文本匹配是指计算机系统识别和确定两段文本之间关系的任务。这个概念非常广泛,涵盖了各种场景,其中文本之间的关系可以是有相似度、问答、对话、推理等。在不同的应用场景下,文本匹配的具体定义可能会有所不同。
以下是几种常见的文本匹配任务及其特点:
- 文本相似度计算:计算两个文本之间的相似程度,例如判断两个句子是否表达相同或相似的意思。
- 问答匹配:将用户提出的问题与数据库中的答案进行匹配,以提供正确的信息。
- 对话匹配:在对话系统中,识别用户输入的文本与系统回复之间的匹配关系,以确保对话的连贯性和准确性。
- 文本推理:根据给定的文本内容推断出新的信息或结论。
此外,像抽取式机器阅读理解和多项选择这样的任务,其本质也是文本匹配。在这些任务中,系统需要理解文本内容,并将其与问题或选项进行匹配,以确定正确答案。
总之,文本匹配是自然语言处理中的一个重要概念,广泛应用于信息检索、机器翻译、文本生成、对话系统等多个领域。随着技术的发展,文本匹配的算法和模型也在不断进步,以更准确地理解和匹配文本内容。
本次先介绍最简单的文本相似度计算的任务,后面将其他的信息检索、机器翻译、文本生成、对话系统等任务进行实战。
基本步骤:
1 加载数据集
在hugging face没有找到合适的数据集,所以找了一个资源上传在git上,大家可自取
dataset = load_dataset("json", data_files="/kaggle/input/sentence/sentence_pair.json", split="train")
dataset
Dataset({features: ['sentence1', 'sentence2', 'label'],num_rows: 10000
})
看下数据格式
dataset[10]
{'sentence1': '她是一个非常慷慨的女人,拥有自己的一大笔财产。','sentence2': '她有很多钱,但她是个慷慨的女人。','label': '1'}
2 数据预处理
datasets = dataset.train_test_split(test_size=0.2)
datasets
DatasetDict({train: Dataset({features: ['sentence1', 'sentence2', 'label'],num_rows: 8000})test: Dataset({features: ['sentence1', 'sentence2', 'label'],num_rows: 2000})
})
数据格式划分
import torchtokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")def process_function(examples):tokenized_examples = tokenizer(examples["sentence1"], examples["sentence2"], max_length=128, truncation=True)tokenized_examples["labels"] = [int(label) for label in examples["label"]]return tokenized_examplestokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets
原始数据中label是字符串格式,需要int转换下
print(tokenized_datasets["train"][0])
{'input_ids': [101, 704, 1286, 1762, 100, 4638, 2207, 2238, 828, 2622, 8024, 4692, 4708, 1920, 6496, 1403, 3777, 6804, 6624, 1343, 511, 102, 1762, 100, 7353, 6818, 3766, 3300, 1920, 6496, 511, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'labels': 0}
3 加载模型
from transformers import BertForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese")
4 创建评估函数
import evaluateacc_metric = evaluate.load("accuracy")
f1_metirc = evaluate.load("f1")def eval_metric(eval_predict):predictions, labels = eval_predictpredictions = predictions.argmax(axis=-1)acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metirc.compute(predictions=predictions, references=labels)acc.update(f1)return acc
5 创建训练器
train_args = TrainingArguments(output_dir="./cross_model", # 输出文件夹per_device_train_batch_size=32, # 训练时的batch_sizeper_device_eval_batch_size=32, # 验证时的batch_sizelogging_steps=10, # log 打印的频率evaluation_strategy="epoch", # 评估策略save_strategy="epoch", # 保存策略save_total_limit=3, # 最大保存数learning_rate=2e-5, # 学习率weight_decay=0.01, # weight_decaymetric_for_best_model="f1", # 设定评估指标report_to=['tensorboard'],load_best_model_at_end=True) # 训练完成后加载最优模型
train_args
6 开始训练
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model, args=train_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], data_collator=DataCollatorWithPadding(tokenizer=tokenizer),compute_metrics=eval_metric)trainer.train()
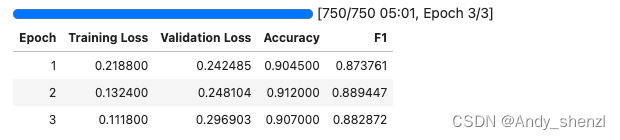
TrainOutput(global_step=750, training_loss=0.1850536205768585, metrics={'train_runtime': 302.9995, 'train_samples_per_second': 79.208, 'train_steps_per_second': 2.475, 'total_flos': 1552684115443200.0, 'train_loss': 0.1850536205768585, 'epoch': 3.0})
7 评估
trainer.evaluate(tokenized_datasets["test"])
{'eval_loss': 0.2481037676334381,'eval_accuracy': 0.912,'eval_f1': 0.8894472361809046,'eval_runtime': 7.6159,'eval_samples_per_second': 262.61,'eval_steps_per_second': 8.272,'epoch': 3.0}
8 预测
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
result = pipe({"text": "昨天我做了个梦", "text_pair": "下雨了"})
result
{'label': '不相似', 'score': 0.989981472492218}
补充
上面是用分类的方式进行训练的,这里有个问题就是如果我们呢需要对一个句子去喝多个句子进行匹配找出最相似的句子就不行了,因为上面这种方式的结果没有对比的价值。所以我们需要修改下,使用MSE来计算损失。
需要修改的地方主要是两个,
数据预处理
def process_function(examples):tokenized_examples = tokenizer(examples["sentence1"], examples["sentence2"], max_length=128, truncation=True)tokenized_examples["labels"] = [float(label) for label in examples["label"]]return tokenized_examples
计算MSE需要计算损失的具体数值,所以要转换成浮点型
评估函数
def eval_metric(eval_predict):predictions, labels = eval_predictpredictions = [int(p > 0.5) for p in predictions]labels = [int(l) for l in labels]# predictions = predictions.argmax(axis=-1)acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metirc.compute(predictions=predictions, references=labels)acc.update(f1)return acc
预测的是一个具体的数值,不是【0,1】,所以计算准确率时要转换下
模型
num_labels=1
num_labels改为一,用回归的形式去预测
完整代码