux安装包,但是被标红显示HTTP status 是404了,无法下载。
 只能选择低一个版本的下载了
只能选择低一个版本的下载了
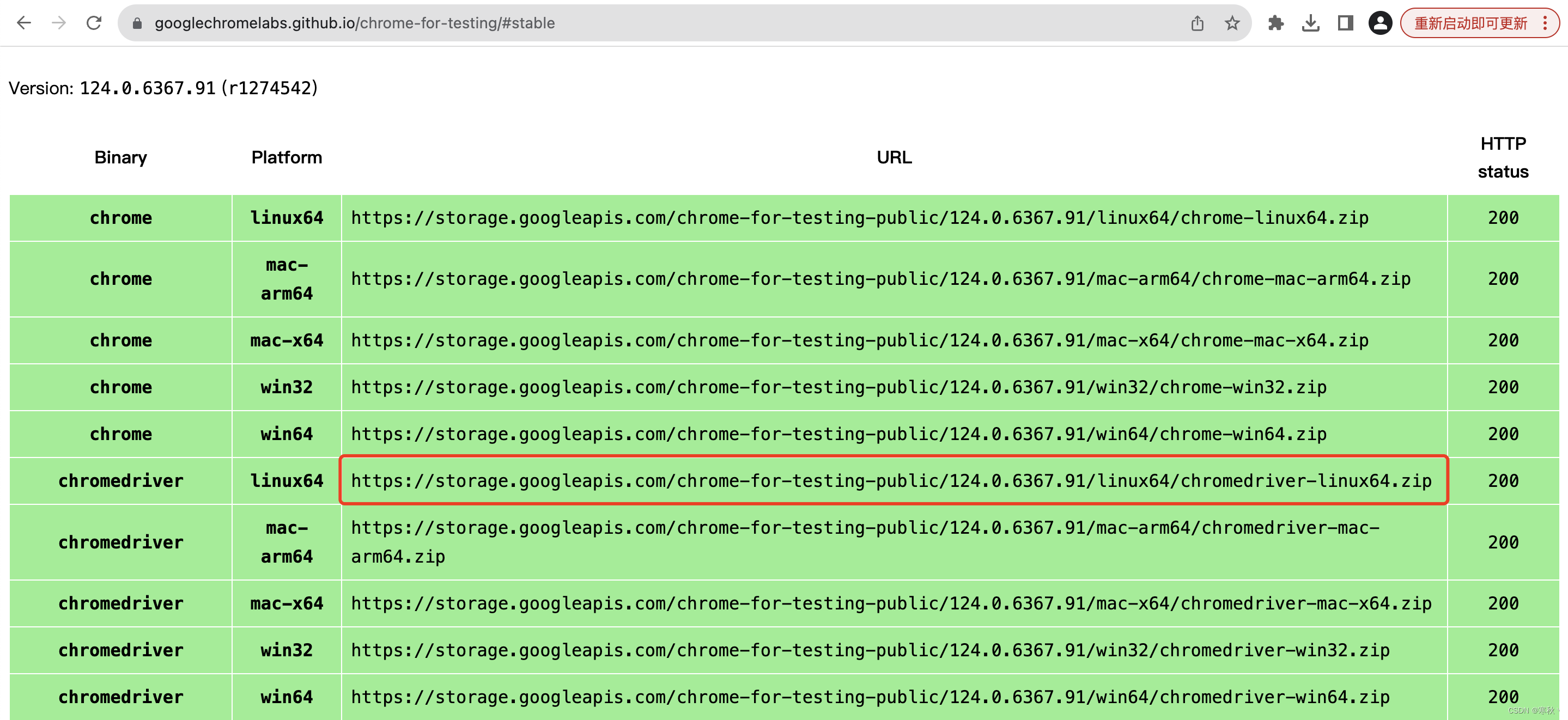
复制下载链接,在linux系统中直接下载,或者本机下载完成后上传到服务器也可以。
wget https://storage.googleapis.com/chrome-for-testing-public/124.0.6367.91/linux64/chromedriver-linux64.zip
下载完成后,对压缩包进行解压
unzip chromedriver_linux64.zip 解压完成后,出现一个相同名字的目录
解压完成后,出现一个相同名字的目录

进入到目录中可以看到浏览器驱动文件

将解压后的 chromedriver 移动或者复制到 /usr/local/bin/ 目录下
mv chromedriver /usr/local/bin/验证ChromeWebDriver是否安装成功
chromedriver --version
三、配置Python3环境
此处省略,参考:Linux安装Python3.9环境
四、安装selenium
pip3 install selenium
安装完成后如下图:

五、编写脚本
创建一个python文件,命名为chrome_test.py
touch chrome_test.py通过vi编辑器编辑文件
vi chrome_test.py文件内容如下:
python"># -*- coding:utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionsoptions = Options()
# 启用无头模式
options.add_argument('--headless')options.add_argument('--no-sandbox')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--remote-debugging-port=9222')
# 创建 WebDriver 对象
driver = webdriver.Chrome(options=options)
print('以无头模式驱动浏览器')
# 打开百度首页
driver.get(url='https://www.baidu.com')
print('访问百度')
# 关闭浏览器
driver.quit()
print('关闭浏览器')编辑完成后,保存文件。
六、运行脚本
python">python3 chrome_test.py运行后,出现下面报错,原因是因为我本机的 urllib3 和 ssl 模块之间的版本不匹配,需要对 urllib3 模块进行降级。
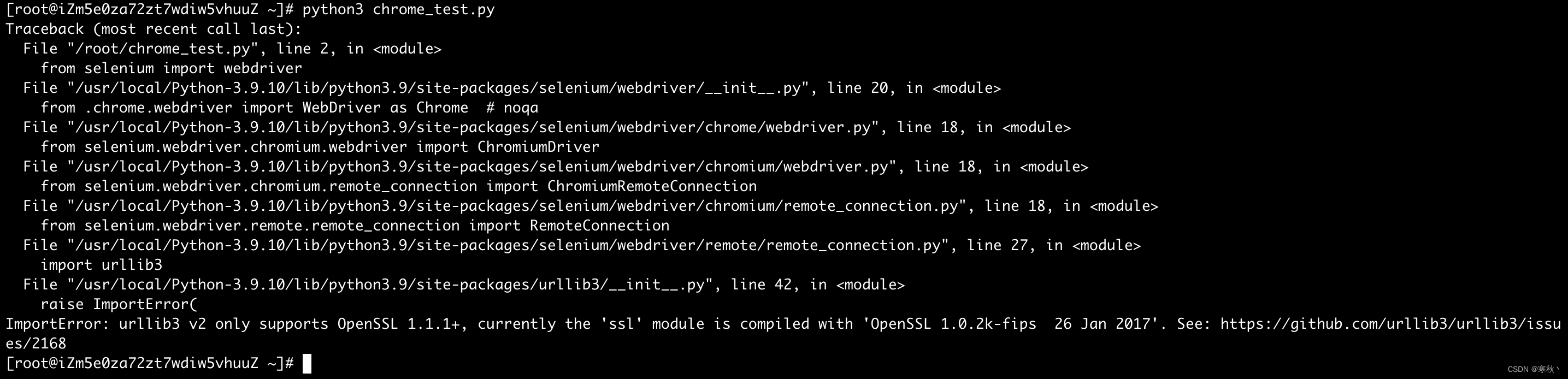
降级urllib3模块的版本
python">pip3 install urllib3==1.26.7
降级完成后,重新运行脚本。

运行成功!大功告成!!