Jammy@Jetson Orin - Tensorflow & Keras Get Started: Concept
- 1. 源由
- 2. 模型
- 2.1 推理流程
- 2.1.1 获取图像
- 2.1.2 算法识别
- 2.1.3 判断决策
- 2.2 理想情况
- 2.2.1 多因素输入
- 2.2.2 理想识别概率
- 2.3 学习过程
- 2.3.1 标记训练集
- 2.3.2 损失函数
- 2.3.3 训练网络
- 2.3.4 渐进方法
- 3. 总结
- 4. 参考资料
1. 源由
为了更好的了解神经网络,深度学习,机器学习等基本概念,进而更好的应用这种特殊工具建模,调参,以及优化处理流程,找到针对具体业务问题解决办法。
- Keras: 是一种为人类设计的API,而不是机器。Keras遵循降低认知负荷的最佳实践:它提供一致简单的API,最小化常见用例所需的用户操作次数,并提供清晰可行的错误消息。Keras还高度重视制作出色的文档和开发者指南。
- Tensorflow: 是一个用于机器学习和人工智能的免费开源软件库。它可以用于各种任务,但特别关注深度神经网络的训练和推断。
首先,我们先借助图像识别的过程来看下程序/算法的工作流程。
2. 模型
将这个神奇的过程看做是某个黑匣子,比如:神经网络黑匣子。

2.1 推理流程
接下来就以图像识别来看下工作步骤。
2.1.1 获取图像
通过拍照/录像获取图像RGB结构阵列数据,这些数据作为多因素数据输入黑匣子,等待算法的分析。
注:数据被输入黑匣子之前,会有一些预处理,更多应该理解为去噪,规整等所谓数据清洗动作,比如:温度传感器硬件的温漂修正,电路干扰去噪等。这种数据有效性方面的专业知识是阻碍很多纯计算机专业人员无法很好的进行大数据建模的重要障碍之一。
2.1.2 算法识别
经过算法分析后,输出分类的概率。

2.1.3 判断决策
