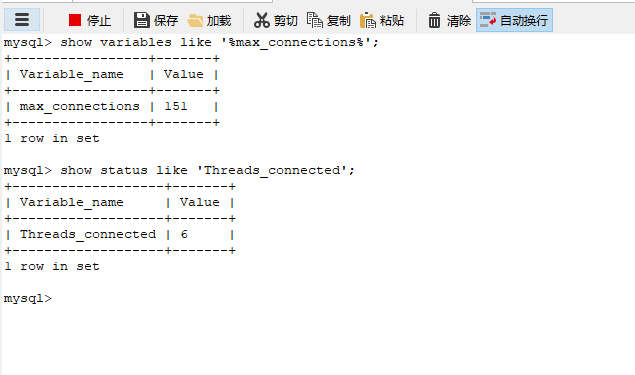
我自己的原文哦~ https://blog.51cto.com/whaosoft/12275703
# 大模型参数高效微调综述
近期,大语言模型、文生图模型等大规模 AI 模型迅猛发展。在这种形势下,如何适应瞬息万变的需求,快速适配大模型至各类下游任务,成为了一个重要的挑战。受限于计算资源,传统的全参数微调方法可能会显得力不从心,因此需要探索更高效的微调策略。上述挑战催生了参数高效微调(PEFT)技术在近期的快速发展。
为了全面总结 PEFT 技术的发展历程并及时跟进最新的研究进展,最近,来自美国东北大学、加州大学 Riverside 分校、亚利桑那州立大学和纽约大学研究者们调研、整理并总结了参数高效微调(PEFT)技术在大模型上的应用及其发展前景,并总结为一篇全面且前沿的综述。
论文链接:https://arxiv.org/pdf/2403.14608.pdf
PEFT 提供了一个高效的针对预训练模型的下游任务适配手段,其通过固定大部分预训练参数并微调极少数参数,让大模型轻装上阵,迅速适配各种下游任务,让大模型变得不再「巨无霸」。
全文长达 24 页,涵盖了近 250 篇最新文献,刚发布就已经被斯坦福大学、北京大学等机构所引用,并在各平台都有着不小的热度。
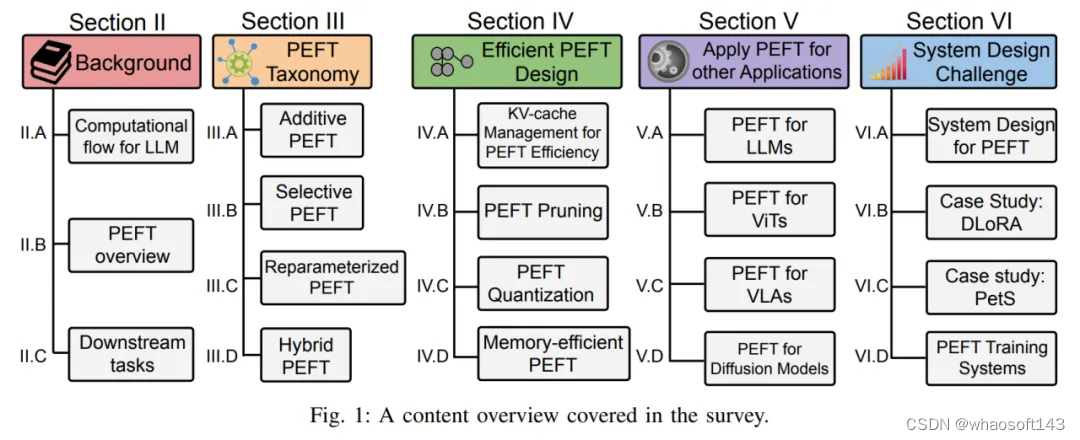
具体来说,该综述分别从 PEFT 算法分类,高效 PEFT 设计,PEFT 跨领域应用,以及 PEFT 系统设计部署四大层面,对 PEFT 的发展历程及其最新进展进行了全面且细致的阐述。无论是作为相关行业从业者,或是大模型微调领域的初学者,该综述均可以充当一个全面的学习指南。
1、PEFT 背景介绍
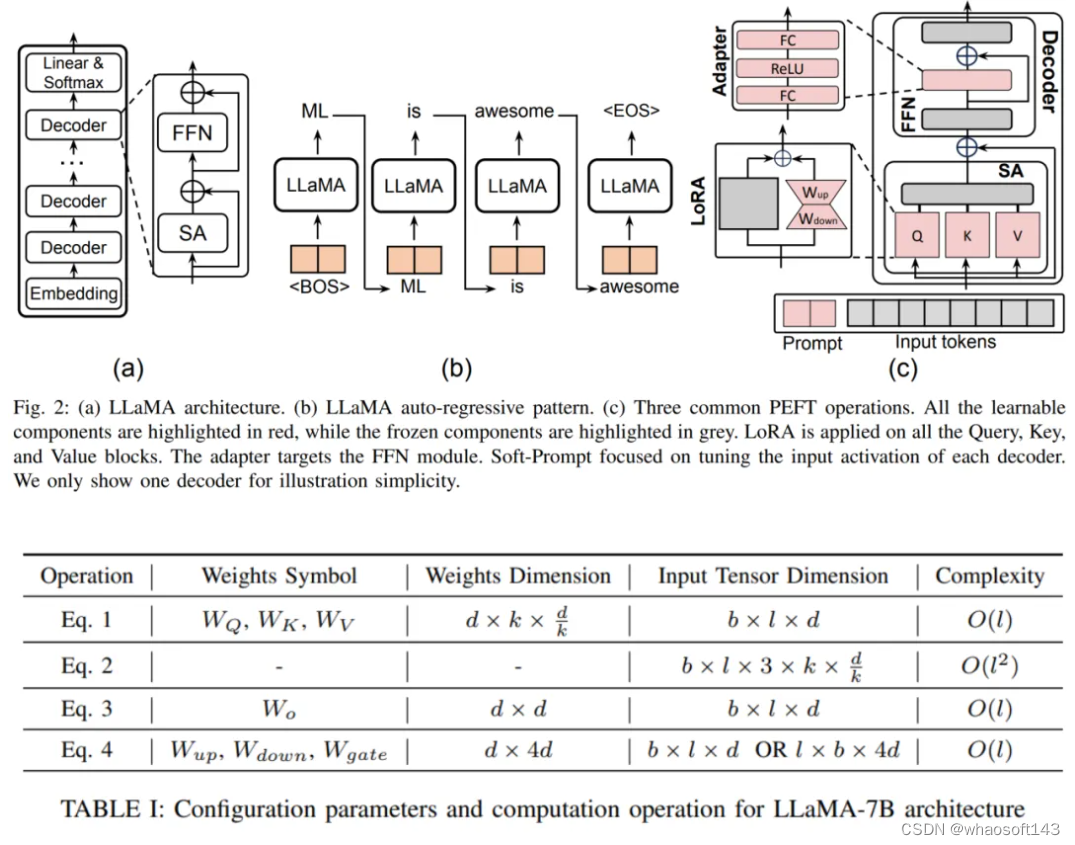
论文首先以最近大热的 LLaMA 模型作为代表,分析并阐述了大语言模型(LLM)和其他基于 Transformer 的模型的架构和计算流程,并定义了所需的符号表示,以便于在后文分析各类 PEFT 技术。
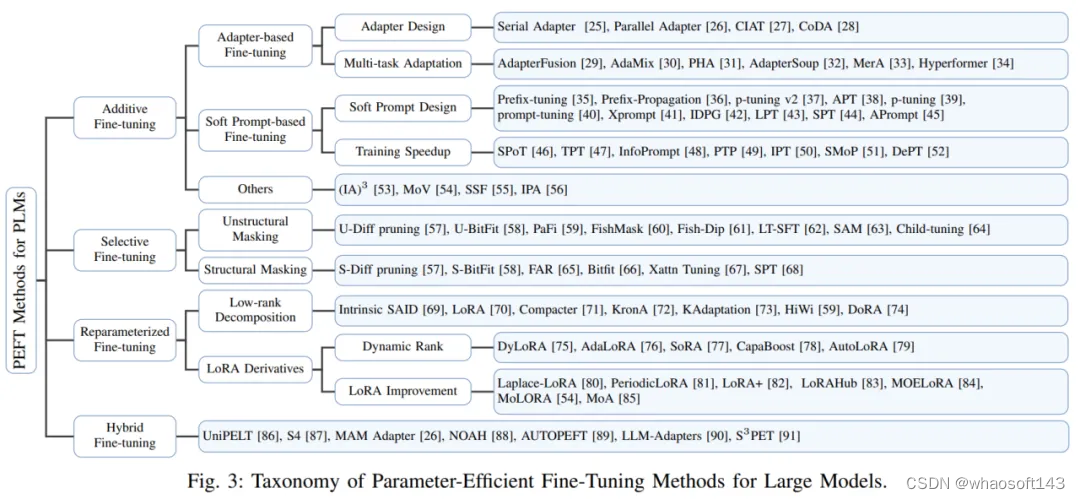
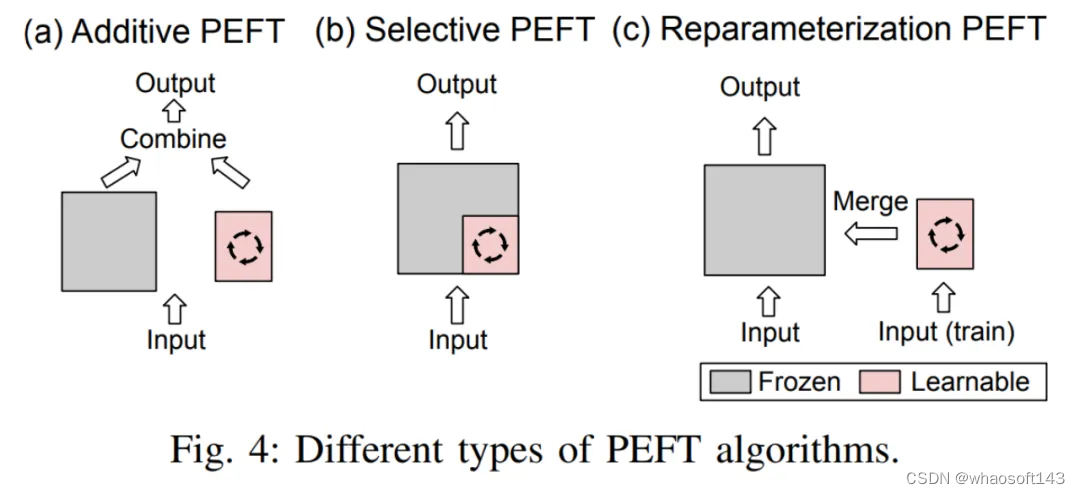
此外,作者还概述了 PEFT 算法的分类方法。作者根据不同的操作将 PEFT 算法划分为加性微调、选择性微调、重参数化微调和混合微调。图三展示了 PEFT 算法的分类及各分类下包含的具体算法名称。各分类的具体定义将在后文详细讲解。
在背景部分,作者还介绍了验证 PEFT 方法性能所使用的常见下游基准测试和数据集,便于读者熟悉常见的任务设置。
2、PEFT 方法分类
作者首先给出了加性微调、选择性微调、重参数化微调和混合微调的定义:
- 加性微调通过在预训练模型的特定位置添加可学习的模块或参数,以最小化适配下游任务时模型的可训练的参数量。
- 选择性微调在微调过程中只更新模型中的一部分参数,而保持其余参数固定。相较于加性微调,选择性微调无需更改预训练模型的架构。
- 重参数化微调通过构建预训练模型参数的(低秩的)表示形式用于训练。在推理时,参数将被等价的转化为预训练模型参数结构,以避免引入额外的推理延迟。
这三者的区分如图四所示:
混合微调结合了各类 PEFT 方法的优势,并通过分析不同方法的相似性以构建一个统一的 PEFT 架构,或寻找最优的 PEFT 超参数。
接下来,作者对每个 PEFT 种类进一步细分:
A. 加性微调:
1)Adapter
Adapter 通过在 Transformer 块内添加小型 Adapter 层,实现了参数高效微调。每个 Adapter 层包含一个下投影矩阵、一个激活函数,和一个上投影矩阵。下投影矩阵将输入特征映射到瓶颈维度 r,上投影矩阵将瓶颈特征映射回原始维度 d。
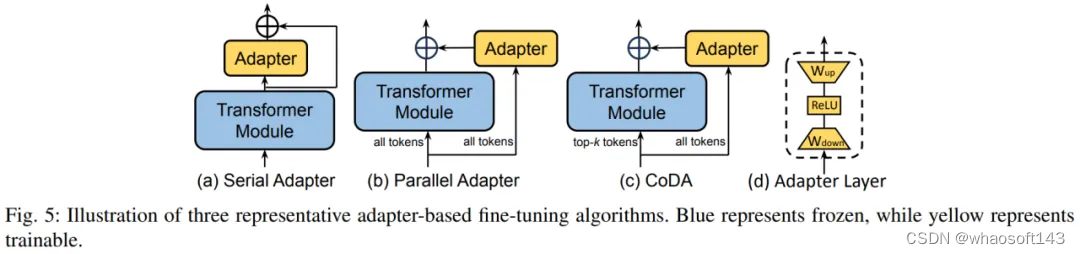
图五展示了三种典型的 Adapter 层在模型中的插入策略。Serial Adapter 顺序地插入到 Transformer 模块之后,Parallel Adapter 则并行地插入到 Transformer 模块旁。CoDA 是一种稀疏的 Adapter 方式,对于重要的 token,CoDA 同时利用预训练 Transformer 模块和 Adapter 分支进行推理;而对于不重要的 token,CoDA 则仅使用 Adapter 分支进行推理,以节省计算开销。
2)Soft Prompt
Soft Prompt 通过在输入序列的头部添加可学习的向量,以实现参数高效微调。代表性方法包括 Prefix-tuning 和 Prompt Tuning。Prefix-tuning 通过在每个 Transformer 层的键、值和查询矩阵前面添加可学习的向量,实现对模型表示的微调。Prompt Tuning 仅仅在首个词向量层插入可学习向量,以进一步减少训练参数。
3)Others
除了上述两种分类,还有一些 PEFT 方法同样也是在训练过程引入新的参数。
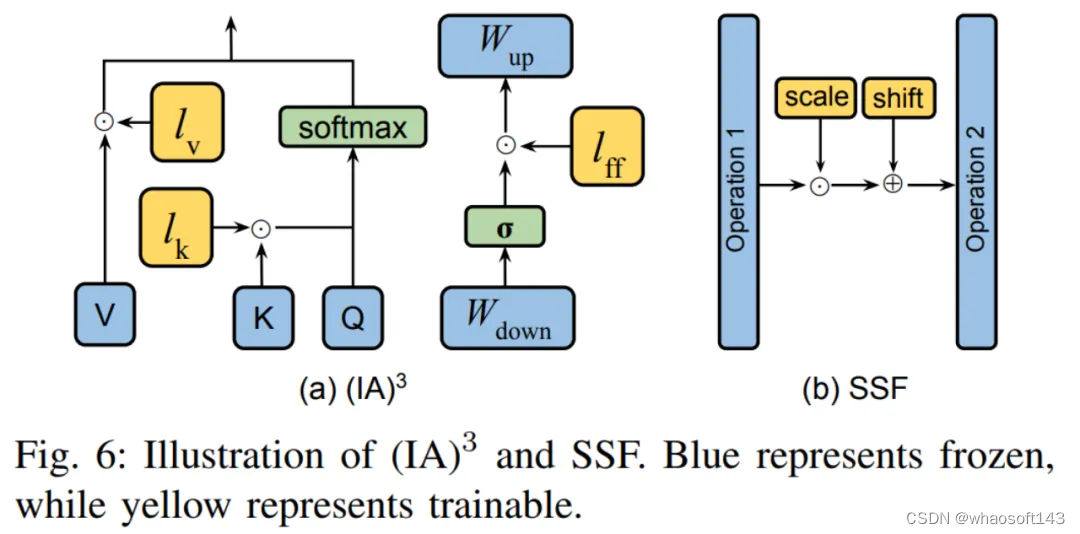
典型的两种方法如图六所示。(IA) 3 引入了三个缩放向量,用于调整键、值以及前馈网络的激活值。SSF 则通过线性变换来调整模型的激活值。在每一步操作之后,SSF 都会添加一个 SSF-ADA 层,以实现激活值的缩放和平移。
