1 MySQL
DataBase(DB)是存储和管理数据的仓库
DataBaseManagementSystem(DBMS)数据库管理系统,操纵和管理数据库的大型软件
SOL(Structured QueryLanguage)操作关系型数据库的编程语言,定义了一套操作关系型数据库统一标准
关系型数据库(RDBMS)建立在关系模型基础上,由多张相互连接的二维表组成的数据库
1.1 登录
cmd 下指令:
登录:
mysql -uroot -p1234
mysql -uroot -p
1234
实际上,MySQL 是安装在服务器上的,所以需要 VMware 模拟机来模拟一个服务器用作练习

1.2 建立数据库
建立数据库:
cmd下
create database db01;
1.3 SQL 语法 & 分类
- SQL 语句可以单行或多行书写,以分号结尾
- SOL 语句可以使用空格/缩进来增强语句的可读性
- MySQL 数据库的 SQL 语句不区分大小写
- 单行注释:--注释内容 或 # 注释内容(MySQL特有)
- 多行注释:/* 注释内容 */
注意顺序:

SQL 分类
| 分类 | 全称 | 说明 |
|---|---|---|
| DDL | Data Definition Language | 数据定义语言,用来定义数据库对象(数据库,表,字段) |
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据进行增删改 |
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录 |
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户、控制数据库的访问权限 |
1.3.1 DDL(数据库)
查询所有数据库
show databases;
查询当前使用的数据库
select database();
使用
use 数据库名;
创建数据库
create database [if not exists] 数据库名;
删除数据库
drop database [if exists] 数据库名;
上述的 "database" 也可以替换为 "schema"
1.3.2 IDEA 图形化操作数据库
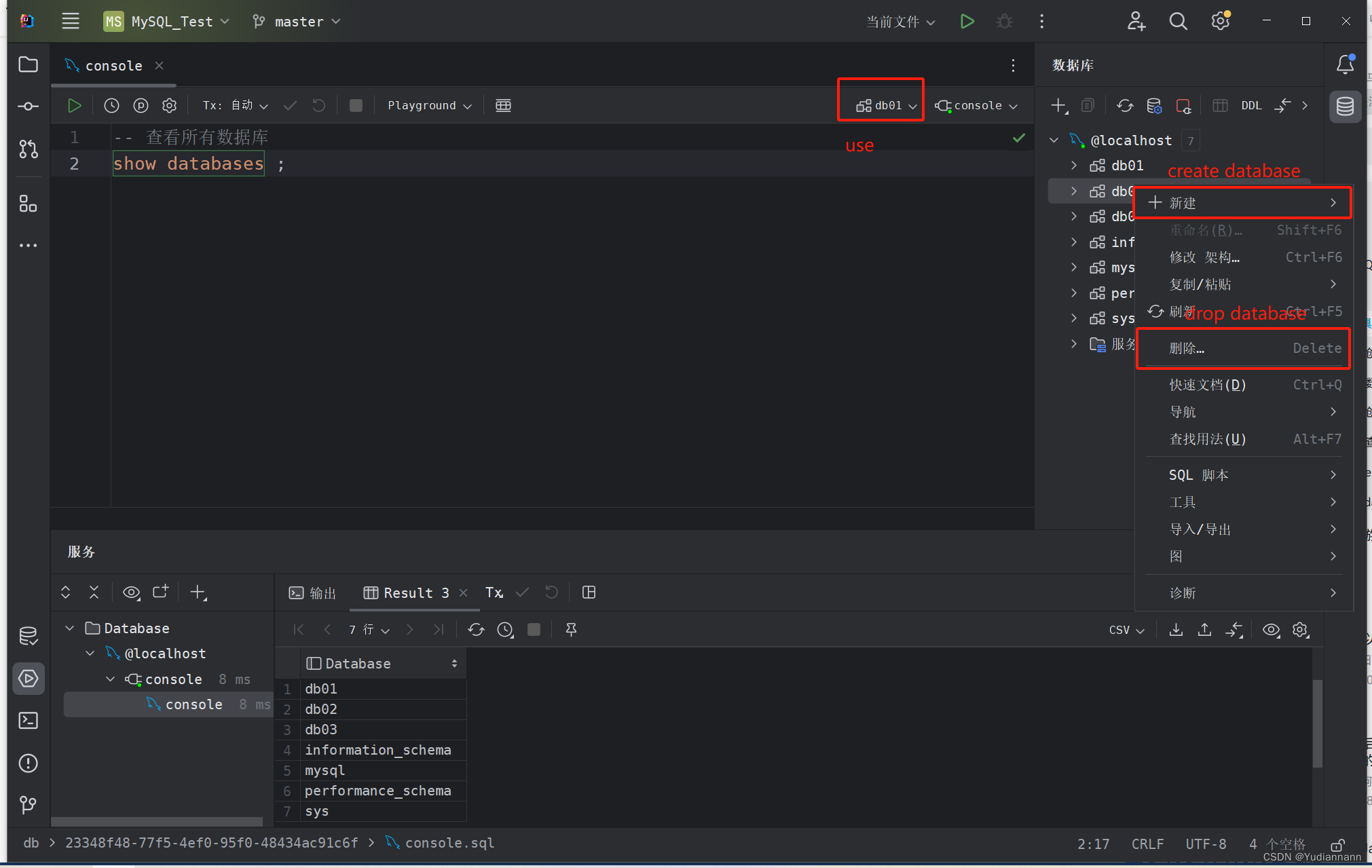
1.3.3 DDL(表结构)
创建表
create table 表名(
字段1 字段类型 [约束] [comment 字段1注释]
...
