在数据分析领域,Python的Pandas库是一个不可或缺的工具。它提供了高效的数据结构和数据分析工具,使得数据处理变得简单而直观。本文将详细介绍Pandas库的基本功能、常见用法,并通过示例代码演示如何使用Pandas进行数据处理。最后,我将用表格的形式梳理总结Pandas库的常用函数及其参数用法。资源绑定附上完整资源供读者参考学习!
一、Pandas库简介
1.1 什么是Pandas?
Pandas是一个开源的Python库,专为数据分析而设计。它提供了两种主要的数据结构:Series(一维数组)和DataFrame(二维表格),使得数据处理更加高效和便捷。
1.2 Pandas的主要特点
-
数据结构:提供了
Series和DataFrame两种数据结构,适合处理结构化数据。 -
数据读取:支持多种数据格式的读取,如CSV、Excel、SQL数据库等。
-
数据清洗:提供了处理缺失值、重复值、异常值等功能。
-
数据转换:支持数据的筛选、排序、分组、聚合等操作。
-
数据可视化:集成了Matplotlib,方便进行数据可视化。
1.3 Pandas的应用场景
-
数据分析:用于清洗、转换和分析数据。
-
数据科学:在数据科学项目中进行数据预处理。
-
金融分析:处理时间序列数据和金融数据。
-
机器学习:作为数据预处理工具,为机器学习模型提供输入数据。
二、Pandas库的常见用法
2.1 安装和导入Pandas
Python
# 安装Pandas
pip install pandas# 导入Pandas
import pandas as pd2.2 数据读取
2.2.1 读取CSV文件
Python
python">import pandas as pd
# 读取CSV文件
df = pd.read_csv('2001-2017年北京市水资源情况信息.csv',encoding='gbk')# 显示前5行数据
print(df.head())

2.2.2 读取Excel文件
Python
python">
# 读取Excel文件
df = pd.read_excel('data.xlsx')# 显示前5行数据
print(df.head())
2.3 数据的基本操作
2.3.1 查看数据结构
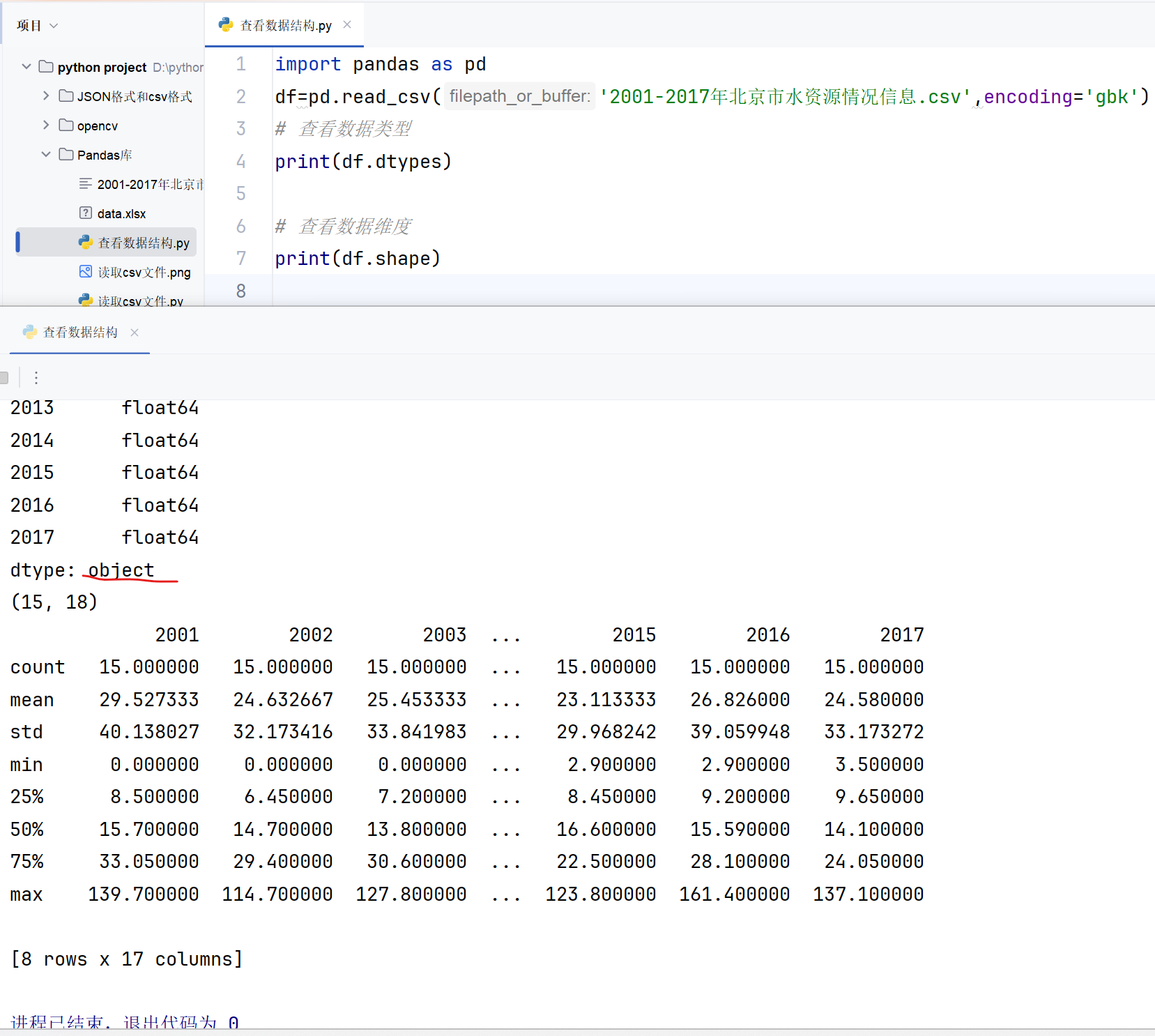
Python
python">import pandas as pd
df=pd.read_csv('2001-2017年北京市水资源情况信息.csv',encoding='gbk')
# 查看数据类型
print(df.dtypes)# 查看数据维度
print(df.shape)# 查看数据描述性统计
print(df.describe())
2.3.2 筛选数据
Python
python">import pandas as pd
df=pd.read_excel('data.xlsx')
# 按列名筛选
print(df['姓名'])# 按条件筛选
print(df[df['总成绩'] > 90])# 多条件筛选
print(df[(df['平时成绩'] > 90) & (df['总成绩'] >90)])
2.3.3 排序数据
Python
python">import pandas as pd
df=pd.read_excel('data.xlsx')
# 按某一列排序
df_sorted = df.sort_values(by='总成绩', ascending=False)