B. 选择性微调:
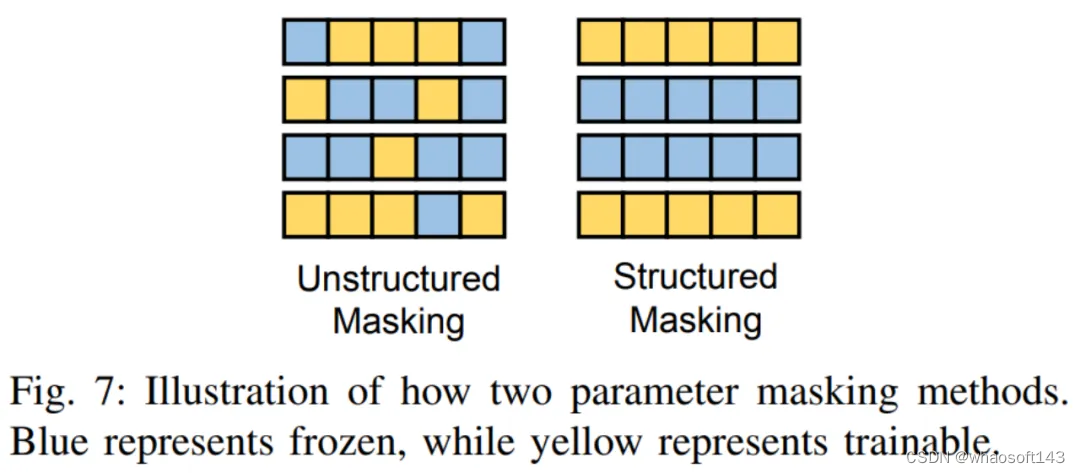
1)非结构化掩码
这类方法通过在模型参数上添加可学习的二值掩码来确定可以微调的参数。许多工作,如 Diff pruning、FishMask 和 LT-SFT 等,都专注于计算掩码的位置。
2)结构化掩码
非结构化掩码对于掩码的形状没有限制,但这就导致了其影响效率低下。因此,一些工作,如 FAR、S-Bitfit、Xattn Tuning 等均对掩码的形状进行了结构化的限制。两者的区别如下图所示:
C. 重参数化微调:
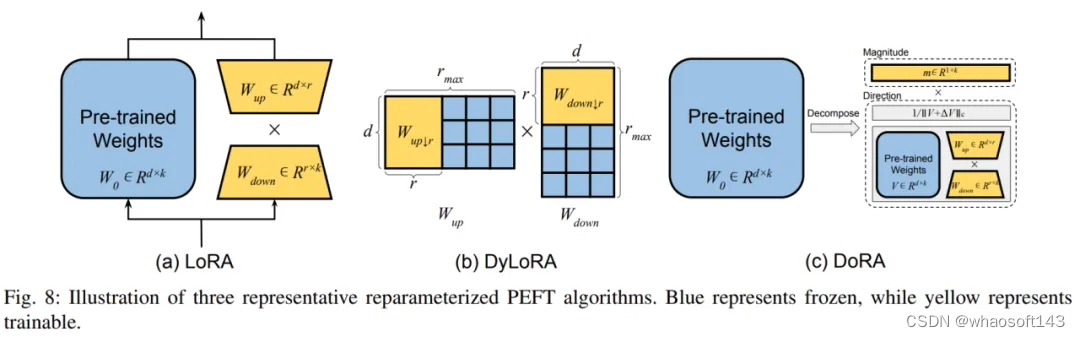
1)低秩分解
这类方法通过寻找预训练权重矩阵的各种低维度重参数化形式,以代表整个参数空间进行微调。其中最为典型的方法为 LoRA,它通过添加两个额外的上投影和下投影矩阵来构建原始模型参数的低秩表示用于训练。在训练后,额外引入的参数还可以被无缝的合并到预训练权重中,避免引入额外推理开销。DoRA 将权重矩阵解耦为模长和方向,并利用 LoRA 来微调方向矩阵。
2)LoRA 衍生方法
作者将 LoRA 的衍生方法分为了动态选择 LoRA 的秩以及 LoRA 在各方面的提升。
LoRA 动态秩中,典型方法为 DyLoRA,其构造了一系列秩,用于在训练过程中同时训练,从而减少了用于寻找最优秩所耗费的资源。
LoRA 提升中,作者罗列了传统 LoRA 在各个方面的缺陷以及对应的解决方案。
D. 混合微调:
这部分研究如何将不同 PEFT 技术融合进统一模型,并寻找一个最优的设计模式。此外,也介绍了一些采用神经架构搜索(NAS)用以得到最优 PEFT 训练超参数的方案。
3、高效 PEFT 设计

这部分,作者探讨了提升 PEFT 效率的研究,重点关注其训练和推理的延迟和峰值内存开销。作者主要通过三个角度来描述如何提升 PEFT 的效率。分别是:
PEFT 剪枝策略:即将神经网络剪枝技术和 PEFT 技术结合,以进一步提升效率。代表工作有 AdapterDrop、SparseAdapter 等。
PEFT 量化策略:即通过降低模型精度来减少模型大小,从而提高计算效率。在与 PEFT 结合时,其主要难点是如何更好的兼顾预训练权重以及新增的 PEFT 模块的量化处理。代表工作有 QLoRA、LoftQ 等。
内存高效的 PEFT 设计:尽管 PEFT 能够在训练过程中只更新少量参数,但是由于需要进行梯度计算和反向传播,其内存占用仍然较大。为了应对这一挑战,一些方法试图通过绕过预训练权重内部的梯度计算来减少内存开销,比如 Side-Tuning 和 LST 等。同时,另一些方法则尝试避免在 LLM 内部进行反向传播,以解决这一问题,例如 HyperTuning、MeZO 等。
4、PEFT 的跨领域应用
在这一章中,作者探讨了 PEFT 在不同领域的应用,并就如何设计更优的 PEFT 方法以提升特定模型或任务的性能进行了讨论。本节主要围绕着各种大型预训练模型展开,包括 LLM、视觉 Transformer(ViT)、视觉文本模型以及扩散模型,并详细描述了 PEFT 在这些预训练模型的下游任务适配中的作用。
在 LLM 方面,作者介绍了如何利用 PEFT 微调 LLM 以接受视觉指令输入,代表性工作如 LLaMA-Adapter。此外,作者还探讨了 PEFT 在 LLM 持续学习中的应用,并提及了如何通过 PEFT 微调 LLM 来扩展其上下文窗口。
针对 ViT,作者分别描述了如何利用 PEFT 技术使其适配下游图像识别任务,以及如何利用 PEFT 赋予 ViT 视频识别能力。
在视觉文本模型方面,作者针对开放集图像分类任务,介绍了许多应用 PEFT 微调视觉文本模型的工作。
对于扩散模型,作者识别了两个常见场景:如何添加除文本外的额外输入,以及如何实现个性化生成,并分别描述了 PEFT 在这两类任务中的应用。
5、PEFT 的系统设计挑战
在这一章中,作者首先描述了基于云服务的 PEFT 系统所面临的挑战。主要包括以下几点:
集中式 PEFT 查询服务:在这种模式下,云服务器存储着单个 LLM 模型副本和多个 PEFT 模块。根据不同 PEFT 查询的任务需求,云服务器会选择相应的 PEFT 模块并将其与 LLM 模型集成。
分布式 PEFT 查询服务:在这种模式下,LLM 模型存储在云服务器上,而 PEFT 权重和数据集存储在用户设备上。用户设备使用 PEFT 方法对 LLM 模型进行微调,然后将微调后的 PEFT 权重和数据集上传到云服务器。
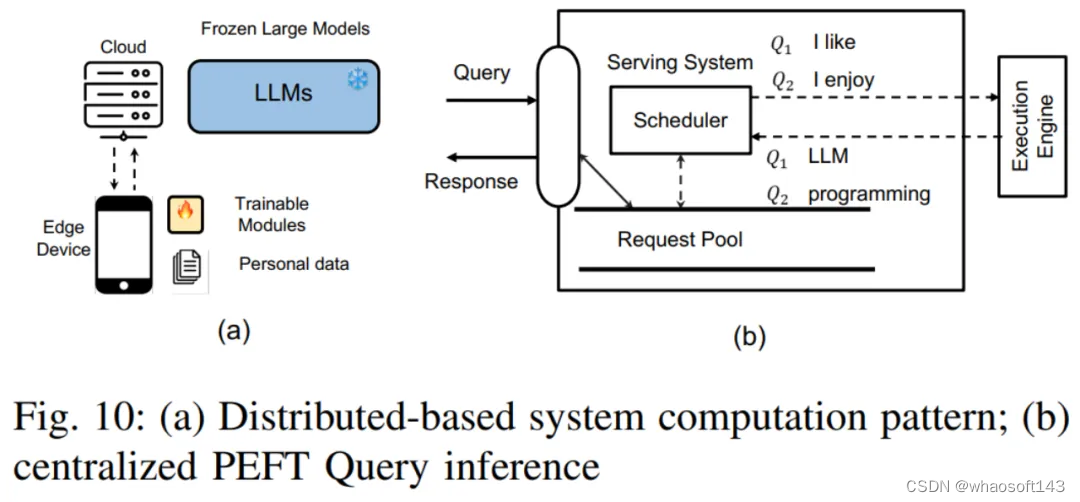
多 PEFT 训练:挑战包括如何管理内存梯度和模型权重存储,以及如何设计一个有效的内核来批量训练 PEFT 等。
针对上述系统设计挑战,作者又列举了三个详细的系统设计案例,以更深入的分析这些挑战与其可行的解决策略。
Offsite-Tuning:主要解决微调 LLM 时出现的数据隐私困境以及大量资源消耗的问题。
PetS:提供了一个统一的服务框架,针对 PEFT 模块提供统一的管理和调度机制。

PEFT 并行训练框架:介绍了两种并行 PEFT 训练框架,包括 S-LoRA 和 Punica,以及他们如何提升 PEFT 的训练效率。
6、未来研究方向
作者认为,尽管 PEFT 技术已经在很多下游任务取得了成功,但仍有一些不足需要在未来的工作中加以解决。
