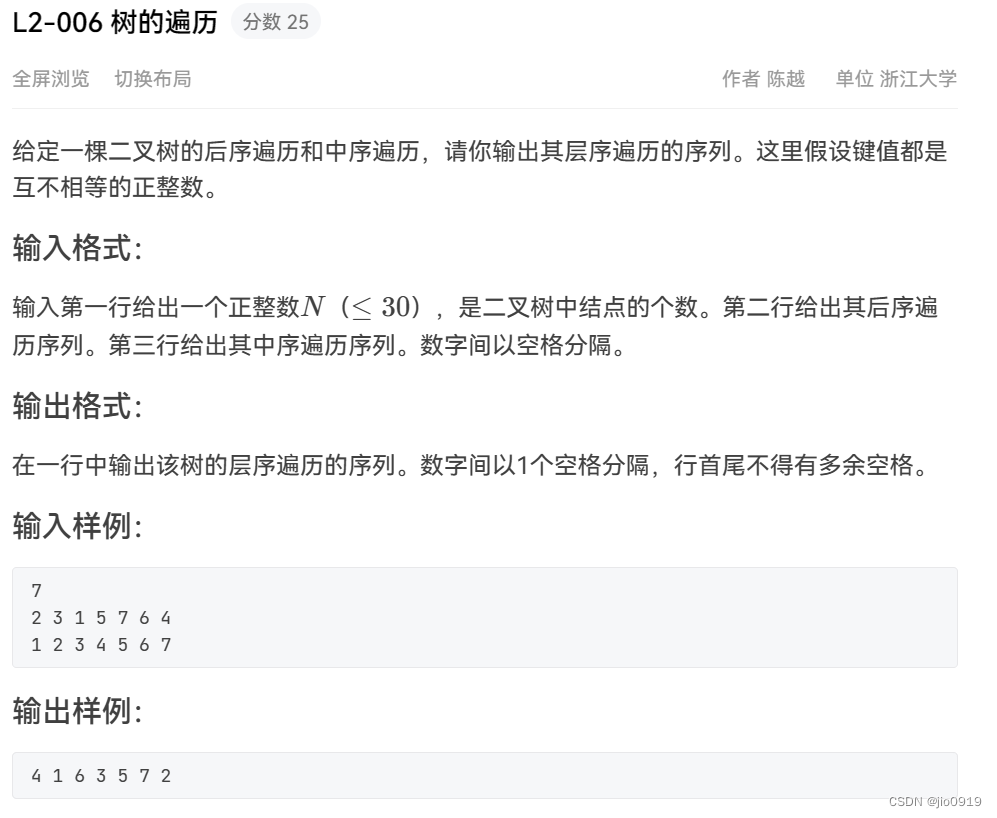
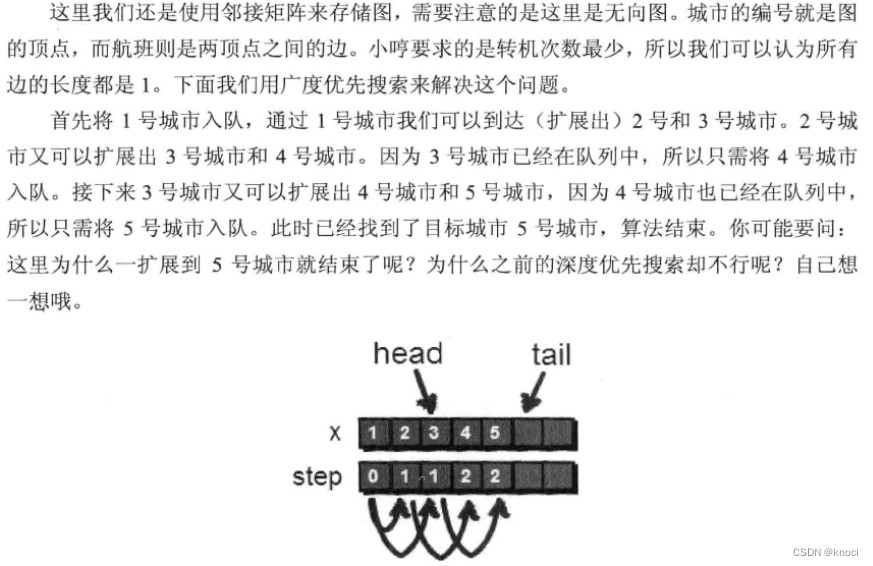
以下是我在文心一言获得的答案
我的疑问是:文件的每一行是一条完整的请求数据,文件分块会不会破坏一行的数据呢?
文件的每一行是一条完整的请求数据,当我们将文件按照行分块时,是不会破坏单行数据的完整性的。这是因为我们按照行的结束符(通常是换行符
\n)来划分数据块。只要确保在分块时正确处理行的结束,就可以保证每一行数据的完整性。在Go语言中,使用
bufio.Scanner进行逐行读取是一个很好的方式,因为它内部会处理好行的结束符。当你调用scanner.Scan()时,它会读取直到下一个换行符,并将当前行的内容存储在scanner.Text()中。因此,你不需要担心分块会破坏行的完整性。如果你使用其他方法进行分块,比如按固定大小的字节块来读取文件,那么你需要确保在分割时不会切断任何行的数据。这通常意味着你需要在读取到换行符之前不要分割块,或者在分割后重新组合被切断的行。
但是,使用
bufio.Scanner进行逐行读取,并按照行来分块,可以确保每行数据的完整性,因为bufio.Scanner已经为你处理了这些细节。下面是一个简化的例子,展示了如何使用
bufio.Scanner来按行读取文件,并将行分配到不同的块中:
package main import ( "bufio" "fmt" "os" "sync"
) // 处理一个数据块的函数
func processChunk(chunk []string, wg *sync.WaitGroup) { defer wg.Done() // 在这里处理数据块中的每一行 for _, line := range chunk { // 假设这里是对请求数据的处理逻辑 fmt.Println(line) }
} func main() { filename := "requests.txt" // 包含请求数据的文件名 chunkSize := 100 // 每个数据块包含的行数 var wg sync.WaitGroup file, err := os.Open(filename) if err != nil { panic(err) } defer file.Close() scanner := bufio.NewScanner(file) var chunk []string var lineCount int for scanner.Scan() { line := scanner.Text() chunk = append(chunk, line) lineCount++ if len(chunk) == chunkSize || scanner.Err() != nil { wg.Add(1) go processChunk(chunk, &wg) chunk = []string{} // 重置块以便存储新的行 lineCount = 0 } } if len(chunk) > 0 { wg.Add(1) go processChunk(chunk, &wg) } wg.Wait() // 等待所有goroutine完成
}