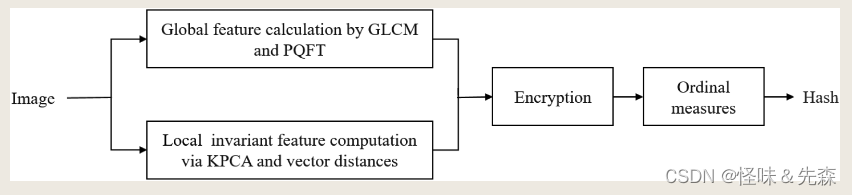
分类与预测算法的评价是在机器学习中至关重要的一步,它帮助我们了解模型在解决特定问题上的表现如何,并且可以帮助我们选择最适合我们需求的算法。下面是分类与预测算法评价的一般介绍:
分类与预测问题
评价指标
-
准确率(Accuracy):模型预测正确的样本数与总样本数之比,适用于均衡类别的数据集。
-
精确率(Precision):预测为正类别的样本中,真正为正类别的比例,适用于关注假阳性的情况。
-
召回率(Recall):真实为正类别的样本中,被正确预测为正类别的比例,适用于关注假阴性的情况。
-
F1 分数:精确率和召回率的调和平均数,综合考虑了两者的影响。
-
ROC 曲线和AUC 值:ROC 曲线是以假阳性率为横轴,真阳性率为纵轴绘制的曲线,AUC 是 ROC 曲线下的面积,用于评估分类模型的性能。
-
均方误差(Mean Squared Error,MSE):用于评估回归模型的性能,计算预测值与真实值之间的平方差的平均值。
-
R²(R-squared):用于回归模型的评估指标,表示模型对目标变量方差的解释程度。
交叉验证
为了更准确地评估模型性能,通常会使用交叉验证技术。交叉验证将数据集划分为训练集和测试集,并多次重复这一过程,以减少因数据划分方式不同而引入的偏差。
超参数调优
在评估算法性能时,还需要考虑超参数的选择。超参数是在模型训练之前设定的参数,它们会影响模型的学习过程和性能。通过调优超参数,可以提高模型的性能。
综合考虑
最终评价一个算法的好坏需要综合考虑各种指标,并根据具体问题的要求来选择最合适的算法和参数组合。通常,没有单一的评价指标能够完全描述模型的性能,需要结合多个指标来进行评估。