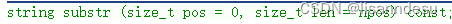论文地址:https://arxiv.org/abs/2305.13661![]() https://arxiv.org/abs/2305.13661
https://arxiv.org/abs/2305.13661
1.概述
研究首先识别了大型语言模型(LLM)在生成误导性信息方面的潜在问题,并通过一系列模型揭示了这些问题如何影响开放领域问答(ODQA)系统的准确性和可靠性。如下图所示,威胁模型清晰地展示了两种主要风险:恶意用户故意利用LLM散播错误信息,以及常规用户在无意中通过LLM获取误导性答案。
研究提出了三种针对性解决策略以应对LLM可能导致的知识库污染:
-
错误信息检测:开发技术来自动识别由LLM生成的潜在误导性内容。
-
警觉提示:优化模型的提示机制,以减少误导性输出的风险。
-
阅读器集成:通过集成多种阅读模型来检验和验证信息,增强系