一、在Ubuntu系统下安装MySQL数据库
1、更新软件源,在确保ubuntu系统能正常上网的情况下执行以下命令
sudo apt-get update
2、安装MySQL数据库及相关软件包
# 安装过程中设置root用户的密码 123456 sudo apt-get install mysql-server # 安装访问数据库的客户端 sudo apt-get install mysql-client # 安装访问数据库的代码库 sudo apt-get install libmysqlclient-dev
4、配置数据库的字符集、开启网络连接
1、打开MySQL数据库的配置文件 sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf 2、开启mysql的网络连接,注释掉以下配置: # bind-address = 127.0.0.1 3、在文件38行后面添加以下配置: lc-messages-dir = /usr/share/mysql character_set_server=utf8 skip-external-locking 4、保存退出,并重启数据库 sudo service mysql restart
5、创建数据库、创建新用户
1、在终端登录MySQL的root用户 mysql -uroot -p123456 2、进入MySQL的root用户,创建数据库 mysql> create database testDB; 3、创建test用户,设置访问权限,设置用户密码为123456 mysql> grant all privileges on testDB.* to 'test'@'%' identified by '123456'; 4、刷新保存设置 mysql> flush privileges; 5、退出登录 mysql> exit
6、测试MySQL数据库
1、在终端登录MySQL的test新用户 mysql -utest -p123456 2、选择要使用的数据库 mysql> use testDB; 3、创建一张Student数据表 mysql> create table Student(name char(20),sex char,age int,addr varchar(100)); 4、向Student数据表中插入一条数据 mysql> insert into Student values("hehe",'w',18,"杭州指针信息技术有限公司"); 5、查询Student数据表中的所有数据 mysql> select * from Student;
二、数据库介绍
1、为什么需要数据库
1、计算机的资源有限,不可能把数据全部存储在内存中,且内存掉电后数据会丢失,为了能让程序在关机重启后继续使用,必须把数据保存到磁盘的文件中。
2、随着程序的功能越来越复杂、数据量越来越大,从文件中读写数据需要大量的重复性操作,从文件中读取出指定的数据需要复杂的逻辑。
3、不同的程序它的访问文件的操作不同,就意味着读写文件的代码无法复用。
4、所以程序员非常需要一个统一的快速的访问磁盘数据的工具。
5、使用数据库程序员不需要自己管理数据,而是通过数据库提供的接口进行读写操作,至于数据在文件中是如何保存、查找与程序员无关。
2、什么是数据库
数据库指的管理数据的软件(DBMS),而不是存储数据的仓库。
3、数据库的类型
关系型:
关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。用户通过查询来检索数据库中的数据,而查询是一个用于限定数据库中某些区域的执行代码。关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
非关系型(redis):
非关系型数据库严格上不止一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
NoSQL,泛指非关系型的数据库,NoSQL最常见的解释是“non-relational”, “Not Only SQL”也被很多人接受。NoSQL仅仅是一个概念,泛指非关系型的数据库,区别于关系数据库。
NoSQL是一项全新的数据库革命性运动,其拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
4、目前主流关系型数据库:
商用数据库:OceanBase,Oracle,SQL Server,DB2,GaussDB
开源数据库:MySQL,MariaDB
桌面数据库:Access
嵌入式数据库:SQLite
三、SQL语言介绍
1、什么是SQL
SQL是结构化查询语言的缩写,是数据库的标准委员会,用来访问和操作数据库的统一语言,所有的数据库都支持SQL语言,也就是我们只需要学习SQL语言就可以操作所有的关系型数据库。
虽然ANSI组织定义了统一的SQL语言标准,但不同的数据库厂商对SQL的支持程度不同,有的还添加了新的语法,如果只使用标准的SQL语句理论上可以操作所有的数据库,然后把每种数据库特有的SQL语法称为SQL的方言。
SQL语句不区分大小写,但标识符(表名、字段名)是区别的。
2、SQL语句有功能分类
数据控制语句:用于权限的赋予和回收。
数据定义语句:用于建立、修改、删除数据库对象(表、视图等)。
数据操作语句:用于改变表中的数据(增、删、改)。
数据查询语句:根据不同的条件来查询数据。
事务控制语句:用于维护数据库的一致性。
3、SQL语句中的数据类型
MySQL 支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型:
1、MySQL 支持所有标准 SQL 数值数据类型。
2、这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL 和 NUMERIC),以及近似数值数据类型(FLOAT、REAL 和 DOUBLE PRECISION)。
3、关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
4、BIT数据类型保存位字段值,并且支持 MyISAM、MEMORY、InnoDB 和 BDB表。
5、作为 SQL 标准的扩展,MySQL 也支持整数类型 TINYINT、MEDIUMINT 和 BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