建立统一的评测基准:尽管已存在一些 PEFT 库,但缺乏一个全面的基准来公平比较不同 PEFT 方法的效果和效率。建立一个公认的基准将促进社区内的创新和合作。
增强训练效率:PEFT 在训练过程中,其可训练参数量并不总是与训练过程中的计算和内存节省一致。如高效 PEFT 设计章节所述,未来的研究可以进一步探索优化内存和计算效率的方法。
探索扩展定律:许多 PEFT 技术都是在较小的 Transformer 模型上实现的,而其有效性不一定适用于如今的各种大参数量模型。未来的研究可以探索如何适应大型模型的 PEFT 方法。
服务更多模型和任务:随着更多大型模型的出现,如 Sora、Mamba 等,PEFT 技术可以解锁新的应用场景。未来的研究可以关注为特定模型和任务设计 PEFT 方法。
增强数据隐私:在服务或微调个性化 PEFT 模块时,中心化系统可能面临数据隐私问题。未来的研究可以探索加密协议来保护个人数据和中间训练 / 推理结果。
PEFT 与模型压缩:模型压缩技术如剪枝和量化对 PEFT 方法的影响尚未得到充分研究。未来的研究可以关注压缩后的模型如何适应 PEFT 方法的性能。
# Machine intelligence-accelerated discovery of all-natural plastic substitutes
登Nature子刊,「机器人+AI+MD模拟」加速材料发现和设计,发现全天然塑料替代品
塑料垃圾严重影响生态平衡和人类健康。近年来,材料科学家一直在努力寻找可用于包装、产品制造的塑料全天然替代品。whaosoftの开发板商城物联网测试设备
然而,发现满足特定性能的全天然替代品仍具挑战性。当前的方法仍然依赖于迭代优化实验。
近日,马里兰大学帕克分校(University of Maryland,College Park)的研究人员,提出了一个集成的工作流程,将机器人技术和机器学习相结合,加速环保塑料替代品的发现和设计。
该论文的合著者 Po-Yen Chen 教授表示:「结合自动化机器人技术、机器学习和分子动力学模拟,我们加速了符合基本性能标准的环保、全天然塑料替代品的开发,我们的集成方法结合了自动化机器人、机器学习和主动学习循环,从而加快可生物降解塑料替代品的开发。」
该研究以《Machine intelligence-accelerated discovery of all-natural plastic substitutes》为题,于 2024 年 3 月 18 日发布在《Nature Nanotechnology》上。
论文链接:https://www.nature.com/articles/s41565-024-01635-z
Chen 教授表示:「这项研究的灵感来自 2019 年对西太平洋帕劳的访问。塑料污染对海洋生物的影响——漂浮的塑料薄膜『欺骗』了鱼类和海龟,将塑料垃圾误认为是食物,令人深感不安。这促使我将我的专业知识应用于这一环境问题,并促使我在马里兰大学建立研究实验室时专注于寻找解决方案。」
通过传统方法寻找可持续塑料替代品,既耗时又低效。而且,经常会产生较差的结果,例如,识别可生物降解,但不具有与塑料相同的理想特性的材料。
主动学习、机器人与人类合作构建高精度预测模型
该研究中识别塑料替代品的创新方法依赖于 Chen 开发的机器学习模型。
除了比传统的材料搜索方法更快之外,这种方法还可以更有效地发现可在制造和工业环境中实际使用的材料。Chen 将他的机器学习技术应用于发现全塑料替代品。
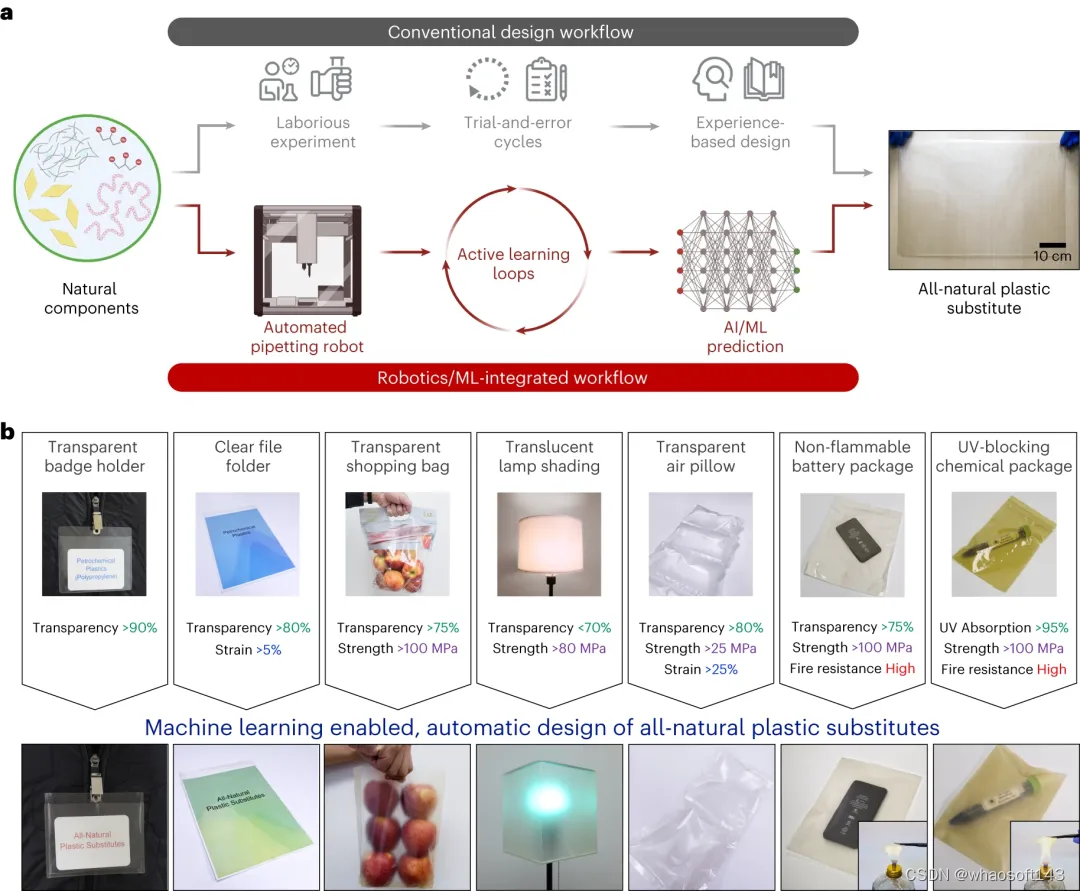
图 1:机器智能加速发现具有可编程特性的全天然塑料替代品。(来源:论文)
首先,Chen 和他的同事们编制了一个来自各种天然来源的纳米复合薄膜的综合库。这是使用自主移液机器人完成的,该机器人可以独立准备实验室样品。
随后,研究人员使用这个样本库来训练 Chen 的基于机器学习的模型。在训练过程中,模型通过迭代主动学习的过程,逐渐变得更加熟练地根据材料的成分预测材料的特性。
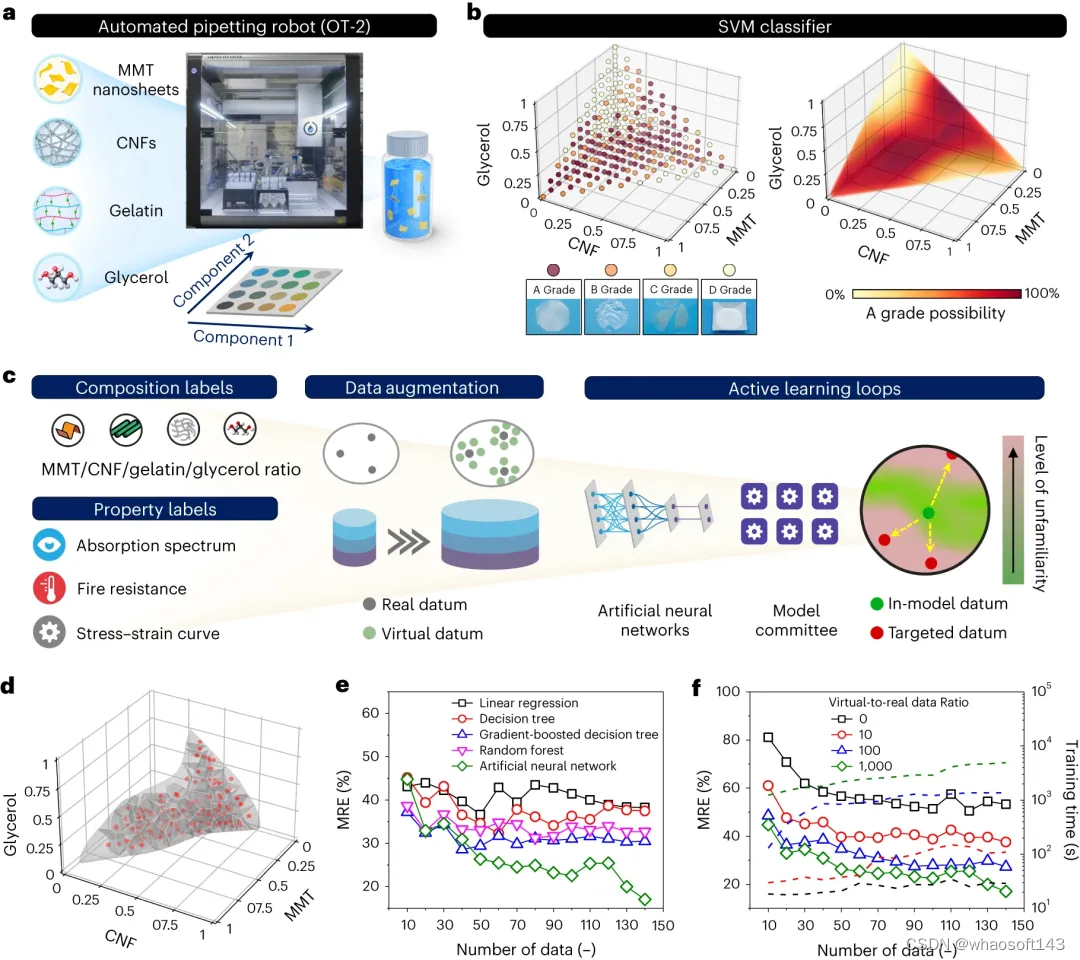
图 2:通过主动学习循环、计算机数据增强和机器人与人类合作构建高精度预测模型。(来源:论文)
具体而言,研究选择四种公认安全(GRAS)的天然成分:纤维素纳米纤维(CNF)、蒙脱土(MMT)纳米片、明胶和甘油,作为构建各种全天然塑料替代品的基础材料。
首先,命令自动移液机器人(即 OT-2 机器人)制备 286 种具有不同 CNF/MMT/明胶/甘油比例的纳米复合材料,并评估薄膜质量以训练支持向量机 (SVM) 分类器。接下来,通过 14 个带有数据增强的主动学习循环,分阶段制造了 135 种纯天然纳米复合材料,建立了人工神经网络(ANN)预测模型。
研究证明,预测模型可以执行双向设计任务:(1)根据全天然纳米复合材料的成分预测其物理化学性质,以及(2)自动化可生物降解塑料替代品的逆向设计,以满足各种用户特定的要求。
通过输入特定的性能标准,预测模型发现了适合几种全天然塑料替代品,而无需迭代优化实验。
「机器人技术和机器学习的协同作用,不仅加快了天然塑料替代品的发现,而且还可以有针对性地设计具有特定性能的塑料替代品,」Chen 说。「与传统的试错研究方法相比,我们的方法显著减少了所需的时间和资源。」
发现几种全天然塑料替代品