字段n 字段类型 [约束] [comment 字段n注释]
)[comment 表注释];
create table tb_user(id int comment 'ID,唯一标识',username varchar(20) comment '用户名',name varchar(10) comment '姓名',age int comment '年龄',gender varchar(1) comment '性别'
)comment '用户表';
但是此时 id 可以不唯一,要设置 id 唯一,就要设置约束
约束:是作用于表中字段上的规则,用于限制存储在表中的数据
| 约束 | 描述 | 关键字 |
|---|---|---|
| 非空约束 | 限制该字段不能为 null | not null |
| 唯一约束 | 保证字段唯一 | unique |
| 主键约束 | 主键是一行数据的唯一标识,非空且唯一 | primary key |
| 外键约束 | 让两张表的数据建立链接,保证数据的一致性和完整性 | foreign key |
| 默认约束 | 默认 | default |
现在加入了约束,删除旧表,创建新表,并且手动加入数据
create table tb_user(id int primary key comment 'ID,唯一标识',username varchar(20) not null unique comment '用户名',name varchar(10)not null comment '姓名',age int comment '年龄',gender varchar(1) default '男' comment '性别'
)comment '用户表';drop table tb_user; -- 删除表delete from tb_user; -- 删除表中的数据insert into tb_user values(1,'1401173962','wyn',21,'m'); -- 向表中插入数据另外,主键可以加上 auto_increment 自动增长:
1.3.4 数据类型
MySQL数据分为三种:
- 数值类型
- 字符串类型
- 日期时间类型
数值类型:
tinyint、smallint、mediumint、int、bigint、float、double、decimal
注:
可以加上无符号:如 tinyint unsigned
后三者的格式为:如 float(5,2) 5表示整个数字长度,2表示小数位个数

字符串类型:
char(10),代表长度总是10,但是性能好,以空间换时间
varchar(10),代表长度随着实际改变,但是性能差,以时间换空间
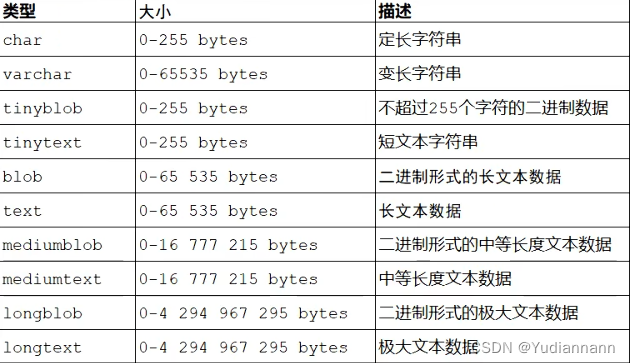
日期时间类型:

1.4 案例一:设计表结构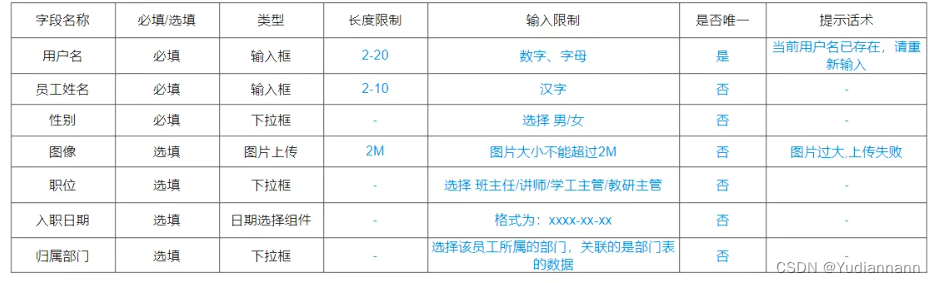

这次在 IDEA 里面创建表:
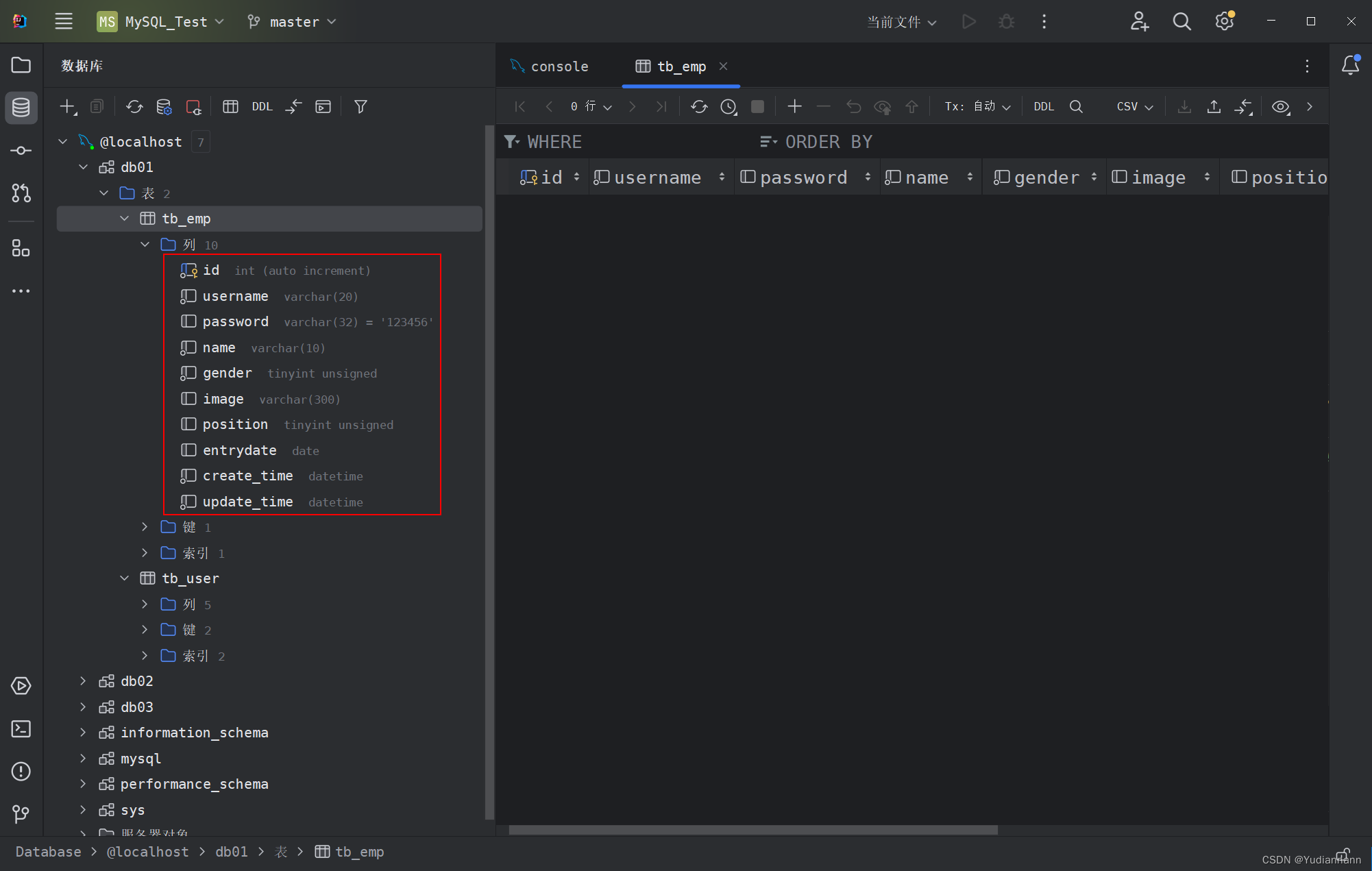
注:
在表中还要加上两条数据:
- create_time 记录这条数据插入的时间
- update_time 记录这条数据最后更新的时间
1.5 DDL(表操作)
查询当前数据库所有表
show tables;
查询表结构
desc 表名
查询建表语句