print(df_sorted)# 按多列排序
df_sorted = df.sort_values(by=['平时成绩', '总成绩'], ascending=[False, True])
print(df_sorted)
2.4 数据清洗
2.4.1 处理缺失值
Python
python">import pandas as pd
df=pd.read_excel('data.xlsx')
# 查看缺失值
print(df.isnull().sum())# 删除缺失值
df_cleaned = df.dropna()# 填充缺失值
df_filled = df.fillna(value=0)
2.4.2 处理重复值
Python
python">import pandas as pd
df=pd.read_excel('data.xlsx')
# 查找重复值
print(df.duplicated())# 删除重复值
df_unique = df.drop_duplicates()

2.4.3 处理异常值
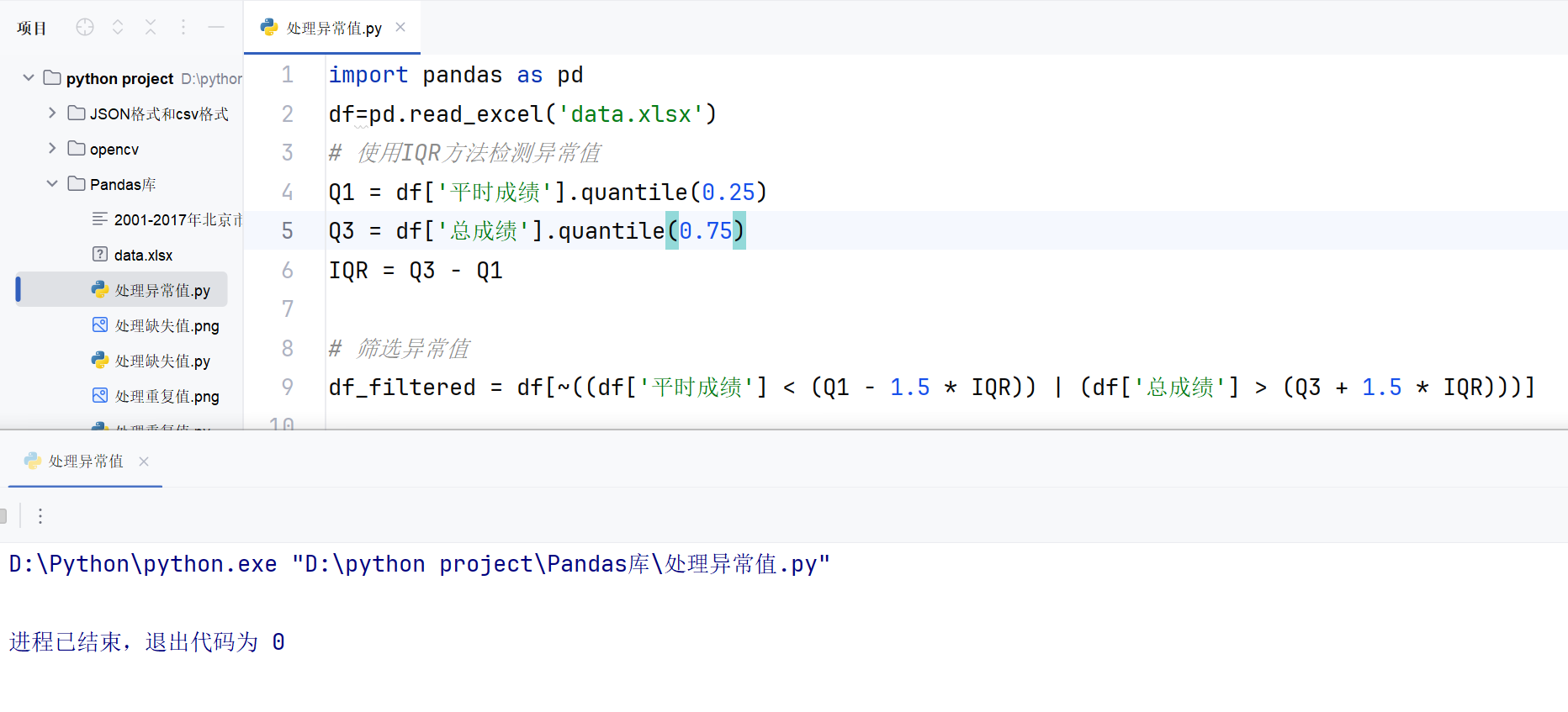
Python
python">import pandas as pd
df=pd.read_excel('data.xlsx')
# 使用IQR方法检测异常值
Q1 = df['平时成绩'].quantile(0.25)
Q3 = df['总成绩'].quantile(0.75)
IQR = Q3 - Q1# 筛选异常值
df_filtered = df[~((df['平时成绩'] < (Q1 - 1.5 * IQR)) | (df['总成绩'] > (Q3 + 1.5 * IQR)))]
2.5 数据可视化
2.5.1 绘制柱状图
Python
python">import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
df=pd.read_excel('data.xlsx')df['总成绩'].value_counts().plot(kind='bar')
plt.show()

2.5.2 绘制折线图
Python
python">import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
df=pd.read_excel('data.xlsx')df.plot(x='姓名', y='平时成绩', kind='line')
plt.show()
2.5.3 绘制散点图
Python
python">import pandas as pd
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
df=pd.read_excel('data.xlsx')df.plot(x='学院', y='总成绩', kind='scatter')
plt.show()
三、Pandas常用函数及参数总结
| 函数 | 参数 | 说明 | 示例 |
|---|---|---|---|
read_csv | filepath, sep, header | 读取CSV文件 | pd.read_csv('data.csv', sep=',', header=0) |
read_excel | filepath, sheet_name | 读取Excel文件 | pd.read_excel('data.xlsx', sheet_name='Sheet1') |
