Windows下AMD显卡在本地运行大语言模型
- 本人电脑配置
- 第一步先在官网确认自己的 AMD 显卡是否支持 ROCm
- 下载Ollama安装程序
- 模型下载位置更改
- 下载 ROCmLibs
- 先确认自己显卡的gfx型号
- 下载
- 解压
- 替换
- 替换rocblas.dll
- 替换library文件夹下的所有
- 重启Ollama
- 下载模型
- 运行效果
本人电脑配置
| CPU | i5-12600KF |
|---|---|
| 内存 | 32 GB |
| 显卡 | AMD Radeon RX 6750 GRE 12GB |
第一步先在官网确认自己的 AMD 显卡是否支持 ROCm
官网地址:https://rocm.docs.amd.com/projects/install-on-windows/en/develop/reference/system-requirements.html
 如果自己的显卡在官网列表上只需要下载并安装 AMD 官方版本的 ROCm 和 Ollama 的官方版本就能直接使用。
如果自己的显卡在官网列表上只需要下载并安装 AMD 官方版本的 ROCm 和 Ollama 的官方版本就能直接使用。
下载Ollama安装程序
由于本人的AMD显卡不在官网支持的ROCm列表上,所以下载
下载地址:https://github.com/likelovewant/ollama-for-amd/releases

下载安装即可
模型下载位置更改
Ollama默认下载位置是C盘,如果C盘没有足够的空间那就需要更改下载位置
设置系统环境变量即可(用户变量与系统变量都要新建)

下载 ROCmLibs
先确认自己显卡的gfx型号
通过如下链接查询
https://www.techpowerup.com/


下载
下载链接:https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU/releases
寻找符合自己显卡型号的下载,注意要下载符合你安装Ollama版本支持的hipsdk

解压
解压下载的ROCmLibs压缩包之后会得到一个dll与一个文件夹

替换
替换rocblas.dll
将解压之后的rocblas.dll替换到Ollama安装目录下的C:\Users\ctl456\AppData\Local\Programs\Ollama\lib\ollama(路径根据自己实际的安装目录)

替换library文件夹下的所有
将解压之后的library文件夹下的所有文件替换Ollama安装目录下的
C:\Users\ctl456\AppData\Local\Programs\Ollama\lib\ollama\rocblas\library

重启Ollama
重启Ollama之后查看日志可以发现已经可以识别到显卡

下载模型
完成如上的操作之后就可以下载模型并运行了
操作命令可以查看官网:https://registry.ollama.ai/library/deepseek-r1:14b

由于国内的原因下载模型可能会遇到下载速度慢,这个时候你就需要借助魔法来下载(一定要开启Tun模式)这样Ollama才能通过走代理下载模型
运行效果
如下图所示代表成功
 在这里可以借助Cherry Studio能够更好的调用
在这里可以借助Cherry Studio能够更好的调用
下载地址:https://cherry-ai.com/

 如上图所示已经部署成功
如上图所示已经部署成功
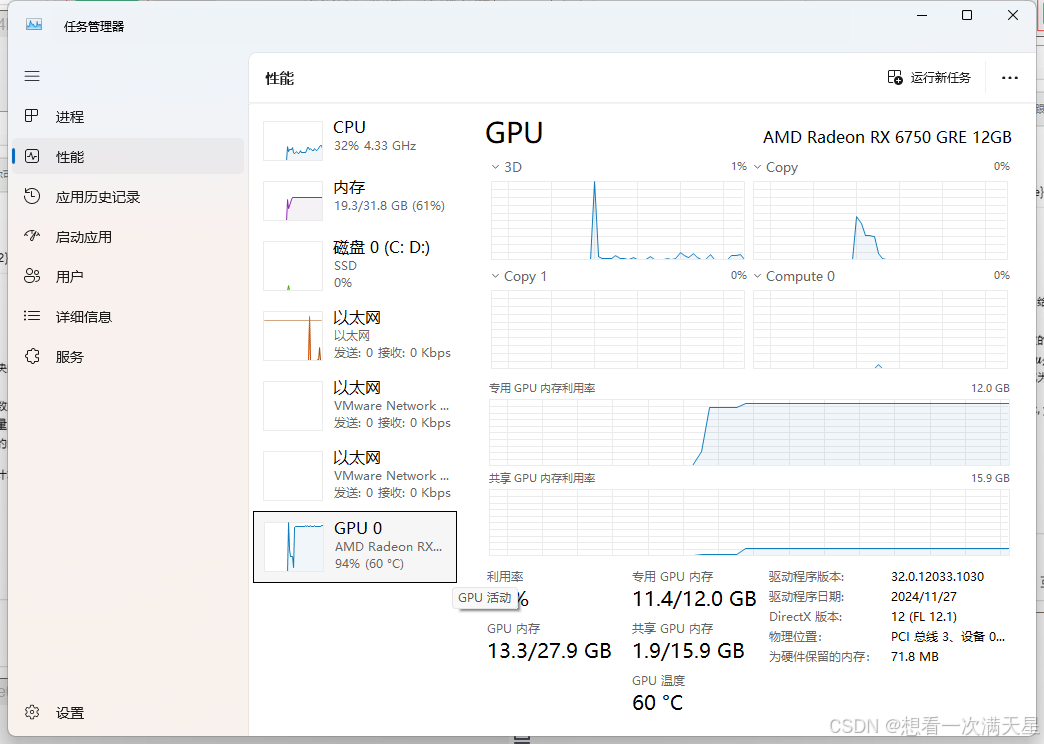 可以看到已经成功调用显卡进行推理
可以看到已经成功调用显卡进行推理