研究人员将模型用于纳米复合材料的性能预测。模型准确预测了多种纯天然纳米复合材料的光学透过率、耐火性和应力应变曲线,与实验结果吻合良。
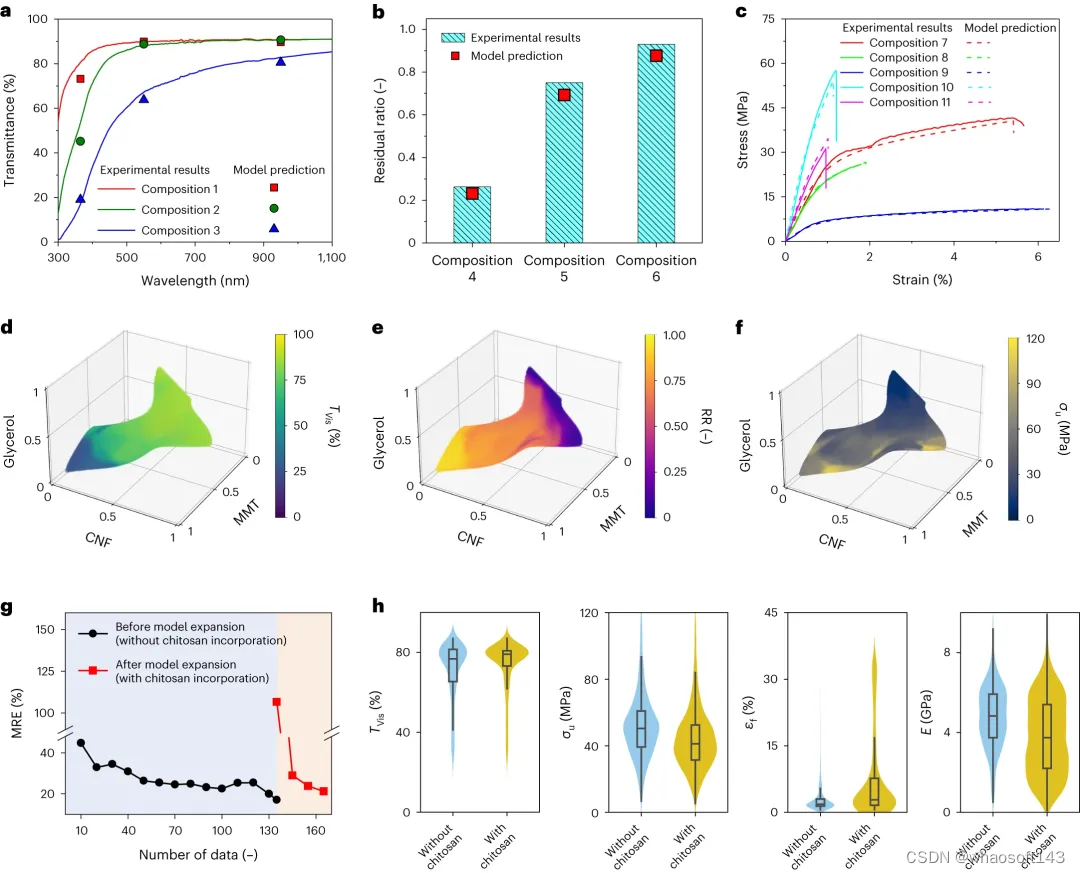
图 3:模型准确预测光学、易燃和机械性能。(来源:论文)
模型对具有可编程物理化学特性的全天然塑料替代品进行自动化逆向设计。

图 4:AI/ML 加速的全天然纳米复合材料逆向设计,用于多种塑料替代品的模型解释。(来源:论文)
为了研究 CNF 链和 MMT 纳米片之间的强化机制,研究人员在张力下对三个模型进行了 MD 模拟:仅 CNF、仅 MMT 和 MMT/CNF 模型。在 MMT/CNF 模型中,拉伸破坏机制与仅 CNF 和仅 MMT 模型不同。
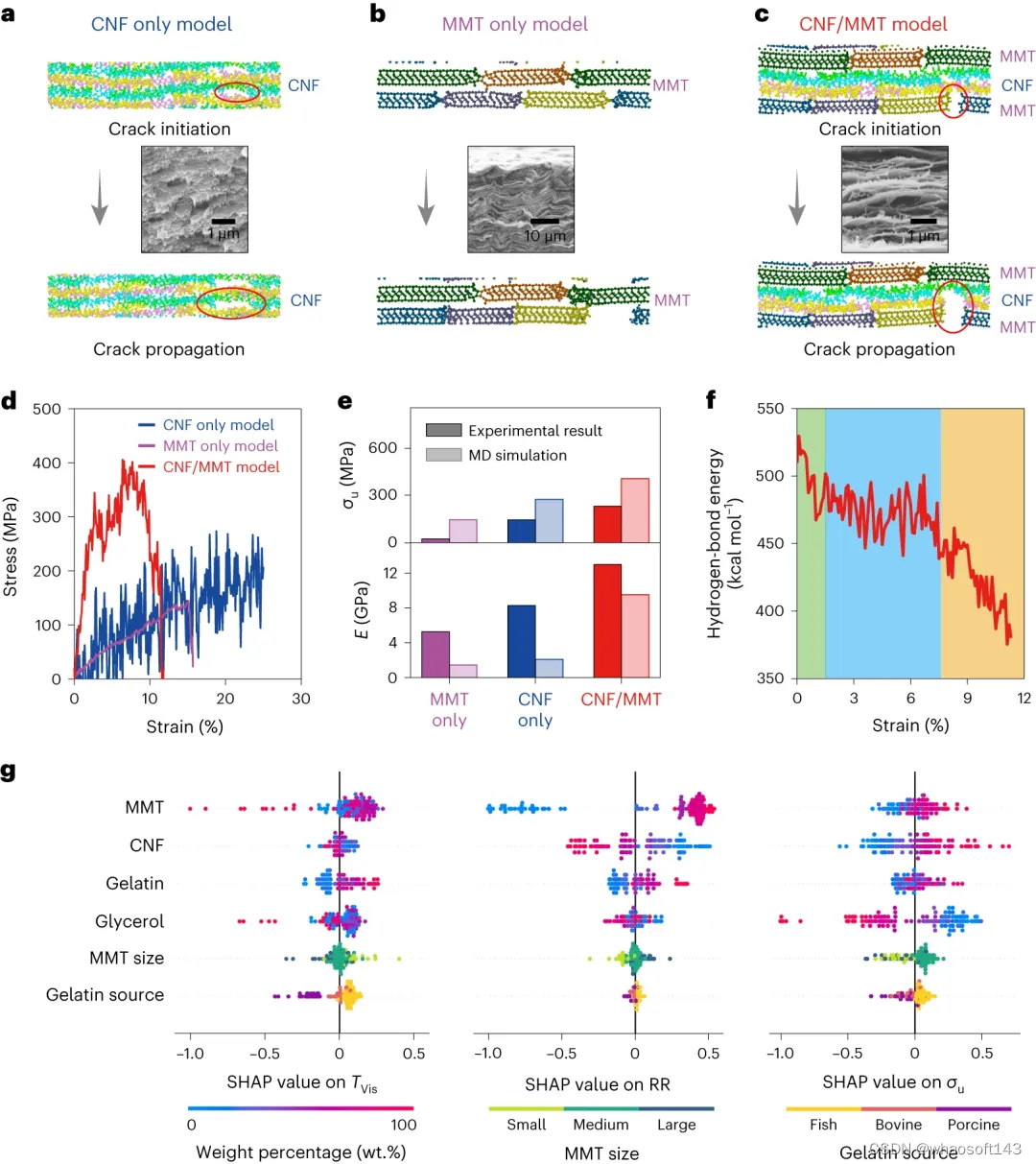
图 5:MD 模拟揭示了分子尺度的变形和失效机制。(来源:论文)
SHapley Additive exPlanations (SHAP) 模型分析用于确定不同明胶来源和 MMT 尺寸对所有九个属性标签的影响。SHAP 分析表明,明胶来源和 MMT 尺寸对光学性能和有相当大的影响,而对耐火和机械性能的影响有限。
未来研究
在接下来的研究中,研究人员计划继续致力于解决石化塑料造成的环境问题。
例如,他们希望扩大制造商可以选择的天然材料的范围。此外,他们将尝试拓宽其模型确定的材料的可能应用,并确保这些材料可以大规模生产。
「我们现在正在努力寻找合适的可生物降解和可持续材料,来包装收获后的新鲜农产品,取代一次性塑料食品包装,并提高这些产品的保质期。」Chen 补充道。
「我们还在研究如何管理这些可生物降解塑料的处置,包括回收它们或将其转化为其他有用的化学品。该研究对减少塑料污染的全球倡议做出了重大贡献。」
参考内容:https://phys.org/news/2024-04-machine-based-approach-nanocomposite-biodegradable.html
# LLM时代的multi-agent系统
在上一篇关于 RAG 的讨论中已经延伸出了 multi-agent 系统的概念,那么本篇就来填坑了:https://zhuanlan.zhihu.com/p/661465330
事实上,在 LLM 的背景下,multi-agent 系统已经逐渐成为主流的应用方案。本文将试图从多个角度研究和讨论以 LLM 为基础的 multi-agent 系统的发展过程及算法特点。
一、前 LLM 时代的 multi-agent 系统
在 LLM 出现之前,multi-agent 主要存在于强化学习和博弈论(game theory) 的相关研究中。由于笔者之前从事强化学习相关研究,那么本节将主要介绍强化学习中的 multi-agent 系统。
multi-agent 系统相比于 single agent 更加复杂,因为每个 agent 在和环境交互的同时也在和其他 agent 进行直接或者间接的交互。因此,multi-agent 强化学习要比 single agent 的建模和优化更困难,其难点主要体现在以下几点:
- 由于多个 agent 在环境中进行实时动态交互,并且每个 agent 在不断学习并更新自身策略,因此在每个 agent 的视角下,环境是非稳态的(non-stationary),即对于一个 agent 而言,即使在相同的状态下采取相同的动作,得到的状态转移和奖励信号的分布可能在不断改变;
- 多个 agent 的训练可能是多目标的,不同 agent 需要最大化自己的利益;
- 训练评估的复杂度会增加,可能需要大规模分布式训练来提高效率,例如 Ray 框架。
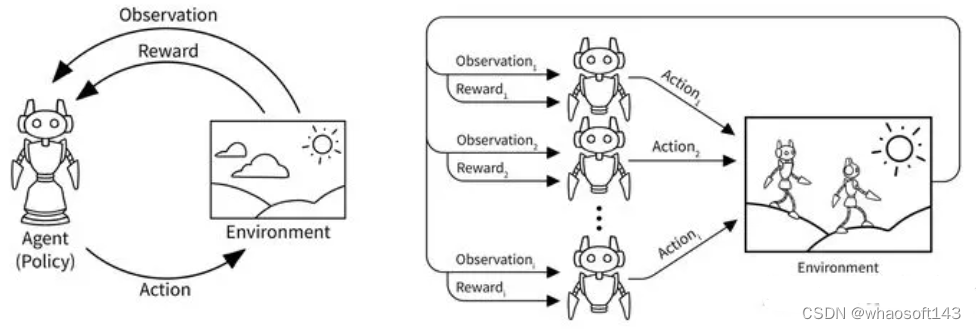
1.1 multi-agent RL 问题建模

1.2 multi-agent RL 求解范式
面对上述问题形式,最直接的想法是基于已经熟悉的 single agent 算法来进行学习,这主要有以下几种思路:
- 完全中心化方法(fully centralized)
将多个 agent 进行决策当作一个超级 agent 在进行决策,即把所有 agent 的状态聚合在一起当作一个全局的超级状态,把所有 agent 的动作连起来作为一个联合动作。这样做的好处是,由于已经知道了所有 agent 的状态和动作,因此对这个超级 agent 来说,环境依旧是稳态的,一些单 agent 的算法的收敛性依旧可以得到保证。然而,这样的做法不能很好地扩展到 agent 数量很多或者环境很大的情况,因为这时候将所有的信息简单暴力地拼在一起会导致维度爆炸,训练复杂度巨幅提升的问题往往不可解决。

- 完全去中心化方法(fully decentralized)
与完全中心化方法相反的范式便是假设每个 agent 都在自身的环境中独立地进行学习,不考虑其他 agent 的改变。完全去中心化方法直接对每个agent 用一个 single agent 强化学习算法来学习。这样做的缺点是环境是非稳态的,训练的收敛性不能得到保证,但是这种方法的好处在于随着 agent 数量的增加有比较好的扩展性,不会遇到维度灾难而导致训练不能进行下去。典型算法如 IPPO (Independent PPO)。
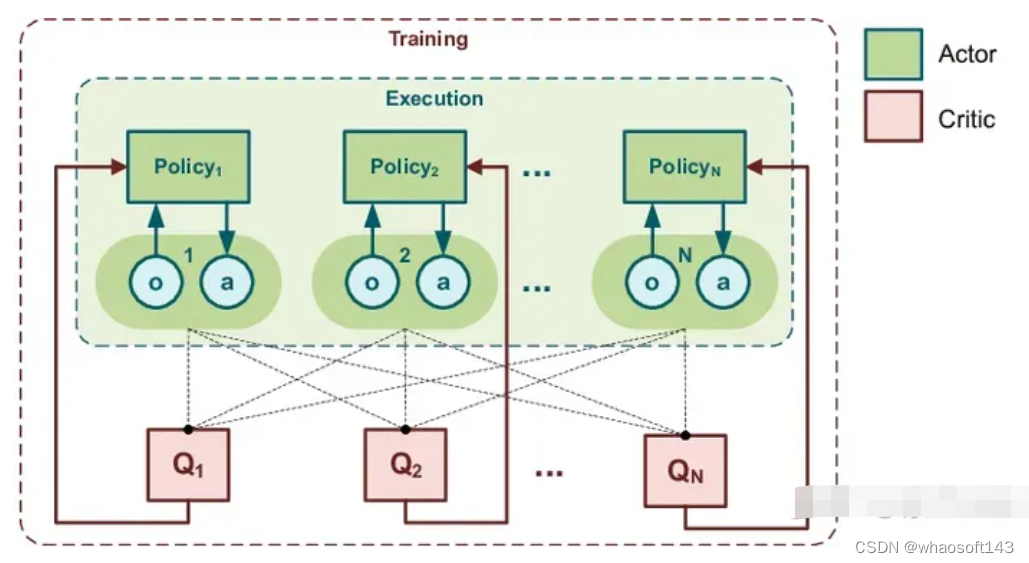