通常认为最大概率的就是被识别的物体,比如:图像被识别为猫的概率是97%,因此远大于其他类别。

2.2 理想情况
以上2.1章节做了推理流程的简单描述,但是算法期望是越来越接近理想情况。
因此,我们有必要进一步了解输入的多因素是什么内容,而输出的理想情况应该是怎么样的。
2.2.1 多因素输入
假设一帧猫的图像是256x256像素,RGB色彩相当于256x256x3的像素值,作为神经网络黑匣子的输入。
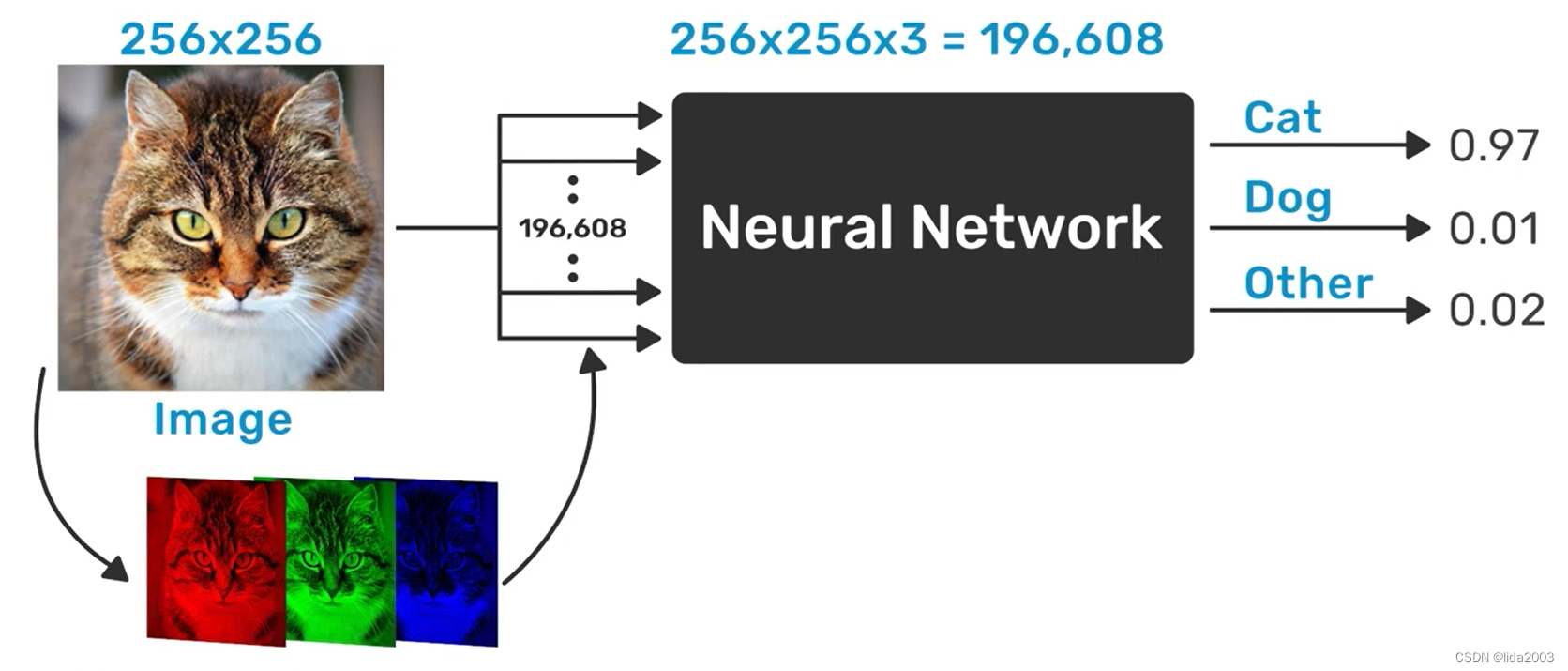
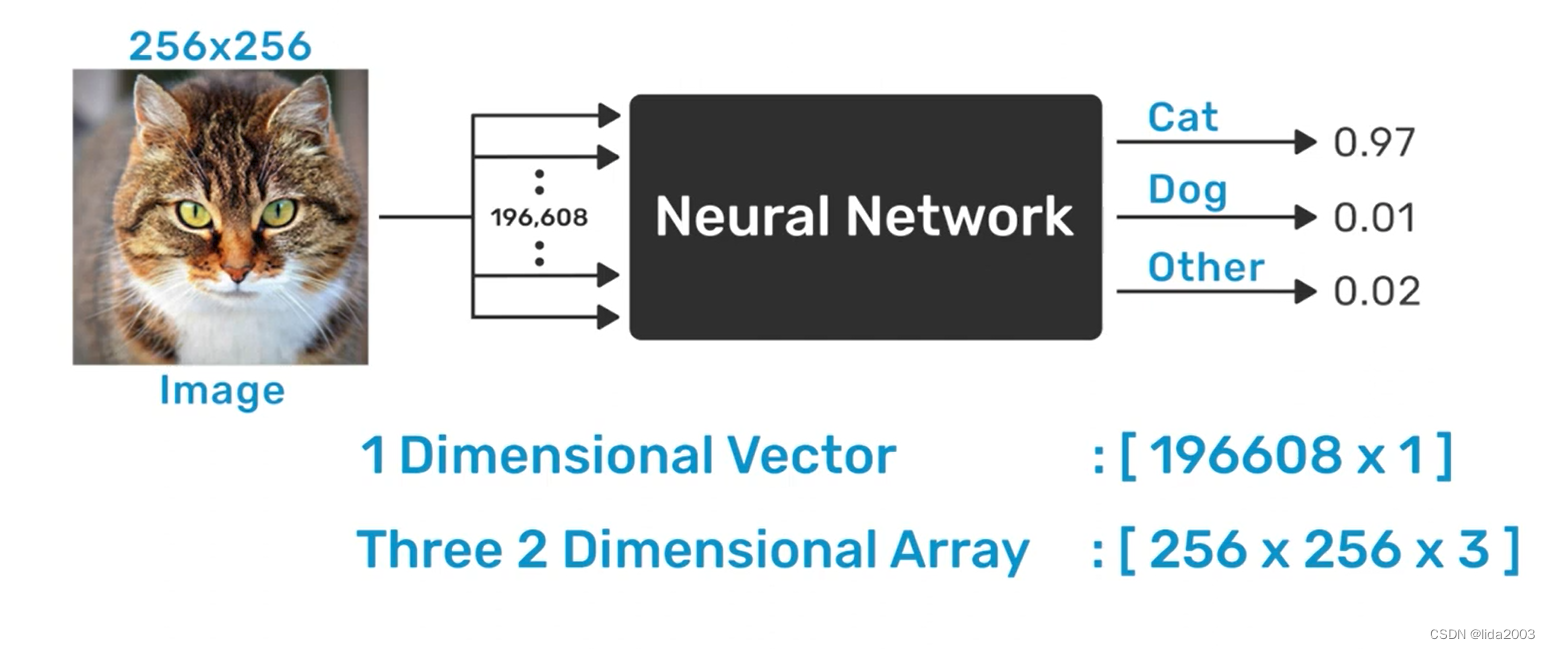