read_sql_query | sql, con | 从SQL数据库读取数据 | pd.read_sql_query("SELECT * FROM table", conn) |
head | n | 显示前n行数据 | df.head(5) |
tail | n | 显示后n行数据 | df.tail(5) |
describe | include, exclude | 显示数据的描述性统计 | df.describe(include='all') |
dtypes | - | 显示数据类型 | df.dtypes |
shape | - | 显示数据维度 | df.shape |
sort_values | by, ascending | 按列排序 | df.sort_values(by='column', ascending=False) |
groupby | by | 按列分组 | df.groupby('column') |
sum | axis, numeric_only | 求和 | df.sum(axis=0, numeric_only=True) |
mean | axis, numeric_only | 求平均值 | df.mean(axis=0, numeric_only=True) |
dropna | axis, how, thresh | 删除缺失值 | df.dropna(axis=0, how='any', thresh=2) |
fillna | value, method | 填充缺失值 | df.fillna(value=0, method='ffill') |
duplicated | subset, keep | 查找重复值 | df.duplicated(subset=['column1', 'column2'], keep='first') |
drop_duplicates | subset, keep | 删除重复值 | df.drop_duplicates(subset=['column1', 'column2'], keep='first') |
value_counts | normalize, dropna | 计算唯一值的频率 | df['column'].value_counts(normalize=True, dropna=False) |
plot | x, y, kind | 绘制图表 | df.plot(x='column1', y='column2', kind='scatter') |
四、总结
Pandas库是Python数据分析的核心工具之一,提供了丰富的功能和便捷的操作方式。通过本文的介绍和示例代码,相信你已经对Pandas库有了初步的了解。以下是Pandas库的主要优势:
-
高效的数据结构:
Series和DataFrame使得数据处理更加直观和高效。 -
丰富的数据操作:支持数据读取、清洗、转换、分析和可视化等多种操作。
-
广泛的适用性:适用于数据分析、数据科学、金融分析等多个领域。
希望本文能帮助你更好地理解和使用Pandas库,提高数据分析的效率和质量。如果你有任何问题或建议,欢迎在评论区留言!资源绑定附上完整资源供读者参考学习!

![[Mac]利用Hexo+Github Pages搭建个人博客](https://i-blog.csdnimg.cn/direct/4cd015aa99d0421f8087b872b9ea6170.png)