show create table 表名
添加字段
alter table 表名 add 字段名 类型 [comment 注释] [约束];
修改字段类型
alter table 表名 modify 字段名 新数据类型;
修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型 [comment 注释] [约束]


2 DML
DML(Data Manipulation Language)用来对数据库中表的数据记录进行增、删、改操作
增:



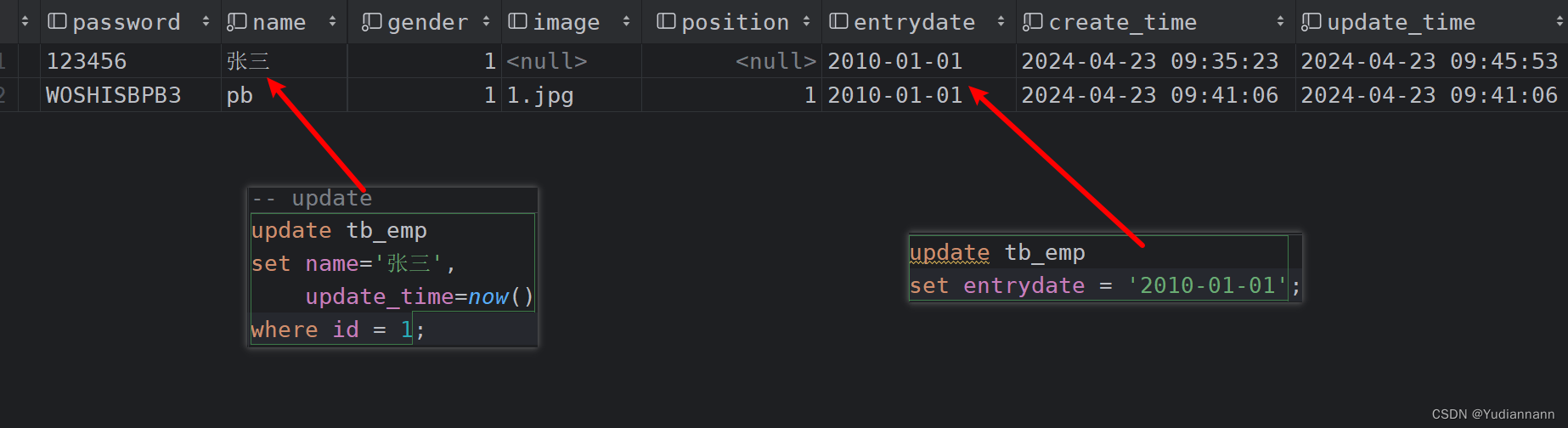
更新:

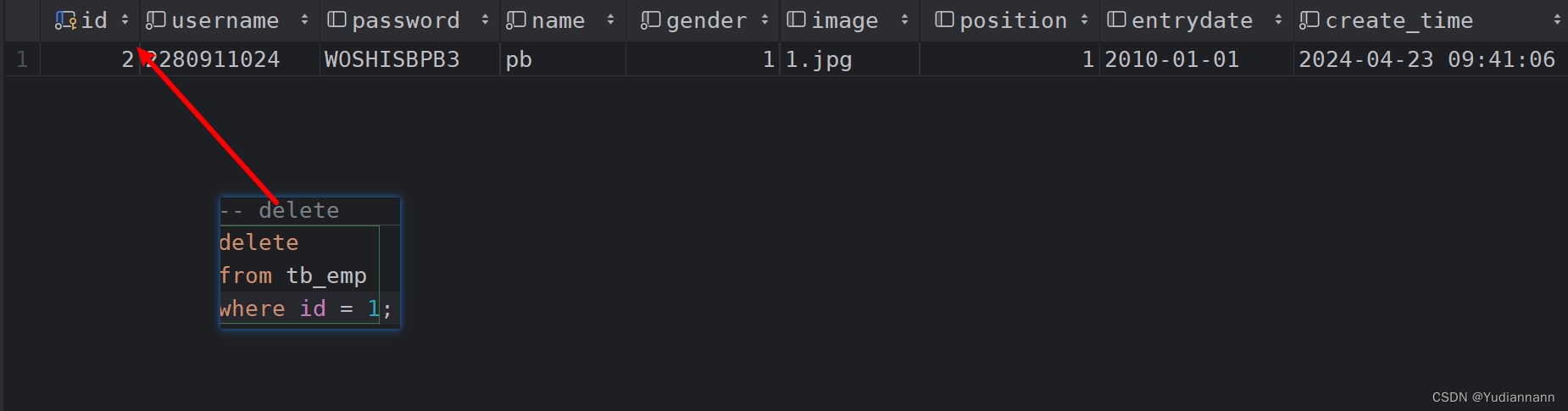
删:

3 DQL
DQL(Data 0ueryLanguage),用来查询数据库表中的记录
查询分五种:
- 基本查询
- 条件查询
- 分组查询
- 排序查询
- 分页查询

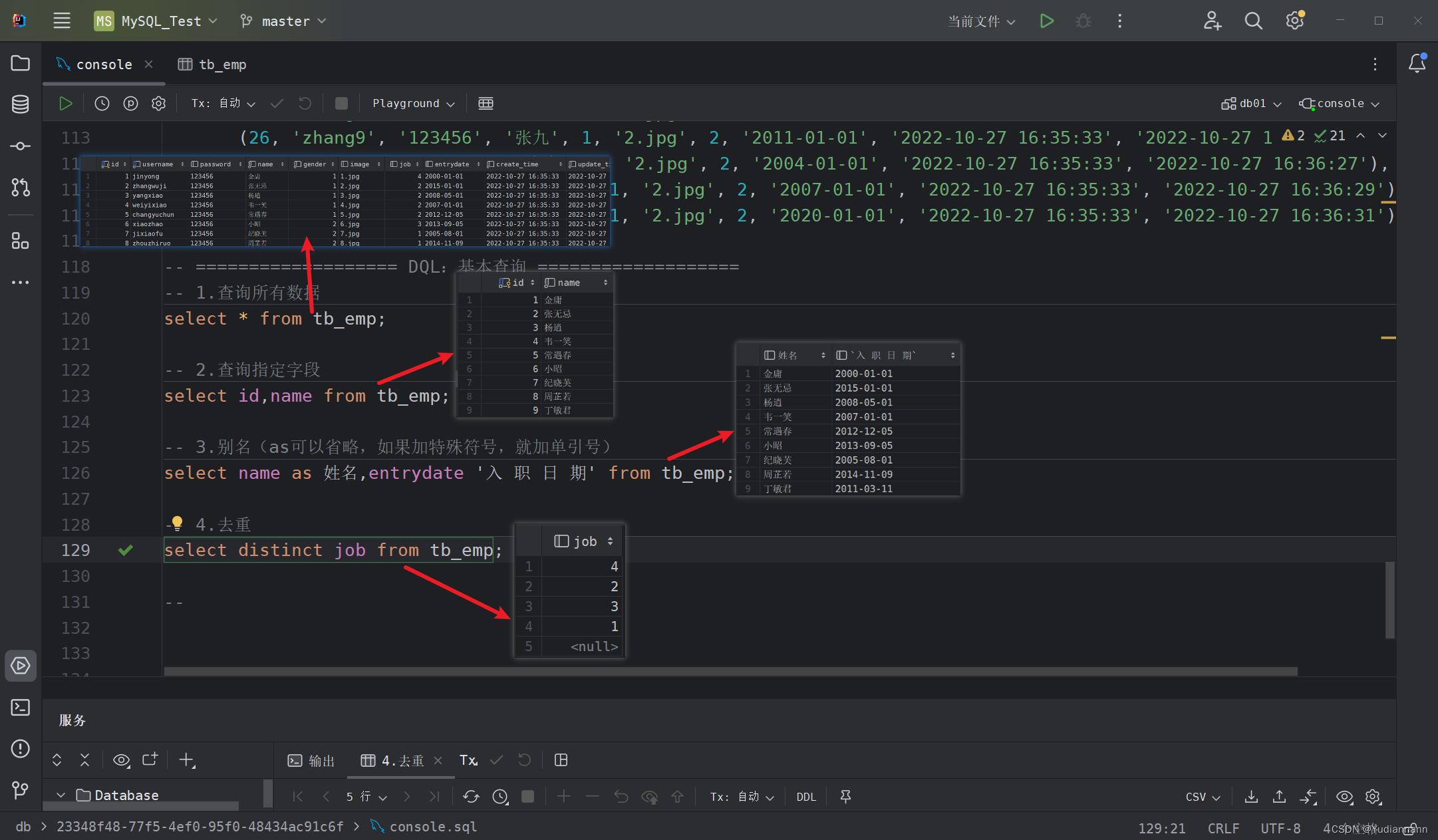
3.1 基本查询

3.2 条件查询

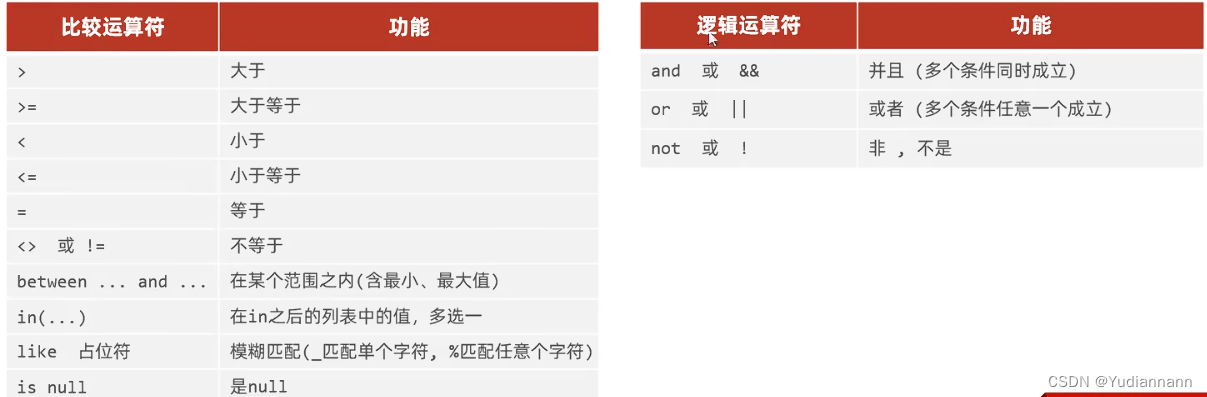
-- =================== DQL:条件查询 ===================
-- 1.查找姓名为"杨逍"的员工
select * from tb_emp where name = '杨逍';-- 2.查找 id 小于等于 5 的员工信息
select * from tb_emp where id <= 5;-- 3.查找没有分配职位的员工信息