2.2.2 理想识别概率
从理想的角度,上述物体图像识别应该输出如下概率:
- 猫:(100%, 0%, 0%)

- 狗:(0%, 100%, 0%)

- 车:(0%, 0%, 100%)

2.3 学习过程
神经网络的学习需要大量的数据集作为支撑,而且期望数据集具备:重复度低,多样性。
目前,算法上有两种模式:监督训练和非监督训练。非监督训练存在不可控性,随着样本情况的变化,会存在发散等不可控因素,这也许是当前来说非监督训练的一个主要问题。
注:其实这个非监督训练和人类的学习模式非常相近,学校里面是一种监督训练,但是人在学校外仍然在不断地学习,因此,每个人的价值观,世界观都会因为各自得到的输入信息差异,而有各自的特性。真可谓是神来之笔!!!
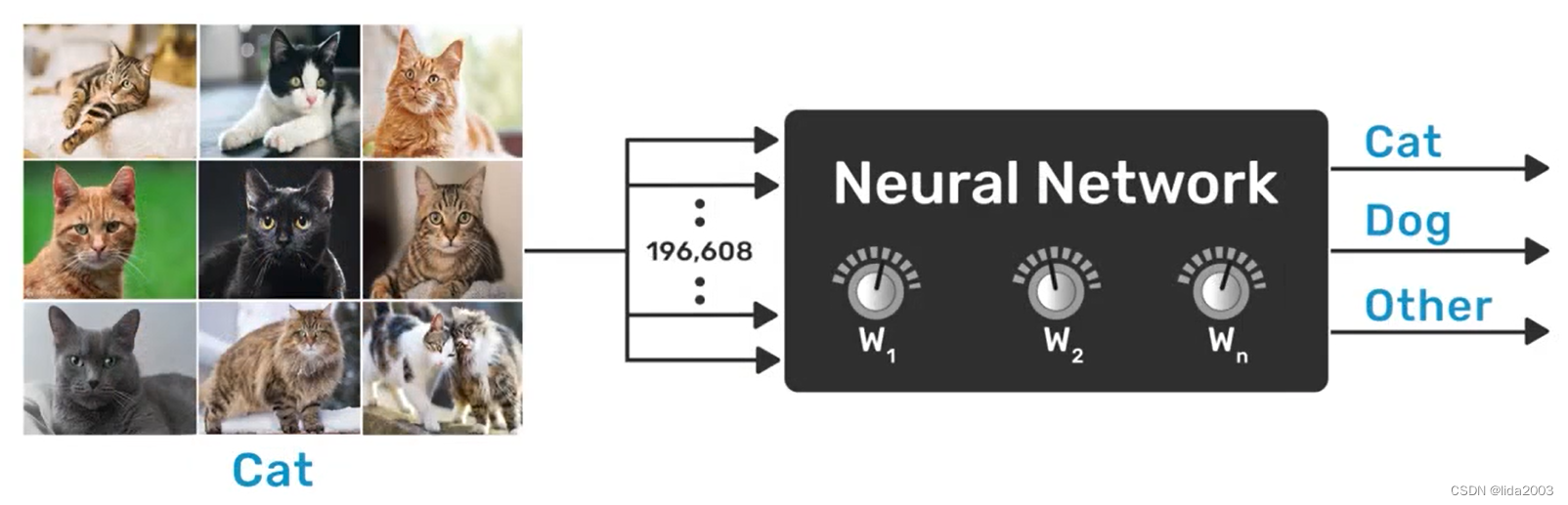
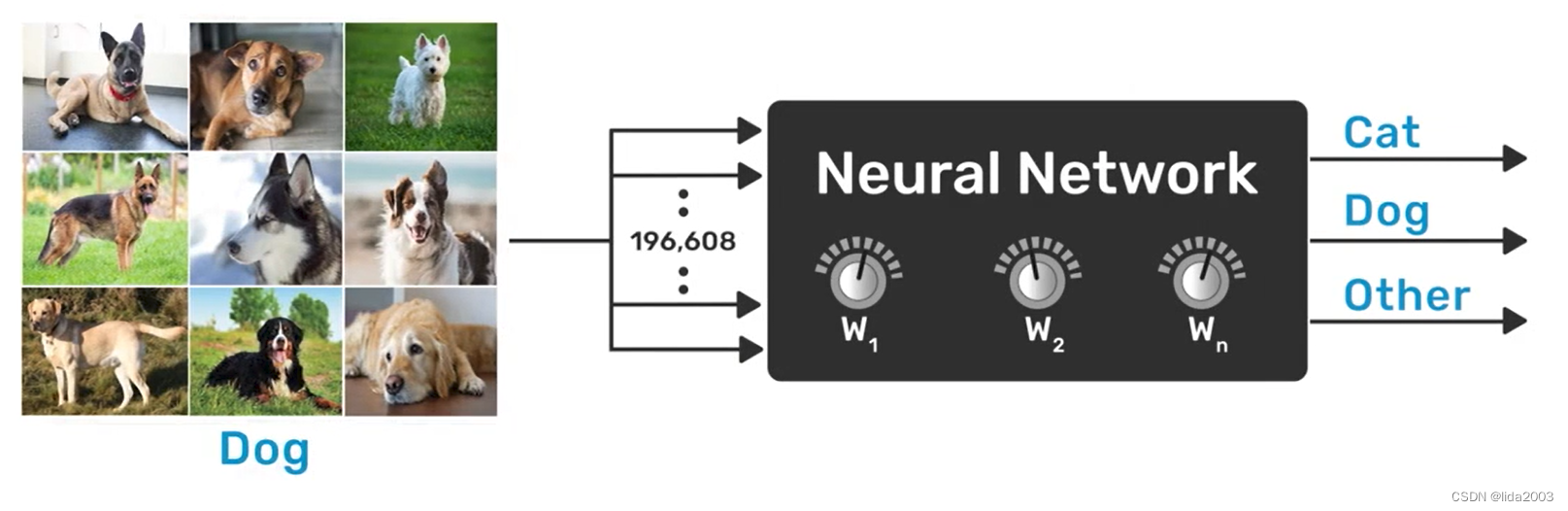
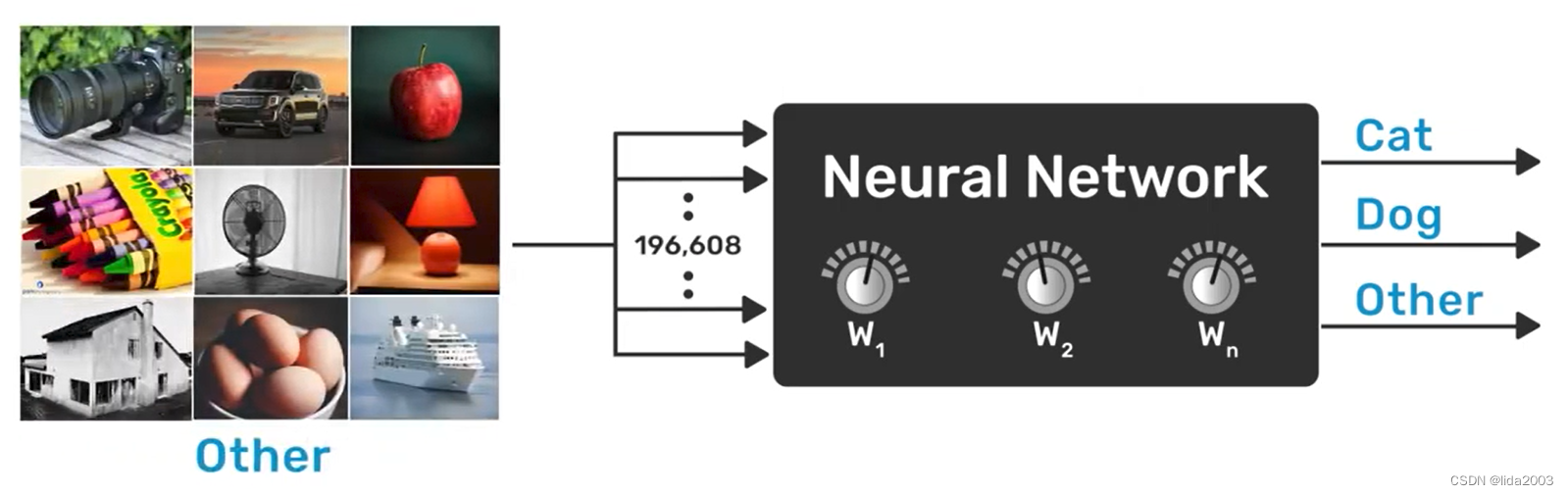
2.3.1 标记训练集
训练集的标记主要表征的是理想情况。
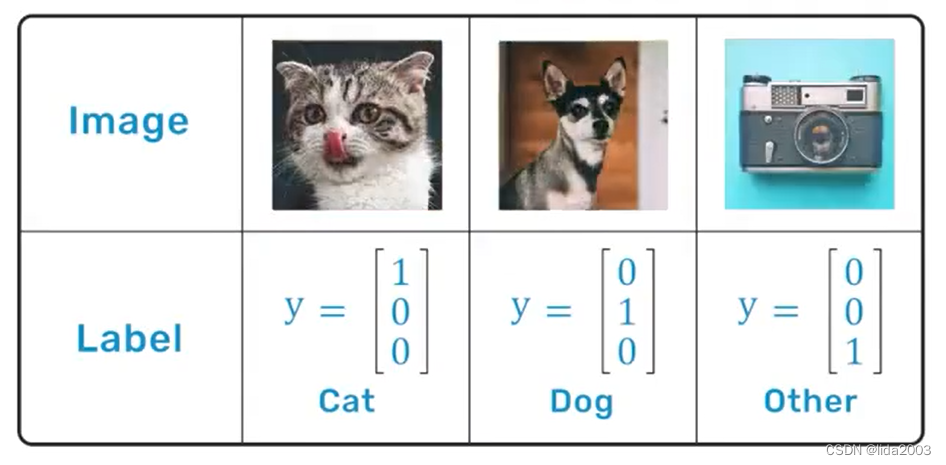
