应用程序的网络流量 and 合成网络流量
1. 应用程序的网络流量 APPLICATION TRAFFIC
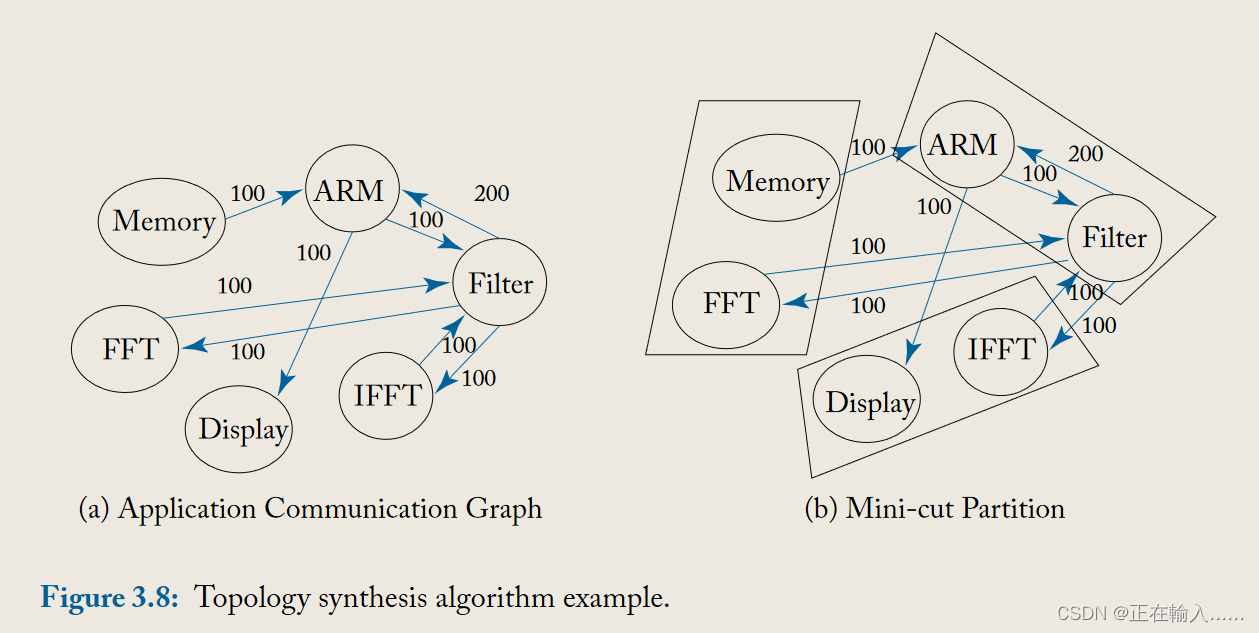
在 MPSoC(多处理器片上系统) 中,应用程序的通信任务图(如图 3.8a 所示)决定了通过片上网络连接的各个 IP核 之间的流量。流量模型可以根据核心之间的平均流量来提取[156, 161]。这有助于为 MPSoC 运行的应用程序类别的流量驱动定制的网络拓扑和映射算法。任务图上的边确定网络链路的吞吐量要求,而芯片上通信 IP 之间的路由器数量以及映射到相同链路的数据流流之间的争用则确定网络延迟。
通常在共享内存的多核系统中,应用程序的共享行为和所使用的一致性协议的类型(如监听协议(snoopy)、有限目录(limited-directory)与全位目录(full-bit directory))决定了网络流量。对于 N 个计算核心的芯片,协议的通信模式可以分为1对1、1对M和M对1,其中M指多个源或目的地(1 < M <= N)。一对一通信通常也称为单播通信(unicast),发生在内核之间交换的单播请求/响应中。一对多或多播通信(multicast)发生在广播和多播请求中。 M-to-1也叫做归约(reduction)通信发生在协议中的确认或令牌收集中以维持消息排序。全位目录跟踪每个共享者的状态,并使用单播和精确多播来保持一致性。监听协议和有限目录(即对共享者进行有限跟踪的目录协议)协议减少了目录存储空间,但需要更高的网络流量,这些流量以广播、多播和归约的消息形式进行通信。
来自应用程序的网络流量还取决于缓存大小和缓存层次结构,以及应用程序工作集的适合程度。L1 和 L2 的大小一定程度上决定了应用程序的未命中率(从DRAM中获取没命中的数据),进而决定了网络的注入率。与每核私有 L2 相比,分布式共享 L2 还具有更高的网络流量,因为每个 L1 未命中都必须遍历片上网络才能到达的主节点。内存相关的通讯流量还会穿过片上网络到达内存控制器,如果某些内核始终能够更快地访问内存控制器,则可能会导致服务质量问题(QoS)。
片上网络流量可以通过使用跟踪(trace)或运行全系统模拟来注入。
- 通信记录驱动的仿真(trace)。
研究人员经常使用在真实系统或全系统模拟器上运行的应用程序的网络注入痕迹(trace)。通信记录提供了一种相当可行的方法来探索所提出的片上网络设计的有效性,但显然,应该注意的是,它们的特性在很大程度上取决于模拟的多核平台:核心/IP 块的数量、内存层次结构、内存控制器的数量等都会显着影响网络跟踪(trace)。使用网络跟踪时缺乏反馈效果也会影响准确性。例如,高速的片上网络比收集通讯记录的系统仿真器网络具有更低的传输延迟,可能会导致在注入请求之前发送响应(可能会破坏通信记录之间的通信关系)。跟踪或推断数据包之间的依赖关系对于能够正确复现跟踪非常重要。