select * from tb_emp where job is null;-- 4. 查找有职位的员工信息
select * from tb_emp where job is not null;-- 5.查询密码不为'123456'的员工信息
select * from tb_emp where password != '123456';-- 6.查询 入职日期 在'2000-01-01’(包含)到'2010-01-01'(包含)之间的员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';-- 7.查询 入职日期 在'2000-01-01’(包含)到'2010-01-01'(包含)之间的【女】员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender=2;-- 8.查询 职位是 2(讲师),3(学工主管),4(教研主管)的员工信息
select * from tb_emp where job=2 or job=3 or job=4;
select * from tb_emp where job in (2,3,4);-- 9.查询 姓名 为两个字的员工信息
select * from tb_emp where name like '__';-- 10.查询 姓"张”的员工信息
select * from tb_emp where name like '张%';3.3 分组查询
聚合函数:将一列数据作为一个整体,进行纵向计算
select 聚合函数(字段列表) from 表名;
| 聚合函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
-- =================== DQL:分组查询 ===================
-- 1.统计员工数量
select count(id) from tb_emp;
select count(1) from tb_emp; -- 常量
select count(*) from tb_emp; -- 通配符-- 2.统计该企业最早入职的员工
select min(entrydate)from tb_emp;
select name,entrydate from tb_emp where entrydate = (select min(entrydate)from tb_emp);-- 3.统计该企业最迟入职的员工
select max(entrydate)from tb_emp;
select name,entrydate from tb_emp where entrydate = (select max(entrydate)from tb_emp);-- 4.统计 id 均值
select avg(id) from tb_emp;-- 4.统计 id 之和
select sum(id)from tb_emp;分组查询:
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件]
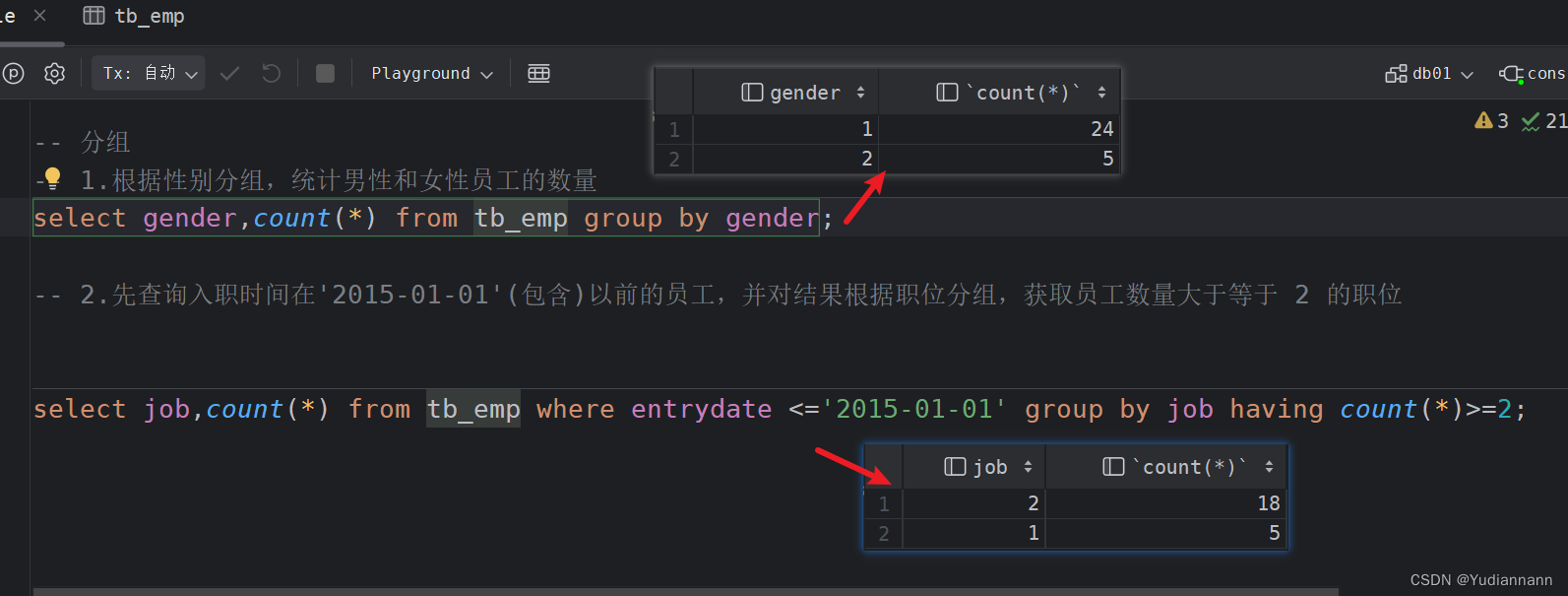
where 和 having 的区别
- 执行时机不同:where 是分组之前进行过滤,不满足 where 条件,不参与分组;而 having 是分组之后对结果进行过滤