2.3.2 损失函数
定义输出值与理想值之间的差异就是损失函数,比如:方均差。
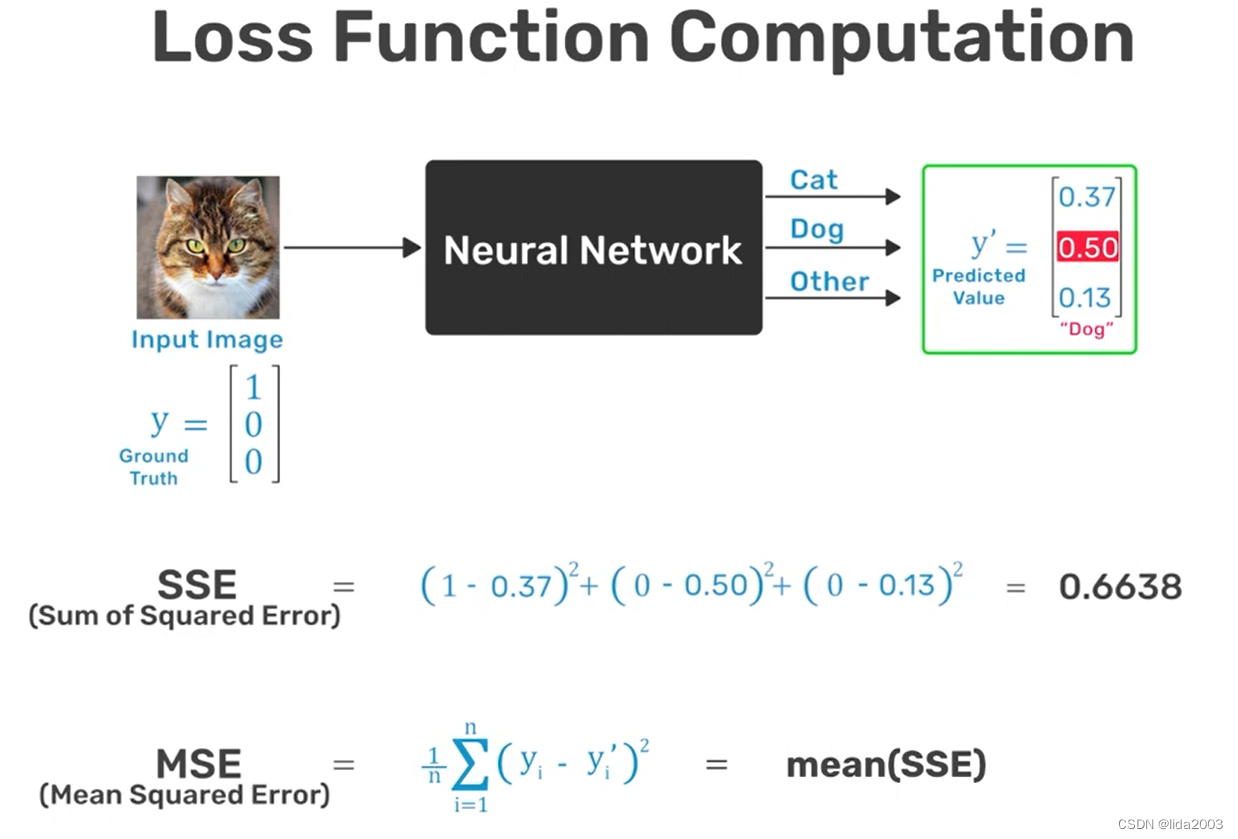
2.3.3 训练网络
通过预测值与理想值的差异(损失函数),更新神经网络节点参数。
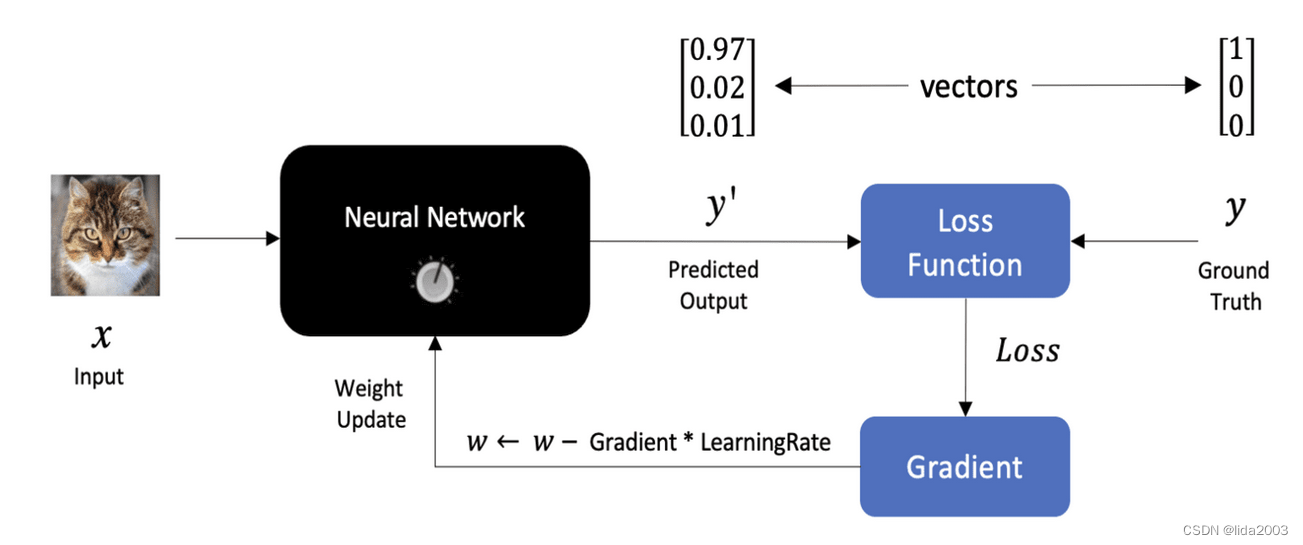
2.3.4 渐进方法
以下是一个单因素的渐进方法,通过预测值与理想值的差异,迭代缩小误差。
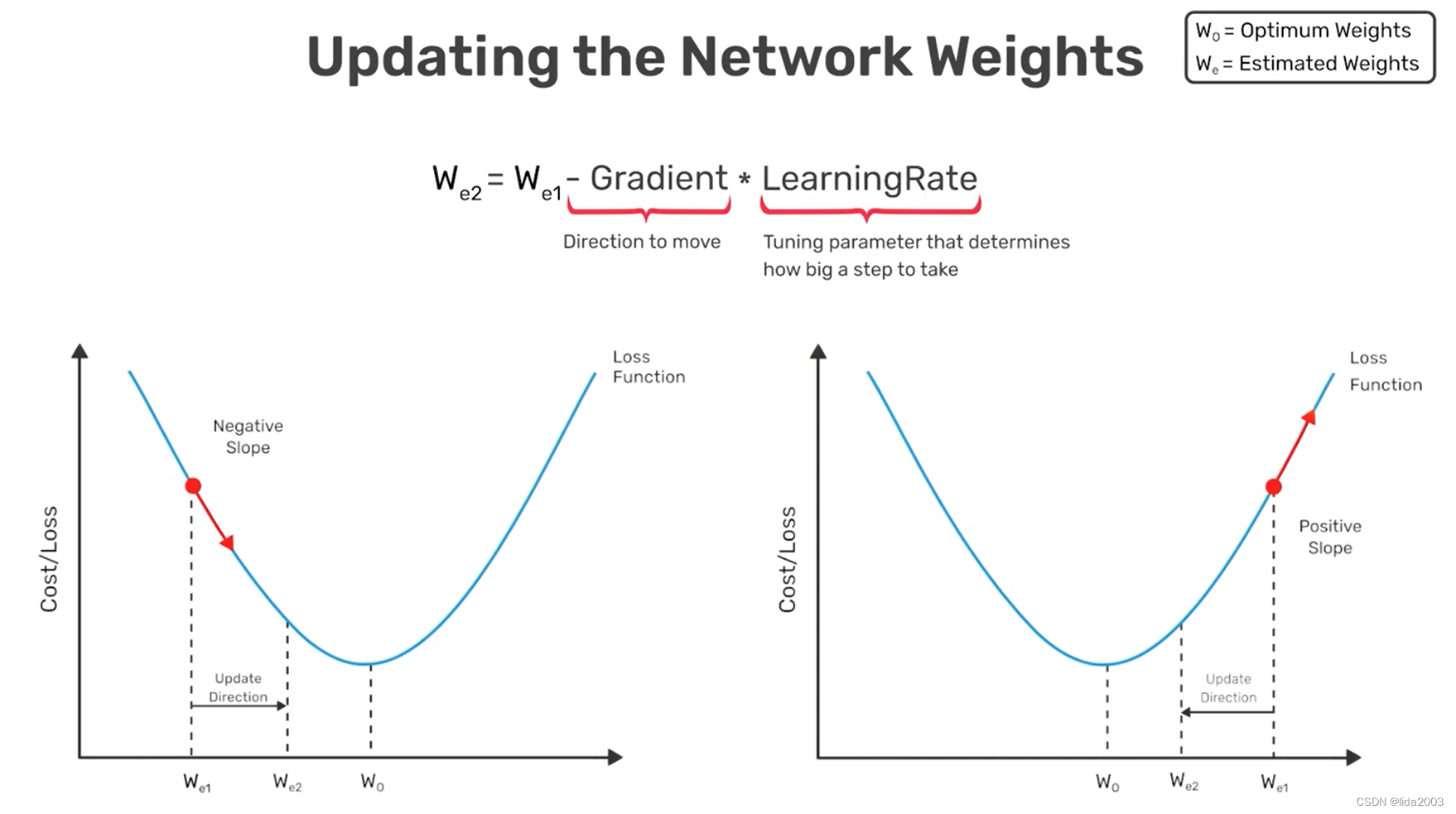
最终达到一个渐进的目标,如果损失函数选择出现问题,就会出现振荡,甚至渐远等发散的情况。