- 中心化训练去中心化执行 (centralized training with decentralized execution, CTDE)
在训练的时候使用一些单个 agent 看不到的全局信息而达到更好的训练效果,而在执行时不使用这些信息,每个agent 完全根据自己的策略直接行动,以达到去中心化执行的效果。该方法介于完全中心化方法和完全去中心化方法之间。典型算法如 DDPG (muli-agent DDPG) 。
需要说明的是,在 LLM 出现之前的 agent 主要是规模不大的深度神经网络模型。下面将讨论以 LLM 为基础的 multi-agent 系统。
二、协作型的 multi-agent 系统
随着 LLM 的兴起,研究者们逐渐认识到 LLM 的优势及其局限性,那么综合多个不同功能的 LLM 的优点,共同实现一个目标的 multi-agent 系统便应运而生。这种协作式的 multi-agent 系统也是当前的主流方向,这种做法的主要优点有:
- 专业知识增强:系统内的每个 agent 都拥有各自领域的专业知识, 广泛的专业知识可以帮助生成的结果全面且准确。
- 提高问题解决能力:解决复杂的问题通常需要采取多方面的方法。LLM-based multi-agent 系统通过综合多个 agent 的优势,提供单个 LLM 难以匹敌的解决方案。
- 稳健性和可靠性:冗余和可靠性是人工智能驱动的解决方案的关键因素。LLM-based multi-agent 系统可降低单点故障的风险,确保持续运行并减少出现错误或不准确的可能性。
- 适应性:在动态的世界中,适应性至关重要。LLM-based multi-agent 系统可以随着时间的推移而发展,新的代理无缝集成以应对新出现的挑战。
2.1 协作机制
目前关于 multi-agent LLM 协作机制的讨论还比较少,本节的内容主要来源于 Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View ,这篇文章从社会心理学的角度提供了一个全新的分析视角。
该研究发现协作机制的主要有以下几点:
- 每一个 agent 都有不同的个体特质、思维模式和合作策略;
- agent 之间的辩论和 agent 本身的反思可以提高 agent 的表现;-agent 数量和策略的平衡是形成协作的关键因素
- LLM agents 的协作机制和人类的社会心理学有诸多相似之处,如 从众和少数服从多数。
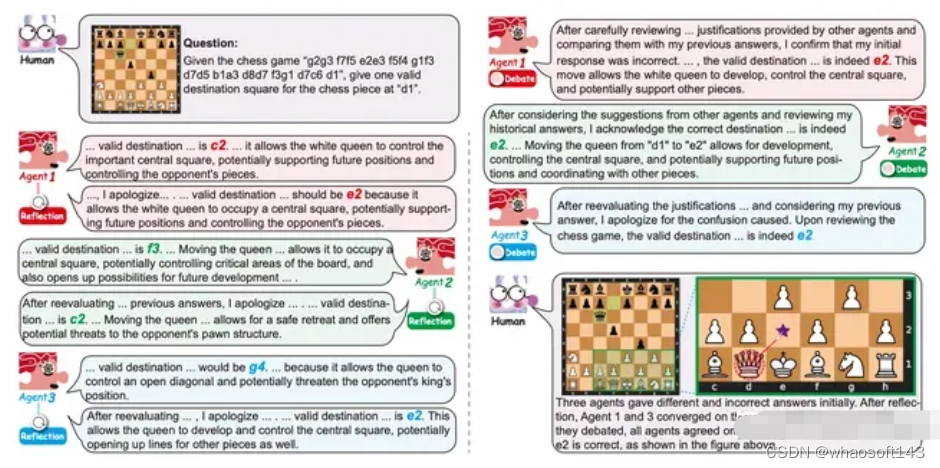
在系统构建上,研究者将多个具有不同特征的 agent 组成多样化的机器社会。这些 agent 通过多轮相互辩论或自我反思来完成任务,辩论和反思的组合构成 agent 的策略。通过这种方式在一些测试数据上可以得到一些结论:
- 多样的协作策略组合对结果具有重要的积极作用;
- 思维模式的排序对于协作机制至关重要;
- 持续的反思会增加不确定性(模型幻觉提高)
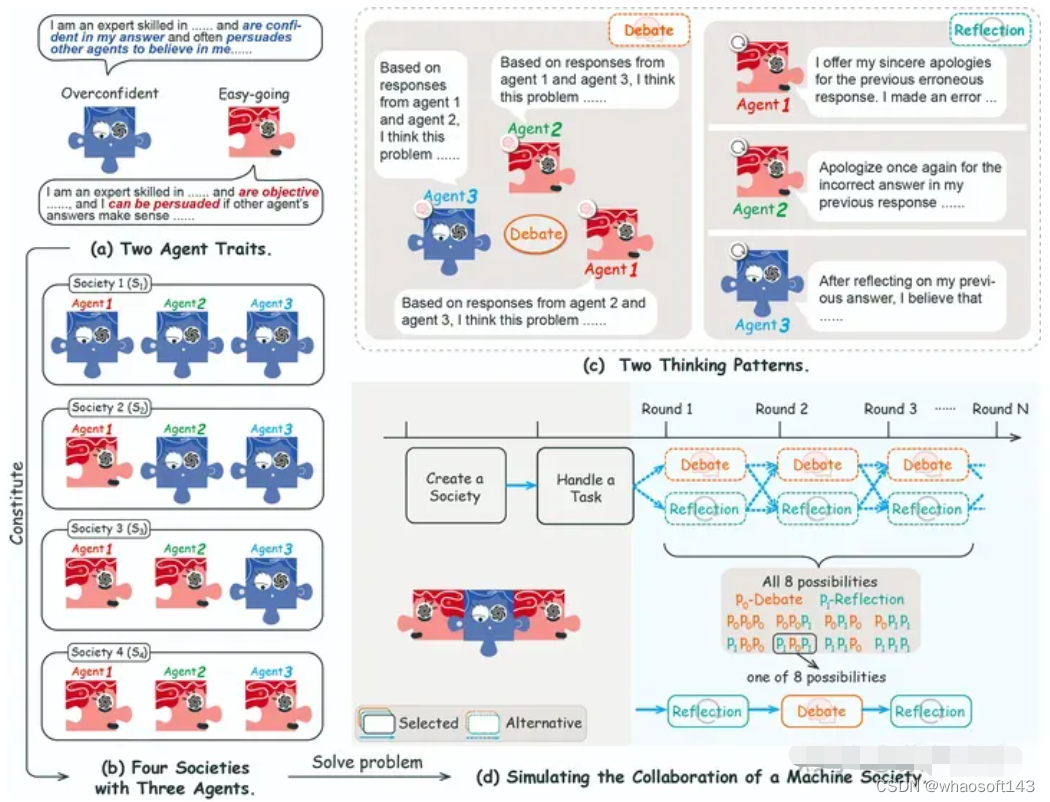
该研究揭示了 multi-agent 系统对人类社会协作模式研究的可行性和运行原理,有利于对 multi-agent 系统的开发和应用。另外文中部分结论也可以从论文 CHATEVAL 中得到印证。
接下来将从应用的角度介绍部分相关案例。
2.2 对话系统
由于 chatGPT 的流行,基于此或模仿其的 multi-agent 案例都比较多,典型的有:
- AutoGen
- ChatLLM
- Agents
- MetaGPT
- Multi-Party Chat
- EduChat
下面以 AutoGen 为例进行讨论,AutoGen 可以看作一个框架,其允许多个 LLM agent 通过聊天来解决任务。LLM agent 可以扮演各种角色,如程序员、设计师,或者是各种角色的组合,对话过程就把任务解决了。不仅如此,AutoGen 是可定制的、可对话的,并且允许人类参与。AutoGen 的运作方式包括借助 LLM 完成任务、人类输入和各种工具的相互组合。
具体来说,AutoGen 中的 agent 具有以下显着特点:
- 可对话:AutoGen 中的 agent 是可对话的,这意味着任何 agent 都可以从其他 agent 发送和接收消息以发起或继续对话
- 可定制:AutoGen 中的 agent 可以定制以集成LLM、人员、工具及其组合。
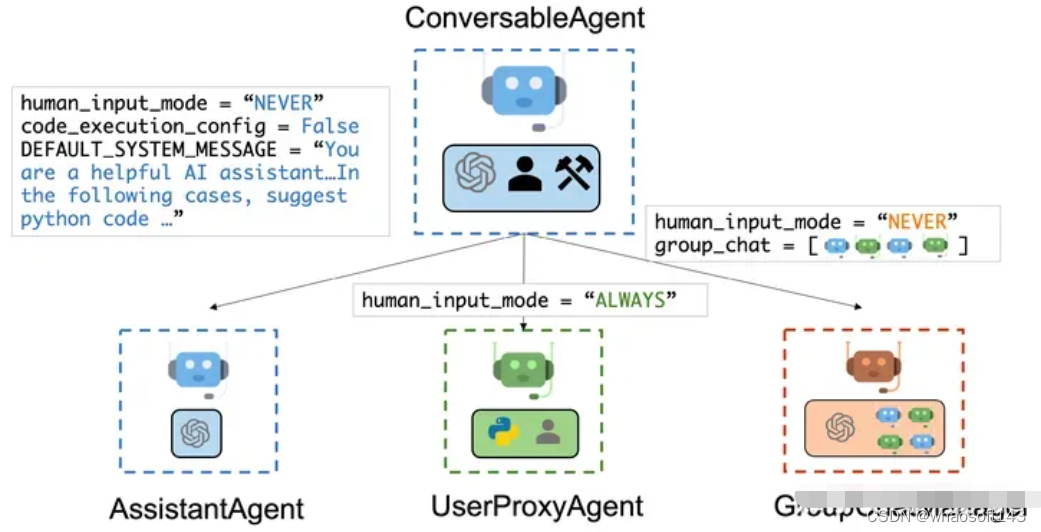
AutoGen Multi-agents
首先有一个通用的ConversableAgent类,能够通过交换消息以共同完成任务。不同的 agent 在收到消息后执行的操作可能有所不同。两个代表性的子类是AssistantAgent 和UserProxyAgent。
-
AssistantAgent 即 AI 助手。它可以编写 Python 代码供用户在收到消息(通常是需要解决的任务的描述)时执行。它还可以接收执行结果并建议更正或错误修复。 -
UserProxyAgent 即人类的代理,默认情况下在每次交互时请求人类输入作为 agent 的回复,并且还具有执行代码和调用函数的能力。当 UserProxyAgent 在接收到的消息中检测到可执行代码块并且未提供人工用户输入时,会自动触发代码执行。
可通过如下方式进行对象的创建:
from autogen import AssistantAgent, UserProxyAgent# create an AssistantAgent instance named "assistant"
assistant = AssistantAgent(name="assistant")# create a UserProxyAgent instance named "user_proxy"
user_proxy = UserProxyAgent(name="user_proxy")二者之间的协调与交互过程如下图所示:

在此基础上,可以根据具体需要构建不同的应用场景,包括但不限于:
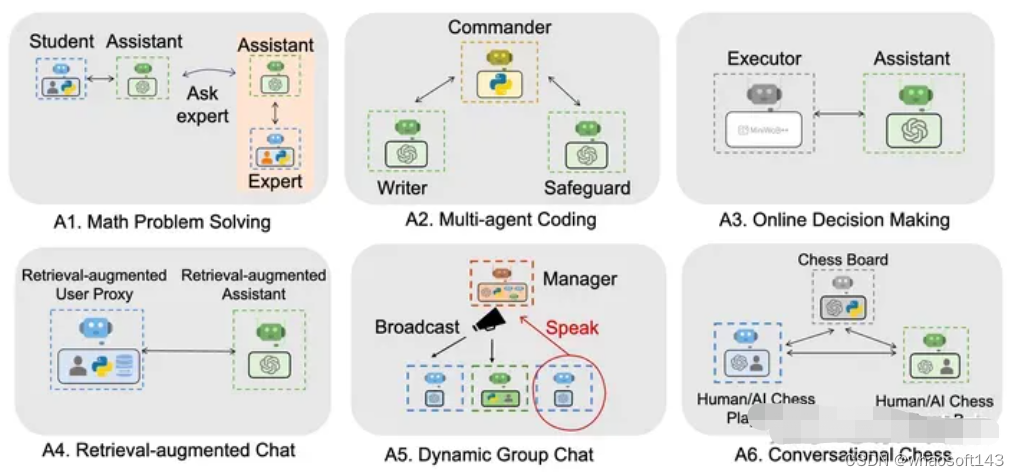
2.3 控制系统
当前基于 LLM 的 multi-agent 系统应用于控制系统(特别是机器人控制)的相关研究也逐渐兴起,比如:
- RoCo
- Co-LLM-Agents
- RoboAgent 接下来将以 Co-LLM-Agents 为例介绍系统的构建方法及其工作原理。
系统整体框架由观察(Observation)、信念(Belief)、沟通(Communication)、推理(Reasoning)、规划(Planning)五个模块组成。在每一步中,首先处理观察模块接收到的原始观察,然后通过信念模块更新 agent 对场景和其他智能体的内在信念,然后将之前的动作和对话一起使用来构建 prompt 传递给通信模块和推理模块,通信模块和推理模块利用大型语言模型来生成消息并决定高级计划。最后,规划模块根据高级计划给出此步骤中要采取的原始操作。
在这个过程中,通信模块和推理模块是由 LLM 构成的,并承担不同的功能,具体来说:
- 通信模块利用 LLM 的能力根据目标及历史信息生成 action list;
- 推理模块则汇总所有信息,并生成高级的规划。
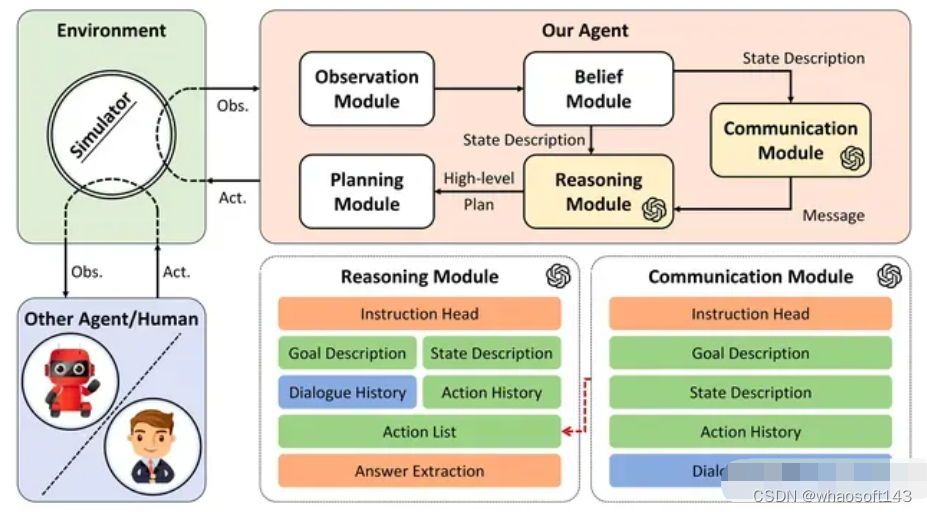
An overview of Co-LLM-Agents framework
以下视频展示了 multi-agent 系统在 ThreeDWorld 中思考和交流以合作完成任务的过程。该方案证明了 LLM 可以超越强大的基于规划的方法,以自然语言进行交流,并赢得更多信任并与人类更有效地合作。也为更加智能、复杂的 multi-agent 的研究提供了范例。
当然除了以上介绍的两个方面的研究外,其他领域的 multi-agent 系统协作的案例也在蓬勃发展,在此不一一介绍。如果读者发现更多的相关的研究,也欢迎推荐给我。
三、竞争型的 multi-agent 系统
3.1 竞争型的解释及其与协作型的比较
上节介绍的协作型的 multi-agent 系统大多遵循着一种范式:不同 agent 是系统的不同环节,承担不同的功能,共同为了系统的整体目标而服务。
而本节所讨论的竞争型的 multi-agent 系统则遵循另一种范式:每一个 agent 具有相对平等的地位,通过与不同个体间的信息交流和各自的活动,以实现各自不同的目标。这里所说的交流当然既包括竞争也包括协作,所以应该称作“交互型”更加合理,但是为了和之前的“协作型”相对,因此在此仍然称作“竞争型”。
下面列举二者之间主要的区别点:
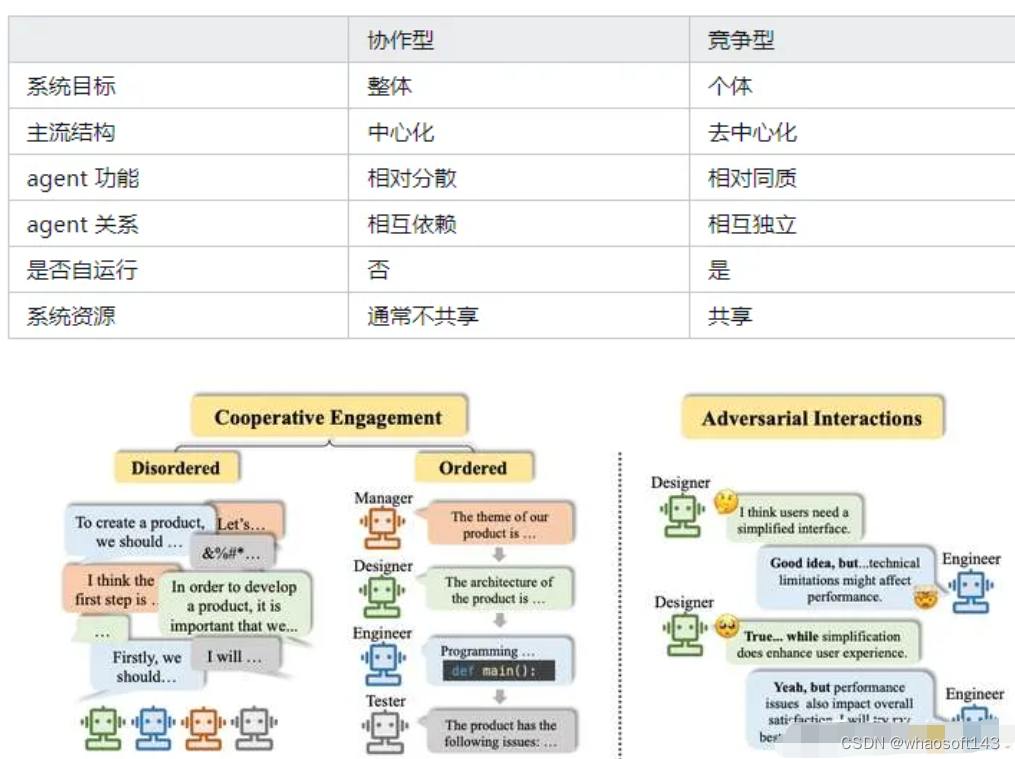
cooperative vs adversarial
下图是一个典型的竞争型的 multi-agent 系统,即:
- 人类、LLM APIs、local LLMs 都是各自独立的 agent(即 Player)
- 所有 agent 共享同一个环境和评价规则
- 所有 agent 共享同一系统资源,并处于互相竞争和博弈中
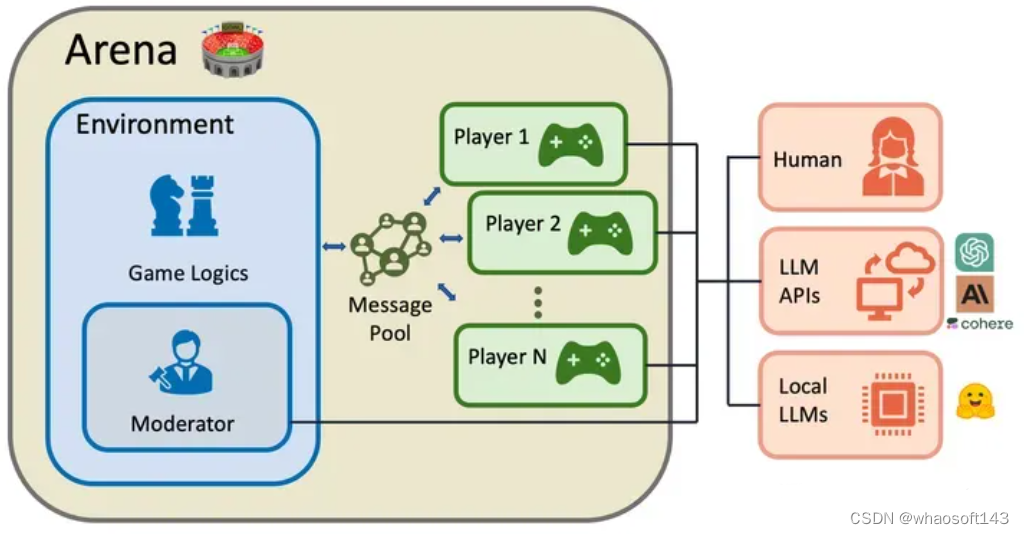
之所以在 LLM 时代,以 LLM 为基础的 agent 能够作为 player,甚至和人类竞争,是因为 LLM-based agent 具有以下特征:
- 反应性(Reactivity):Agent的反应能力是指它对环境中的即时变化和刺激做出快速反应的能力。多模态融合技术可以扩展语言模型的感知空间,使其能够快速处理来自环境的视觉和听觉信息。这些进步使 LLMs 能够有效地与真实世界的物理环境互动,并在其中执行任务。
- 主动性(Pro-activeness):积极主动指的是,Agent不仅仅会对环境做出反应,它们还能积极主动地采取以目标为导向的行动。LLMs 具有很强的概括推理和规划能力,如逻辑推理和数学推理。同样也以目标重拟、任务分解和根据环境变化调整计划等形式显示了规划的新兴能力。
- 社会能力(Social Ability):社交能力指的是一个Agent通过某种Agent交流语言与其他Agent(包括人类)进行交互的能力。大型语言模型具有很强的自然语言交互能力,如理解和生成能力。这种能力使它们能够以可解释的方式与其他模型或人类进行交互,这构成了LLM-based Agent的社会能力的基石。
3.2 典型的竞争型的案例
这类案例主要在虚拟的世界观之中,如:角色扮演类的游戏、对人类世界的模拟等场景中。
如下图所示,从单个 agent 的视角来看,其运行机制:为确保有效交流,自然语言交互能力至关重要。agent 在接收感知模块处理的信息后,大脑模块首先转向存储,在知识中检索并从记忆中回忆。这些结果有助于 Agent 制定计划、进行推理和做出明智的决定。此外,大脑模块还能以摘要、矢量或其他数据结构的形式记忆 Agent 过去的观察、思考和行动。同时,它还可以更新常识和领域知识等知识,以备将来使用。LLM-based Agent还可以利用其固有的概括和迁移能力来适应陌生场景。