- 判断条件不同:where 不能对聚合函数进行判断,而 having 可以
注:
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
(因为分组之后再去查所有字段,还不如不用分组)
- 执行顺序:where > 聚合函数 > having
3.4 排序查询
select 字段列表 from 表名 [where 条件列表] [group by 分组字段] order by 字段1 排序方式1
排序方式:
- ASC(默认):升序
- DESC:降序
-- =================== DQL:排序查询 ===================
-- 1.根据入职时间,对员工进行升序排序
select * from tb_emp order by entrydate;-- 2.根据入职时间,对员工进行降序排序
select * from tb_emp order by entrydate desc;-- 3.根据 入职时间 对公司的员工进行 升序排序, 入职时间相同,再按照 更新时间 进行降序排序
select * from tb_emp order by entrydate,update_time desc ;注:如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
3.5 分页查询
select 字段列表 from 表名 limit 起始索引, 查询记录数;
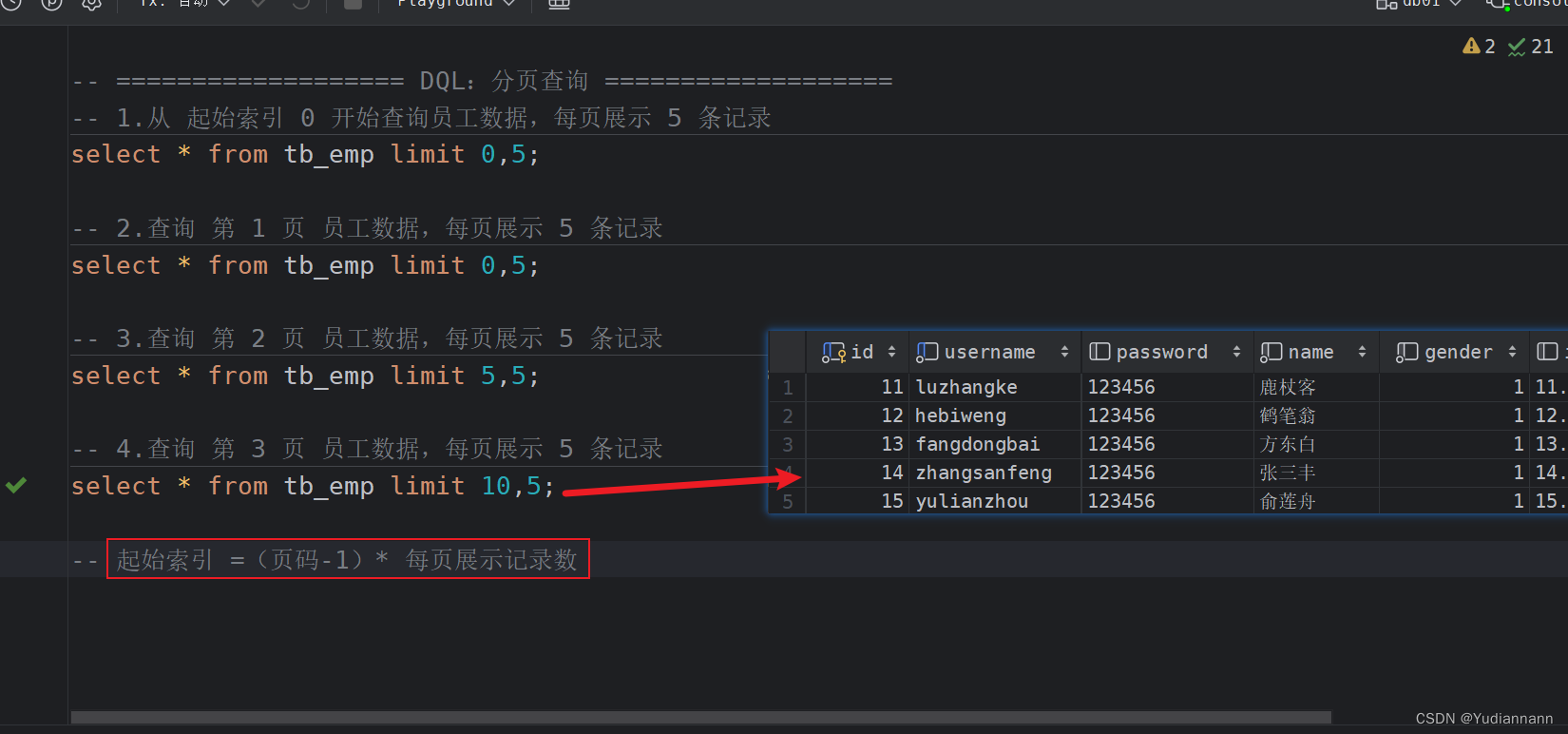
起始索引 = (页码-1) * 每页展示记录数
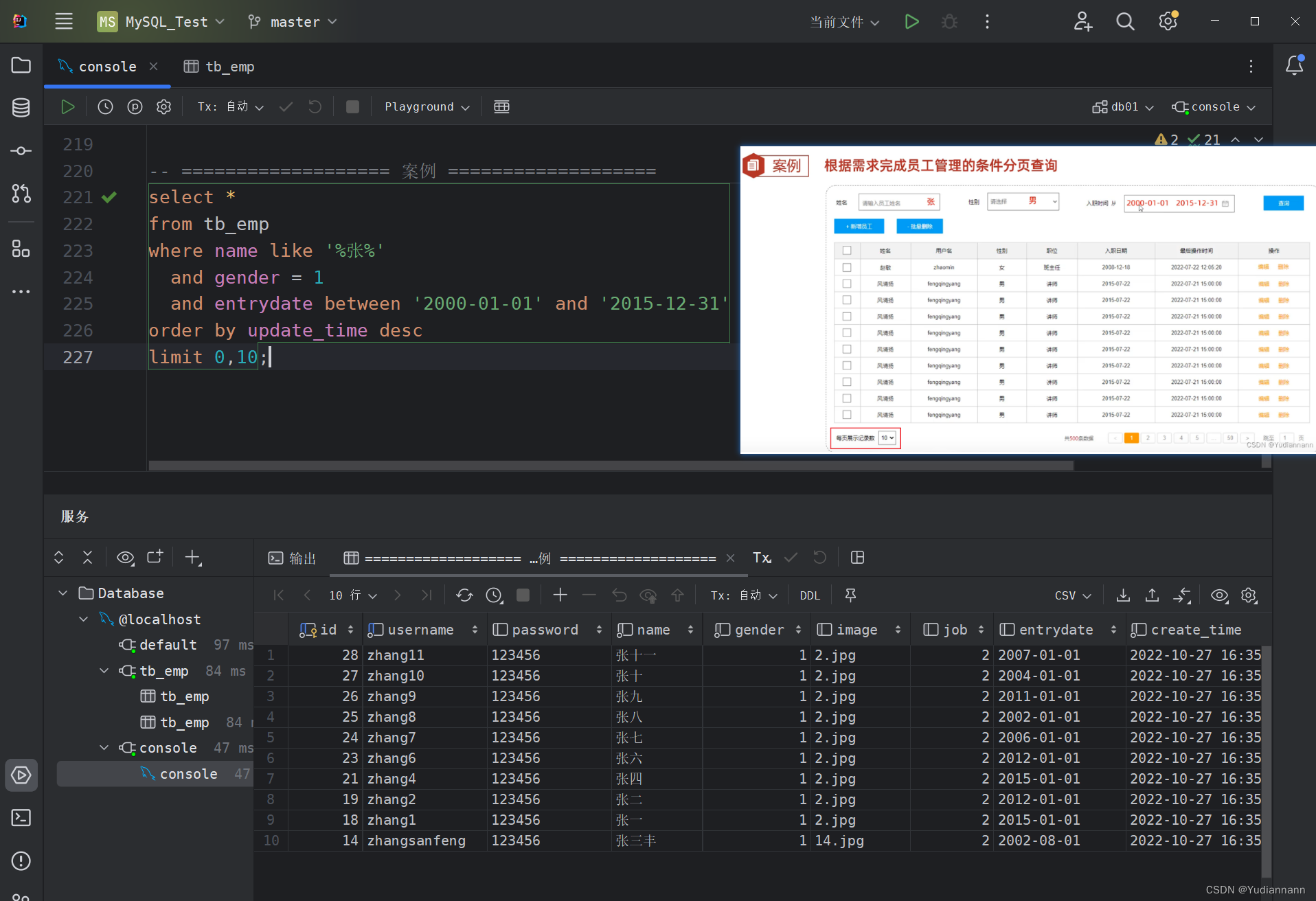