| 类型 | byte | 范围(有符号) | 无符号最大值 |
|---|---|---|---|
| TINYINT | 1 | -128,127 | 255 |
| SMALLINT | 2 | -32768,32767 | 65535 |
| MEDIUMINT | 3 | -8388608,8388607 | 16777215 |
| INT | 4 | -2147483648,2147483647 | 4294967295 |
| BIGINT | 8 | -9,223372036854775808,9223372036854775807 | 18446744073709551615 |
| FLOAT | 4 | (-3.402823466E+38,-1.175494351E-38) (1.175494351E-38,3.402823466351E+38) | 1.175494 351E-38,3.402 823 466 E+38 |
| DOUBLE | 8 | (-1.7976931348623157E+308,-2.225073858507 2014E-308) (2.2250738585072014 E-308,1.797 6931348623157 E+308) | 2.225073 858507201 4 E-308,1.797693134 862 3157E+308 |
日期和时间类型:
1、表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
2、每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
3、TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 | byte | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | '1000-01-01 00:00:00' 到 '9999-12-31 23:59:59' | YYYY-MM-DD hh:mm:ss | 混合日期和时间值 |
| TIMESTAMP | 4 | '1970-01-01 00:00:01' UTC 到 '2038-01-19 03:14:07' | YYYY-MM-DD hh:mm:ss | 混合日期和时间值,时间戳 |
字符串类型:
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | byte | 用途 |
|---|---|---|
| CHAR | 0-255 | 定长字符串 |
| VARCHAR | 0-65535 | 变长字符串 |
| TINYBLOB | 0-255 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 | 短文本字符串 |
| BLOB | 0-65535 | 二进制形式的长文本数据 |
| TEXT | 0-65535 | 长文本数据 |
| MEDIUMTEXT | 0-16777215 | 中等长度文本数据 |
| MEDIUMBLOB | 0-1677215 | 二进制形式的中等长度文本数据 |
| LONGBLOB | 0-4294967295 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4294967295 | 极大文本数据 |
注意:
1、char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
2、CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
3、BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
4、BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
5、有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
tinyint smallint int bigint float double date timestamp char varchar
三、MySQL数据库的访问方式
1、本地访问
# 方便但有泄露密码的风险 mysql -u用户名 -p密码 # 建议这样登录 mysql -u用户名 -p
2、远程访问
1、先使用 ssh 或 telnet 远程登录MySQL服务器ssh 用户名@ip 输入密码 2、mysql -u用户名 -p
3、图形客户端登录
sudo apt install mysql-workbench
1、创建连接
2、填写连接参数
四、数据定义语句
1、创建表
create table 表名(字段名 字段类型,...); -- 创建一个聊天室的用户表 create table chat_user(user_name char(20),passwd char(8),email char(32) ); -- 查看表结构 desc 表名; 注意:如何把结构转换成数据表
2、修改表
-- 修改表名 rename table 旧表名 to 新表名; rename table User to chat_user; -- 增加列,如果表已有数据,新添加的字段具有非空的要求,则添加失败 alter table 表名 add(字段名 字段类型); -- 删除列,如果表中已有数据,则该字段的数据会一起删除 alter table 表名 drop 字段名; -- 修改列,如果表中已有数据,新的字段如果能兼容之前的数据则修改成功,否则修改失败 alter table 表名 modify 字段名 新类型; alter table 表名 change 旧字段名 新字段名 新类型; 总结:1、把表结构设计完善后,再添加数据。2、尽量不要修改旧表的结构,而设计一张新的表,让他们建立联系。
3、删除表
-- 删除表数据,保留表结构,清空表 truncate 表名; truncate Student; -- 删除表,数据和结构都删除 drop table 表名; drop table Student;