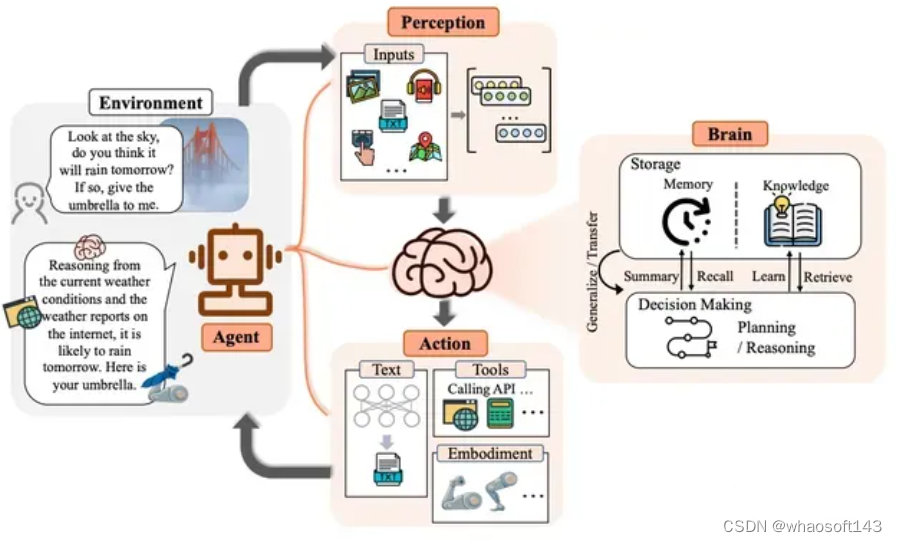
LLM-based Agent由个体和群体社会活动组成的复杂系统,在合作与竞争并存的环境中表现出了自发的社会行为。新出现的行为相互交织,形成了社会互动。其中的行为包括:
基础个体行为:
个体行为产生于内部认知过程和外部环境因素之间的相互作用。这些行为构成了个体在社会中运作和发展的基础。它们可分为三个核心维度:
- 输入行为指的是从周围环境中吸收信息。这包括感知感官刺激并将其存储为记忆。这些行为为个体理解外部世界奠定了基础。
- 内化行为涉及个体内部的认知处理。这类行为包括计划、推理、反思和知识沉淀等活动。这些内省过程对于成熟和自我完善至关重要。
- 输出行为是外显的行动和表达。这些行为可以是物体操作,也可以是结构构建。通过执行这些动作,Agent 可以改变周围环境的状态。此外,Agent 还可以表达自己的观点和广播信息,与他人互动。通过这种方式,Agent 可以与他人交流思想和信念,从而影响环境中的信息流。
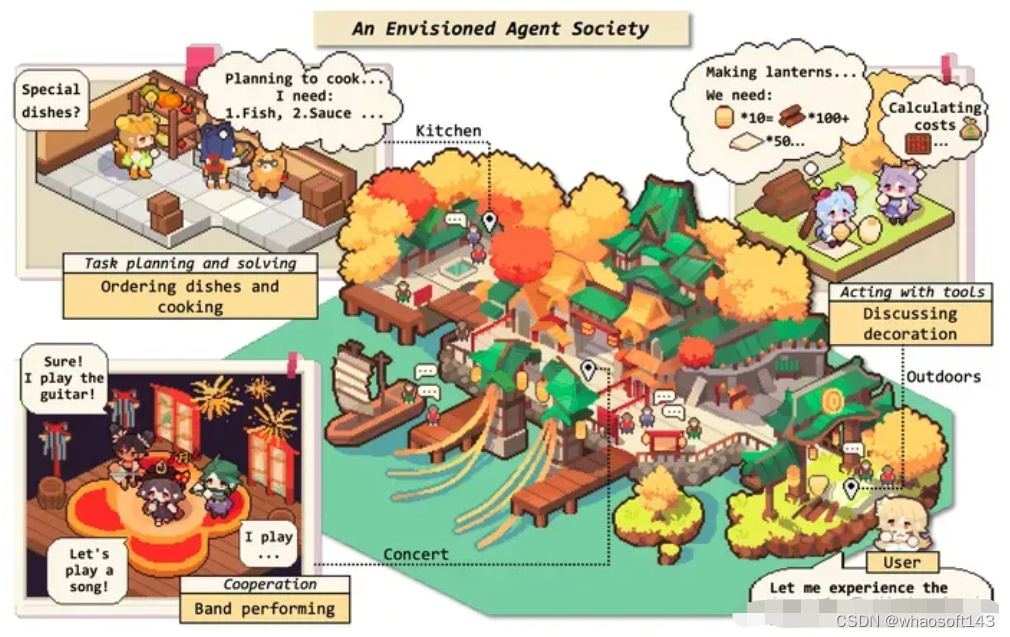
LLM-based Agents society
动态群体行为:
群体本质上是由两个或两个以上的个体组成的,他们在一个确定的社会环境中参与共同的活动。群体的属性从来都不是一成不变的,相反,它们会随着成员的互动和环境的影响而不断演变。这种灵活性产生了许多群体行为,每种行为都对更大的社会群体产生独特的影响。群体行为的类别包括:
- 积极的群体行为是促进团结、协作和集体福祉的行为。一个最好的例子就是团队合作,它可以通过头脑风暴讨论 、有效对话和项目管理来实现。Agent共享见解、资源和专业知识。这鼓励了和谐的团队合作,使Agent能够利用自己的独特技能完成共同目标。利他主义贡献也值得一提。一些LLM-based Agent充当志愿者,自愿提供支持,帮助其他群体成员,促进合作与互助。
- 中立的群体行为。在人类社会中,强烈的个人价值观千差万别,并趋向于个人主义和竞争性。相比之下,以“乐于助人、诚实和无害”为设计重点的 LLM 常常表现出中立的倾向。这种与中立价值观的一致会导致服从行为,包括模仿、旁观和不愿反对多数人。
- 消极的群体行为会破坏Agent群体的有效性和一致性。Agent之间的激烈辩论或争执所产生的冲突和分歧可能会导致内部关系紧张。此外,最近的研究表明,Agent可能会表现出对抗行为,甚至采取破坏行为,例如为了追求自己的效率或目标而破坏其他Agent或环境。
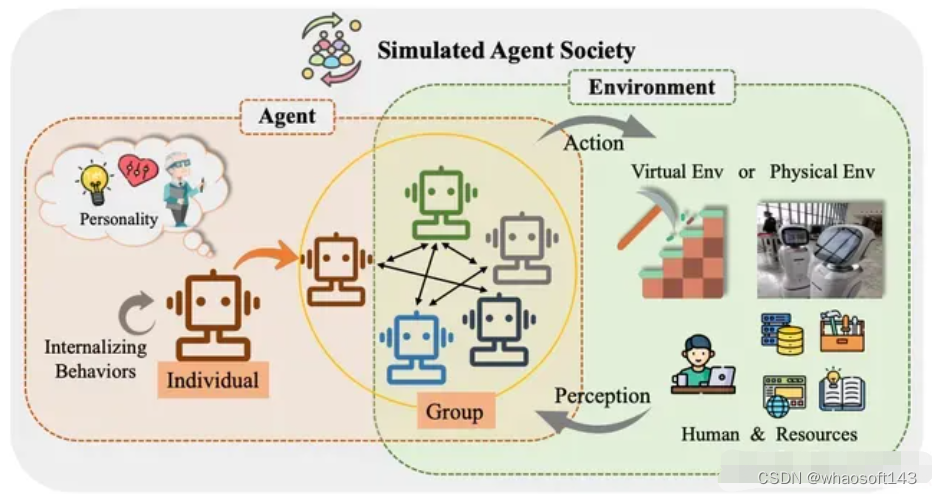
在人类社会的模拟的场景中,一个有意思的案例是 Humanoid Agents ,其赋予了 agent 三个要素——基本需求(饱腹感、健康和能量)、情感和关系亲密程度,来让 agent 表现得更像人类。利用这些元素,agent 就能调整自己的日常活动,以及和其他 agent 的对话,从而进行类社会化活动。整个系统的工作原理分为以下几步:
- 第1步:根据用户提供的种子信息初始化Agent。即对每个 Agent 进行人物设定,它们的名字、年龄、日程、喜好等,对其做出人物规划。
- 第2步:Agent开始计划自己的一天。
- 第3步:Agent根据自己的计划采取行动。如果同在一个地点,Agent可以相互交谈,进而影响他们之间的关系。
- 第4步:Agent评估所采取的行动是否改变了他们的基本需求和情绪。
- 第5步:根据基本需求和情感的满足情况,Agent可以更新未来的计划。
其中 Agent 的配置文件如下所示:
{"name": "fullness", "start_value": 5, "unsatisfied_adjective": "hungry", "action": "eating food", "decline_likelihood_per_time_step": 0.05, "help": "from 0 to 10, 0 is most hungry; increases or decreases by 1 at each time step based on activity"
}下面的视频展示了系统运行的过程,也可以通过 Demo 进行测试体验:
参考资料
[1] 多智能体强化学习入门 (boyuai.com)
[2] https://towardsdatascience.com/multi-agent-deep-reinforcement-learning-in-15-lines-of-code-using-pettingzoo-e0b963c0820b
[3] Cooperative Multiagent Attentional Communication for Large-Scale Task Space
[4] https://arxiv.org/pdf/2205.15023.pdf
[5] https://arxiv.org/pdf/1706.02275v4.pdf
[6] GitHub - zjunlp/LLMAgentPapers: Must-read Papers on LLM Agents.