4 案例二:条件分页查询
查询所有姓张,男性,入职时间从2000年1月1日到2015年12月31日的员工,并且一页十条
查询男性、女性员工多少人,各种职位多少人
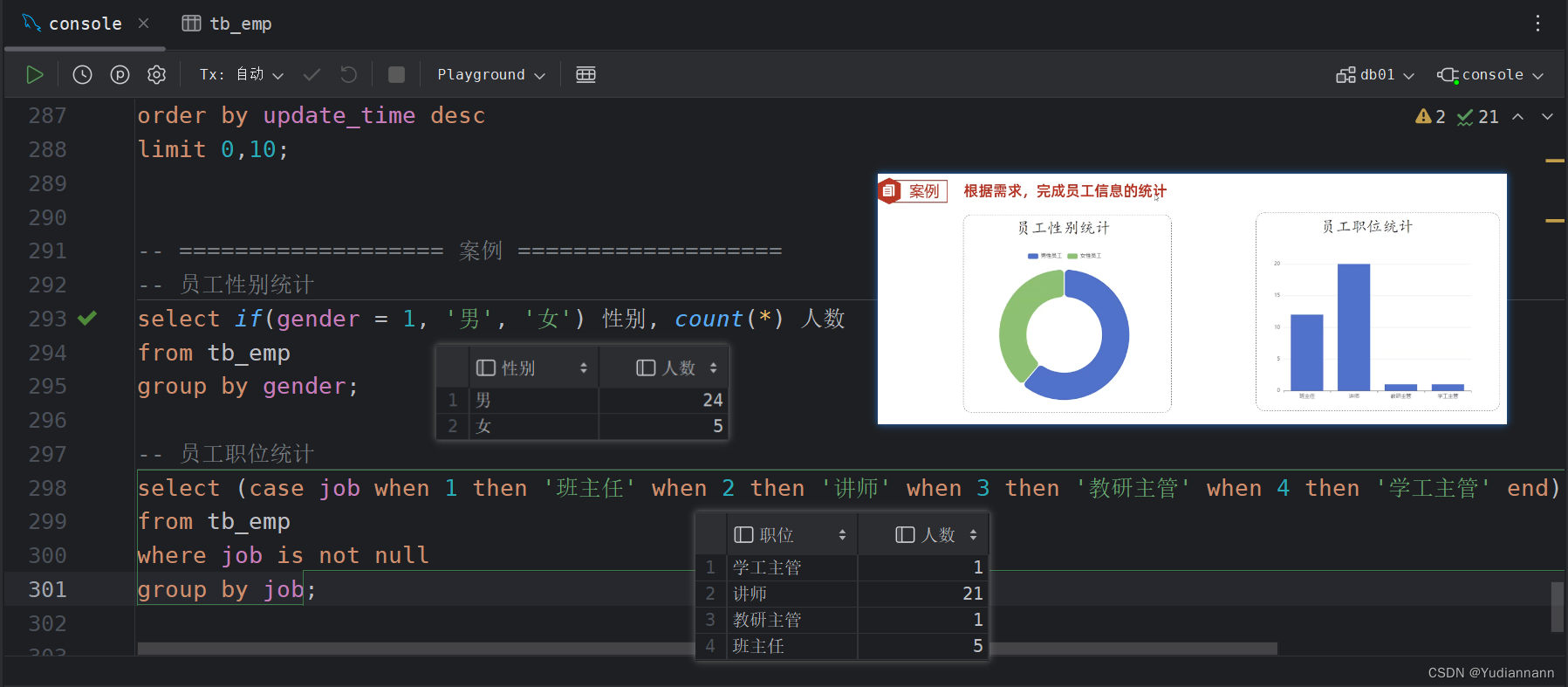
if语句:
if(条件表达式, true取值, false取值)
case语句:
case 表达式 when 值 then 结果1 when 值2 then 结果2...else ...end
5 多表设计
- 一对多
- 一对一
- 多对多
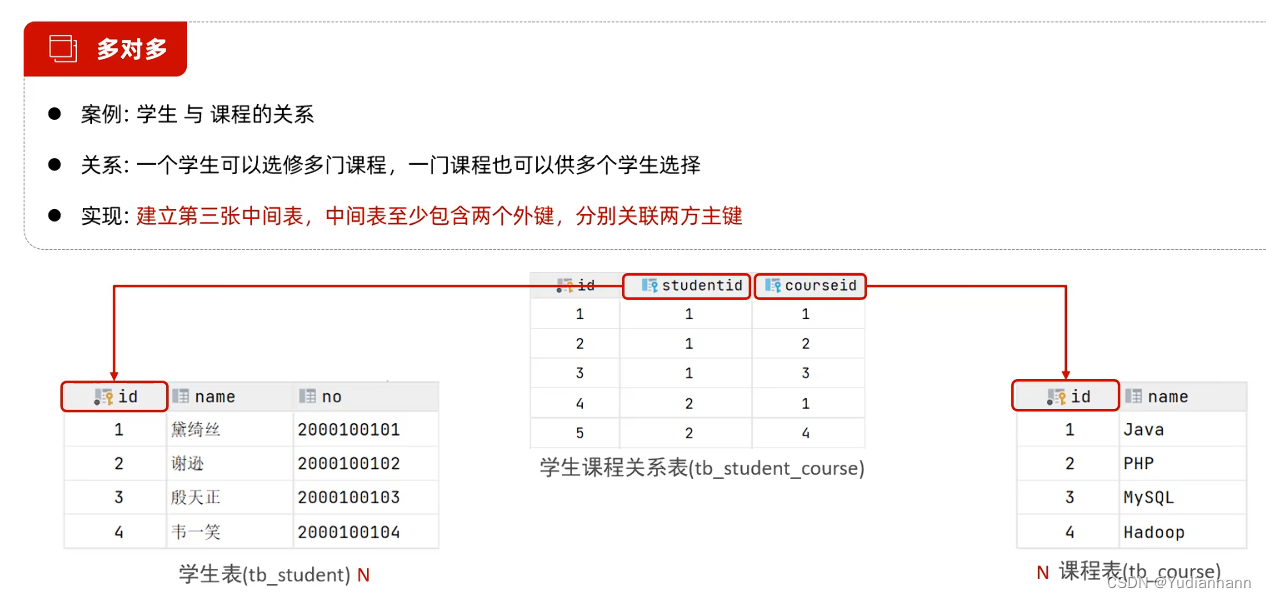
5.1 一对多
部门-员工
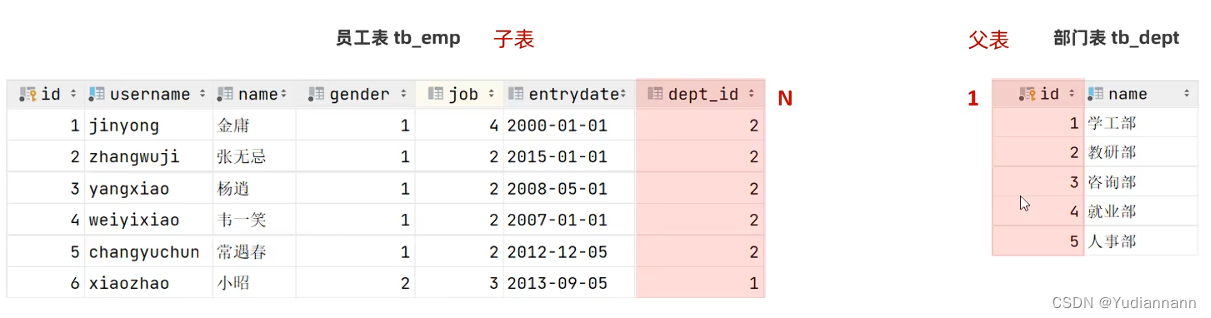
一对多关系实现:在数据库表中多的一方,添加字段,来关联一方的主键
外键:保证了数据的一致性和完整性
-- 创建表时指定
create table 表名(
字段名 数据类型,
...
[constraint] [外键名称] foreign key(外键字段名) references 主表(字段名)
);
-- 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(字段名);
推荐使用逻辑外键

5.2 一对一
- 案例:用户 与 身份证信息 的关系
- 关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他字段放在另一张表中,以提升操作效率
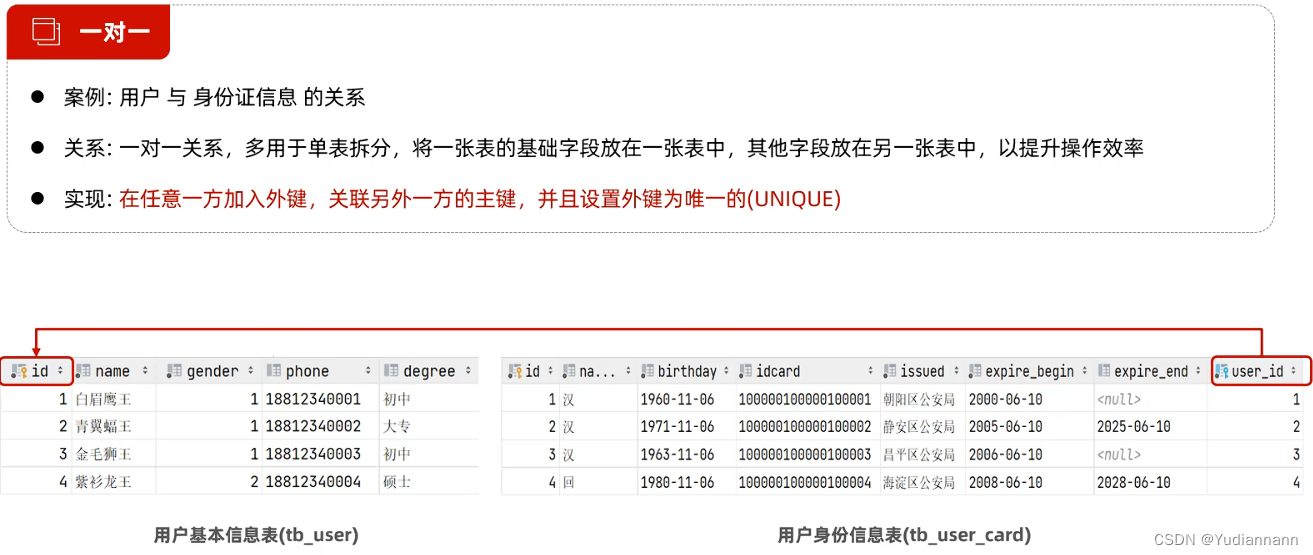
5.3 多对多