注:损失函数的选择与专业知识息息相关,对于网络模型的构建至关重要,这也是阻碍很多纯计算机专业人员无法很好的进行大数据建模的重要障碍之一。
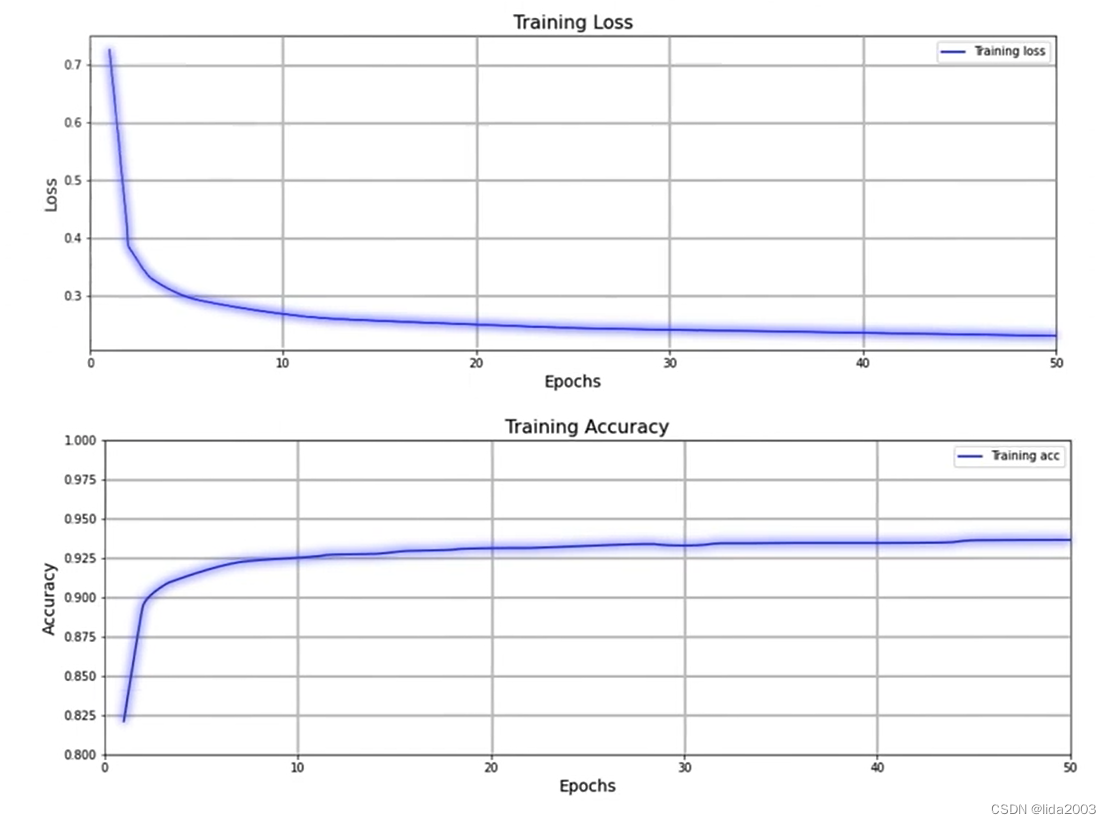
3. 总结
综上所述,大数据深度学习模型的训练、推理,以及主要业务知识要点,都有提及。至于具体的内容,后续我们逐步深入,结合例子一步步扎扎实实的学习理解。
4. 参考资料
【1】Jammy@Jetson Orin - Tensorflow & Keras Get Started