Netrace 是一组工具和跟踪,旨在通过在基于跟踪的模拟框架内添加依赖性跟踪来增强传统基于跟踪的片上网络模拟的性能和保真度。
- 全系统模拟。
全系统评估提供网络内最准确的网络流量动态变化,因为它们对整个系统(核心、缓存、一致性协议、网络和内存)进行详细建模,并启动运行应用程序的操作系统。然而,这些模拟占用了大量的模拟时间。共享内存和 MPI 应用程序的基准套件根据跨内核的应用程序线程映射、共享模式、一致性协议(如果共享内存)、高速缓存大小、内核模型(顺序或乱序)等信息,对片上网络施加不同程度的压力。类似的基准测试集包括 SPLASH-2、PARSEC 和 Rodinia。
2. 合成网络流量 SYNTHETIC TRAFFIC
合成流量模式(synthetic traffic pattern)有助于表征和调试片上网络。在大多数标准的合成网络流量模式中,所有源节点都以均匀随机的注入概率向网络中注入数据(无突发),而目的节点的坐标位置取决于具体的流量模式。表 7.2 列出了一些用于研究 mesh 网络的常见合成流量模式,以及它们的平均跳数和 XY 路由下的理论吞吐量。
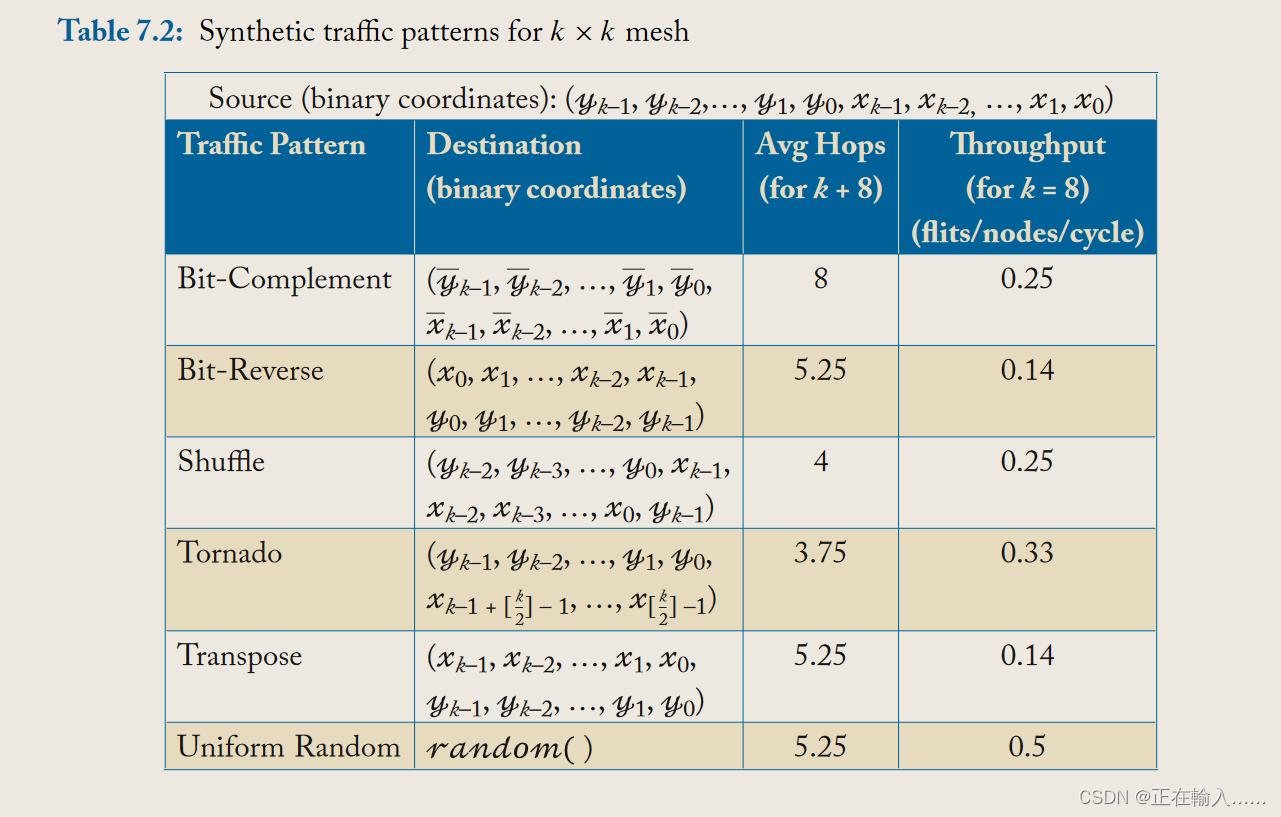
理论吞吐量或容量是“mesh网络中某个(某些)链路每个周期发送 1 flit 的注入速率”(flit/node/cycle)。对于每种流量模式,假设 XY 路由,计算所有链路上的负载。确定负载最重的链路。理论吞吐量是该负载的倒数。这是假设拓扑所能做到的最好的路由、流量控制和微架构的前提下,所能达到的最好性能。合成流量模式对于表征片上网络的延迟和吞吐量非常有用,方法是绘制片上网络的延迟-吞吐量图,并将它们与基线和理想的网络进行比较。可以利用这些数据进行设计空间探索,看看是否可以用更少的缓冲区、VC、flit 大小、通道宽度等来满足所需的延迟和吞吐量。
除了传统的合成流量模式之外,还有模拟应用程序和缓存一致性流量的合成流量生成器。 SynFull 专注于合成再现缓存一致性流量中的流量依赖性以及通用 CMP 工作负载的应用程序不同阶段的流量波动。 APU-SynFull 扩展了这项工作,重点关注具有更复杂的一致性模式和更多突发流量的异构CPU-GPU架构。一般来说,可以采用合成网络流量的组合来检查和测试所提出的方法的局限性。真实网络trace可以大致验证方法的有效性。全系统仿真可以更准确地评估特定系统中的方法。可以用合成流量和真实网络trace与全系统仿真这两个技术的组合去分析所提出方法的利弊。
3. 合成网络流量的具体介绍