[7] Interactive Language-Based Agents
[8] https://gafowler.medium.com/revolutionizing-ai-the-era-of-multi-agent-large-language-models-f70d497f3472
[9] MULTI-AGENT COLLABORATION: HARNESSING THE POWER OF INTELLIGENT LLM AGENTS
[10] Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View
[11] Multi-agent Conversation Framework | AutoGen
[12] https://github.com/Farama-Foundation/chatarena
[13] The Rise and Potential of Large Language Model Based Agents: A Survey
[14] Generative Agents: Interactive Simulacra of Human Behavior
[15] Humanoid Agents: Platform for Simulating Human-like Generative Agents
[16] Role play with large language models
# 微调Llama 3
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
大语言模型的微调一直是说起来容易做起来难的事儿。近日 Hugging Face 技术主管 Philipp Schmid 发表了一篇博客,详细讲解了如何利用 Hugging Face 上的库和 fsdp 以及 Q-Lora 对大模型进行微调。
我们知道,Meta 推出的 Llama 3、Mistral AI 推出的 Mistral 和 Mixtral 模型以及 AI21 实验室推出的 Jamba 等开源大语言模型已经成为 OpenAI 的竞争对手。
不过,大多数情况下,使用者需要根据自己的数据对这些开源模型进行微调,才能充分释放模型的潜力。
虽然在单个 GPU 上使用 Q-Lora 对较小的大语言模型(如 Mistral)进行微调不是难事,但对像 Llama 3 70b 或 Mixtral 这样的大模型的高效微调直到现在仍是一个难题。
因此,Hugging Face 技术主管 Philipp Schmid 介绍了如何使用 PyTorch FSDP 和 Q-Lora,并在 Hugging Face 的 TRL、Transformers、peft 和 datasets 等库的帮助下,对 Llama 3 进行微调。除了 FSDP,作者还对 PyTorch 2.2 更新后的 Flash Attention v2 也进行了适配。
微调主要步骤如下:
- 设置开发环境
- 创建并加载数据集
- 使用 PyTorch FSDP、Q-Lora 和 SDPA 微调大语言模型
- 测试模型并进行推理
注:本文进行的实验是在英伟达(NVIDIA)H100 和英伟达(NVIDIA)A10G GPU 上创建和验证的。配置文件和代码针对 4xA10G GPU 进行了优化,每个 GPU 均配备 24GB 内存。如果使用者有更多的算力,第 3 步提到的配置文件(yaml 文件)需要做相应的修改。
FSDP+Q-Lora 背景知识
基于一项由 Answer.AI、Q-Lora 创建者 Tim Dettmers 和 Hugging Face 共同参与的合作项目,作者对 Q-Lora 和 PyTorch FSDP(完全共享数据并行)所能提供的技术支持进行了总结。
FSDP 和 Q-Lora 的结合使用能让使用者在 2 个消费级 GPU(24GB)上就能对 Llama 2 70b 或 Mixtral 8x7B 进行微调,细节可以参考下面文章。其中 Hugging Face 的 PEFT 库对此有至关重要的作用。
文章地址:https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html
PyTorch FSDP 是一种数据 / 模型并行技术,它可以跨 GPU 分割模型,减少内存需求,并能够更有效地训练更大的模型。Q-LoRA 是一种微调方法,它利用量化和低秩适配器来有效地减少计算需求和内存占用。
设置开发环境
第一步是安装 Hugging Face Libraries 以及 Pyroch,包括 trl、transformers 和 datasets 等库。trl 是建立在 transformers 和 datasets 基础上的一个新库,能让对开源大语言模型进行微调、RLHF 和对齐变得更容易。
# Install Pytorch for FSDP and FA/SDPA%pip install "torch==2.2.2" tensorboard# Install Hugging Face libraries%pip install --upgrade "transformers==4.40.0" "datasets==2.18.0" "accelerate==0.29.3" "evaluate==0.4.1" "bitsandbytes==0.43.1" "huggingface_hub==0.22.2" "trl==0.8.6" "peft==0.10.0"接下来,登录 Hugging Face 获取 Llama 3 70b 模型。
创建和加载数据集
环境设置完成后,我们就可以开始创建和准备数据集了。微调用的数据集应该包含使用者想要解决的任务的示例样本。阅读《如何在 2024 年使用 Hugging Face 微调 LLM》可以进一步了解如何创建数据集。
文章地址:https://www.philschmid.de/fine-tune-llms-in-2024-with-trl#3-create-and-prepare-the-dataset
作者使用了 HuggingFaceH4/no_robots 数据集,这是一个包含 10,000 条指令和样本的高质量数据集,并且经过了高质量的数据标注。这些数据可用于有监督微调(SFT),使语言模型更好地遵循人类指令。no_robots 数据集以 OpenAI 发表的 InstructGPT 论文中描述的人类指令数据集为原型,并且主要由单句指令组成。
{"messages": [{"role": "system", "content": "You are..."}, {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}]}{"messages": [{"role": "system", "content": "You are..."}, {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}]}{"messages": [{"role": "system", "content": "You are..."}, {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}]}no_robots 数据集中的 10,000 个样本,被分为 9,500 个训练样本和 500 个测试样本,其中有些样本不包含 system 信息。作者使用 datasets 库加载数据集,添加了缺失的 system 信息,并将它们保存到单独的 json 文件中。示例代码如下所示:
from datasets import load_dataset# Convert dataset to OAI messagessystem_message = """You are Llama, an AI assistant created by Philipp to be helpful and honest. Your knowledge spans a wide range of topics, allowing you to engage in substantive conversations and provide analysis on complex subjects."""def create_conversation(sample):if sample["messages"][0]["role"] == "system":return sampleelse:sample["messages"] = [{"role": "system", "content": system_message}] + sample["messages"]return sample# Load dataset from the hubdataset = load_dataset("HuggingFaceH4/no_robots")# Add system message to each conversationcolumns_to_remove = list(dataset["train"].features)columns_to_remove.remove("messages")dataset = dataset.map(create_conversation, remove_columns=columns_to_remove,batched=False)# Filter out conversations which are corrupted with wrong turns, keep which have even number of turns after adding system messagedataset["train"] = dataset["train"].filter(lambda x: len(x["messages"][1:]) % 2 == 0)dataset["test"] = dataset["test"].filter(lambda x: len(x["messages"][1:]) % 2 == 0)# save datasets to diskdataset["train"].to_json("train_dataset.json", orient="records", force_ascii=False)dataset["test"].to_json("test_dataset.json", orient="records", force_ascii=False)使用 PyTorch FSDP、Q-Lora 和 SDPA 来微调 LLM
接下来使用 PyTorch FSDP、Q-Lora 和 SDPA 对大语言模型进行微调。作者是在分布式设备中运行模型,因此需要使用 torchrun 和 python 脚本启动训练。
作者编写了 run_fsdp_qlora.py 脚本,其作用是从磁盘加载数据集、初始化模型和分词器并开始模型训练。脚本使用 trl 库中的 SFTTrainer 来对模型进行微调。
SFTTrainer 能够让对开源大语言模型的有监督微调更加容易上手,具体来说有以下几点:
- 格式化的数据集,包括格式化的多轮会话和指令(已使用)
- 只对完整的内容进行训练,忽略只有 prompts 的情况(未使用)
- 打包数据集,提高训练效率(已使用)
- 支持参数高效微调技术,包括 Q-LoRA(已使用)
- 为会话级任务微调初始化模型和分词器(未使用,见下文)
注意:作者使用的是类似于 Anthropic/Vicuna 的聊天模板,设置了「用户」和「助手」角色。这样做是因为基础 Llama 3 中的特殊分词器(<|begin_of_text|> 及 <|reserved_special_token_XX|>)没有经过训练。
这意味着如果要在模板中使用这些分词器,还需要对它们进行训练,并更新嵌入层和 lm_head,对内存会产生额外的需求。如果使用者有更多的算力,可以修改 run_fsdp_qlora.py 脚本中的 LLAMA_3_CHAT_TEMPLATE 环境变量。
在配置参数方面,作者使用了新的 TrlParser 变量,它允许我们在 yaml 文件中提供超参数,或者通过明确地将参数传递给 CLI 来覆盖配置文件中的参数,例如 —num_epochs 10。以下是在 4x A10G GPU 或 4x24GB GPU 上微调 Llama 3 70B 的配置文件。
%%writefile llama_3_70b_fsdp_qlora.yaml
# script parametersmodel_id: "meta-llama/Meta-Llama-3-70b" # Hugging Face model iddataset_path: "." # path to datasetmax_seq_len: 3072 # 2048 # max sequence length for model and packing of the dataset# training parametersoutput_dir: "./llama-3-70b-hf-no-robot" # Temporary output directory for model checkpointsreport_to: "tensorboard" # report metrics to tensorboardlearning_rate: 0.0002 # learning rate 2e-4lr_scheduler_type: "constant" # learning rate schedulernum_train_epochs: 3 # number of training epochsper_device_train_batch_size: 1 # batch size per device during trainingper_device_eval_batch_size: 1 # batch size for evaluationgradient_accumulation_steps: 2 # number of steps before performing a backward/update passoptim: adamw_torch # use torch adamw optimizerlogging_steps: 10 # log every 10 stepssave_strategy: epoch # save checkpoint every epochevaluation_strategy: epoch # evaluate every epochmax_grad_norm: 0.3 # max gradient normwarmup_ratio: 0.03 # warmup ratiobf16: true # use bfloat16 precisiontf32: true # use tf32 precisiongradient_checkpointing: true # use gradient checkpointing to save memory# FSDP parameters: https://huggingface.co/docs/transformers/main/en/fsdpfsdp: "full_shard auto_wrap offload" # remove offload if enough GPU memoryfsdp_config:backward_prefetch: "backward_pre"forward_prefetch: "false"use_orig_params: "false"注意:训练结束时,GPU 内存使用量会略有增加(约 10%),这是因为模型保存所带来的开销。所以使用时,请确保 GPU 上有足够的内存来保存模型。
在启动模型训练阶段,作者使用 torchrun 来更加灵活地运用样本,并且易于被调整,就像 Amazon SageMaker 及 Google Cloud Vertex AI 一样。
对于 torchrun 和 FSDP,作者需要对环境变量 ACCELERATE_USE_FSDP 和 FSDP_CPU_RAM_EFFICIENT_LOADING 进行设置,来告诉 transformers/accelerate 使用 FSDP 并以节省内存的方式加载模型。
注意:如果想不使用 CPU offloading 功能,需要更改 fsdp 的设置。这种操作只适用于内存大于 40GB 的 GPU。
本文使用以下命令启动训练:
!ACCELERATE_USE_FSDP=1 FSDP_CPU_RAM_EFFICIENT_LOADING=1 torchrun --nproc_per_node=4 ./scripts/run_fsdp_qlora.py --config llama_3_70b_fsdp_qlora.yaml预期内存使用情况:
- 使用 FSDP 进行全微调需要约 16 块 80GB 内存的 GPU
- FSDP+LoRA 需要约 8 块 80GB 内存的 GPU
- FSDP+Q-Lora 需要约 2 块 40GB 内存的 GPU
- FSDP+Q-Lora+CPU offloading 技术需要 4 块 24GB 内存的 GPU,以及一块具备 22 GB 内存的 GPU 和 127 GB 的 CPU RAM,序列长度为 3072、batch 大小为 1。
在 g5.12xlarge 服务器上,基于包含 1 万个样本的数据集,作者使用 Flash Attention 对 Llama 3 70B 进行 3 个 epoch 的训练,总共需要 45 小时。每小时成本为 5.67 美元,总成本为 255.15 美元。这听起来很贵,但可以让你在较小的 GPU 资源上对 Llama 3 70B 进行微调。
如果我们将训练扩展到 4x H100 GPU,训练时间将缩短至大约 125 小时。如果假设 1 台 H100 的成本为 5-10 美元 / 小时,那么总成本将在 25-50 美元之间。
我们需要在易用性和性能之间做出权衡。如果能获得更多更好的计算资源,就能减少训练时间和成本,但即使只有少量资源,也能对 Llama 3 70B 进行微调。对于 4x A10G GPU 而言,需要将模型加载到 CPU 上,这就降低了总体 flops,因此成本和性能会有所不同。
注意:在作者进行的评估和测试过程中,他注意到大约 40 个最大步长(将 80 个样本堆叠为长度为三千的序列)就足以获得初步结果。40 个步长的训练时间约为 1 小时,成本约合 5 美元。
可选步骤:将 LoRA 的适配器融入原始模型
使用 QLoRA 时,作者只训练适配器而不对整个模型做出修改。这意味着在训练过程中保存模型时,只保存适配器权重,而不保存完整模型。
如果使用者想保存完整的模型,使其更容易与文本生成推理器一起使用,则可以使用 merge_and_unload 方法将适配器权重合并到模型权重中,然后使用 save_pretrained 方法保存模型。这将保存一个默认模型,可用于推理。
注意:CPU 内存需要大于 192GB。
#### COMMENT IN TO MERGE PEFT AND BASE MODEL ##### from peft import AutoPeftModelForCausalLM# # Load PEFT model on CPU# model = AutoPeftModelForCausalLM.from_pretrained(# args.output_dir,# torch_dtype=torch.float16,# low_cpu_mem_usage=True,# )# # Merge LoRA and base model and save# merged_model = model.merge_and_unload()# merged_model.save_pretrained(args.output_dir,safe_serialization=True, max_shard_size="2GB")模型测试和推理
训练完成后,我们要对模型进行评估和测试。作者从原始数据集中加载不同的样本,并手动评估模型。评估生成式人工智能模型并非易事,因为一个输入可能有多个正确的输出。阅读《评估 LLMs 和 RAG,一个使用 Langchain 和 Hugging Face 的实用案例》可以了解到关于评估生成模型的相关内容。
文章地址:https://www.philschmid.de/evaluate-llm
import torch
from peft import AutoPeftModelForCausalLM
from transformers import AutoTokenizerpeft_model_id = "./llama-3-70b-hf-no-robot"# Load Model with PEFT adaptermodel = AutoPeftModelForCausalLM.from_pretrained(peft_model_id,torch_dtype=torch.float16,quantization_config= {"load_in_4bit": True},device_map="auto")tokenizer = AutoTokenizer.from_pretrained(peft_model_id)接下来加载测试数据集,尝试生成指令。
from datasets import load_dataset
from random import randint# Load our test dataseteval_dataset = load_dataset("json", data_files="test_dataset.json", split="train")rand_idx = randint(0, len(eval_dataset))messages = eval_dataset[rand_idx]["messages"][:2]# Test on sampleinput_ids = tokenizer.apply_chat_template(messages,add_generation_prompt=True,return_tensors="pt").to(model.device)outputs = model.generate(input_ids,max_new_tokens=512,eos_token_id= tokenizer.eos_token_id,do_sample=True,temperature=0.6,top_p=0.9,)response = outputs[0][input_ids.shape[-1]:]print(f"**Query:**\n{eval_dataset[rand_idx]['messages'][1]['content']}\n")print(f"**Original Answer:**\n{eval_dataset[rand_idx]['messages'][2]['content']}\n")print(f"**Generated Answer:**\n{tokenizer.decode(response,skip_special_tokens=True)}")# **Query:**# How long was the Revolutionary War?# **Original Answer:**# The American Revolutionary War lasted just over seven years. The war started on April 19, 1775, and ended on September 3, 1783.# **Generated Answer:**# The Revolutionary War, also known as the American Revolution, was an 18th-century war fought between the Kingdom of Great Britain and the Thirteen Colonies. The war lasted from 1775 to 1783.至此,主要流程就介绍完了,心动不如行动,赶紧从第一步开始操作吧。
原文链接:https://www.philschmid.de/fsdp-qlora-llama3?continueFlag=7e3b3f9059405e4318552e99bd128514