用流量矩阵表示流量分布,其中每个矩阵元素 λs,d 给出从节点 s 发送到节点 d 的流量的比例。表 3.1 列出了一些用于评估互连网络的常见静态流量模式。其中一些模式是基于特定应用程序中出现的通信模式。例如,矩阵转置或转角操作(matrix transpose or corner-turn operations)会引起转置模式,而快速傅里叶变换(FFT)或排序应用可能会导致洗牌排列,并且流体动力学模拟通常会表现出邻近模式(neighbor)。所有源节点都以均匀随机的注入概率向网络中注入数据(无突发)。

随机流量(Random traffic)(其中每个源发送到每个目的地的可能性相同)是网络评估中最常用的流量模式。随机流量是非常良性的,因为通过使流量均匀分布,即使对于通常负载平衡很差的拓扑和路由算法,它也可以平衡负载。当仅使用随机流量进行评估时,一些非常糟糕的拓扑和路由算法看起来非常好。为了强调拓扑或路由算法,我们通常使用排列流量(permutation traffic),其中每个源 s 将其所有流量发送到单个目的地,d = π(s)。排列的流量矩阵其中每行和每列包含单个条目,所有其他条目为零,即只有一个目的地。由于它们将负载集中在各个源-目标对上,因此排列会强调拓扑和路由算法的负载平衡。
位排列(Bit permutation)是排列的子集,其中通过排列和选择性地补充源地址的位来计算目的地地址。例如,如果四位源地址为 {s3,s2,s1,s0},则位反转流量模式(Bit Reverse)的目的地为 {s0,s1,s2,s3};对于位补码(bit complement)流量模式,目的地为 {s0,s1,s2,s3}是 {-s3, -s2, -s1, -s0};对于shuffle洗牌,目的地是 {s2,s1,s0,s3};位旋转(Bit Rotation)旋转一位后的目的地地址为 {s0, s3, s2, s1}。
数字排列(Digit permutation)是排列的类似子集,其中目标地址的数字是根据源地址的数字计算的。这种排列仅适用于目标地址可以表示为 n-digit k-radix的网络,例如 k-ary n-cube torus网络和 k-ary n-flyd 蝶形网络。龙卷风(tornado)模式被设计为 torus 拓扑的对抗性(adversary)流量模式,而邻居(neighbor)流量则衡量拓扑利用局部性(locality)的能力。
References:
[1] Dally, William James, and Brian Patrick Towles. Principles and practices of interconnection networks. Elsevier, 2004.
[2] Jerger, Natalie D. Enright, et al. On-chip networks. Vol. 12. No. 3. Morgan & Claypool, 2017.