五、数据操作语言
1、插入数据
-- 按全字段顺序插入 insert into 表名 values(数据); -- 指定字段插入 insert into 表名(字段名,...) values(数据,...); 注意:在设计表时,某些字段为设置一些约束条件,如果插入的数据不满足这些条件(非空、唯一),则插入失败。
2、删除数据
delete from 表名 where 条件; delete from chat_user; delete from chat_user where nick="二师兄"; delete from chat_user where level < 2; -- 注意,如果不写where,则整张表全部删除,所以为了安全MySQL数据库默认不支持该操作 -- 查看当前连接是否开启数据保护 show variables like 'sql_safe%'; -- 开启安全保护,禁止使用非主键字段作为删除条件 set sql_safe_updates=on; -- 关闭数据安全保护,任何条件都可以作为删除条件 set sql_safe_updates=off;
3、修改数据
-- 注意:如果不写where,则整张表的字段数据全被修改。 update 表名 set 字段=数据,... where 条件;
六、数据查询语句
select 字段1,字段2,... from 表名; -- *在SQL中也是通配符,代表所有字段 select * from chat_user; select nick,level from chat_user;
七、事务控制语句
1、commit 提交
一个数据库会被若干个客户端同时访问,数据库的底层为了保护数据的完整性,修改数据时会加锁保护。
理论上每个客户端修改一次数据,都要加一次锁,但频繁的加锁会降低数据库的运行速度,所以数据设计一种确认修改的动作。
客户端对数据库进行若干次修改了,数据库不会立即修改硬盘上的数据,而是把修改过的数据暂存客户端,直接客户端执行了确认修改的命令,此时数据库才会加锁,然后把修改后的数据更新到硬盘上。
在数据库,一个用户插入一条数据时,只有它自己能查询到,其它用户并不能立即看到,只有执行了commit语句后,其它用户才能看到。
2、rollback
当用户对数据进行修改后,如果发现操作错误,可以使用rollback语句返回到上一次commit;
使用commit的优点:
2、降低硬盘的读写次数,提高硬盘的寿命。
3、MySQL中的自动提交
-- 查询当前登录的自动提交是否开启 show variables like 'autocommit'; set session autocommit = 0|1; 关闭或开启当前登录的自动提交。 set global autocommit = 0|1; 关闭或开启所有登录的自动提交,需要root用户才能执行。
4、设置保存点
使用rollback取消操作时,会取消所有的操作,直接回到上次commit的时刻,但这样可以会浪费一部分有意义的操作,可以在一个的阶段设置在保存点,让rollback返回到指定的位置。
insert into chat_user values("二师兄","123123",13388666688,1);
savepoint s1;
insert into chat_user values("二师兄","123123",13388666687,2);
savepoint s2;
insert into chat_user values("二师兄","123123",13388666686,3);
savepoint s3;
insert into chat_user values("二师兄","123123",13388666685,4);
savepoint s4;
insert into chat_user values("二师兄","123123",13388666684,5);
select * from chat_user;
rollback to savepoint s3;
select * from chat_user;
八、使用C连接并操作数据库
所有MySQL数据库的C语言接口就声明在mysql/mysql.h头文件中,但前提是安装libmysqlclient-dev库。
1、初始化MYSQL对象
MYSQL *mysql_init(MYSQL *mysql) 功能:分配或初始化与mysql_real_connect()相适应的MYSQL对象。 mysql:1、参数是NULL指针,该函数将分配、初始化、并返回新对象2、参数是MYSQL对象地址,将初始化对象,并返回对象的地址。 返回值:成功:初始化的MYSQL*句柄。如果无足够内存以分配新的对象,返回NULL。错误:在内存不足的情况下,返回NULL。 注意:如果mysql_init分配了新的对象,当调用mysql_close来关闭连接时,将释放该对象。
2、连接数据库
MYSQL *mysql_real_connect(MYSQL *mysql, const char *host, const char *user, const char *passwd, const char *db, unsigned int port, const char *unix_socket, unsigned long client_flag); mysql:已有MYSQL结构的地址调用mysql_real_connect()之前,必须调用mysql_init()来初始化MYSQL结构。 host:主机名或IP地址。如果“host”是NULL或字符串"localhost",连接将被视为与本地主机的连接。如果操作系统支持套接字(Unix)或命名管道(Windows),将使用它们而不是TCP/IP连接到服务器。 user:用户名 passwd:用户的密码 db:是数据库名称 port:如果不是0,其值将用作TCP/IP连接的端口号,host参数决定了连接的类型。 unix_socket:该字符串描述了应使用的套接字或命名管道,注意,“host”参数决定了连接的类型。 client_flag:值通常为0,但是,也能将其设置为下述标志的组合。 返回值:如果连接成功,返回MYSQL*连接句柄,与第1个参数的值相同。如果连接失败,返回NULL。
2、设置字符集、获得当前连接的字符集
int mysql_set_character_set(MYSQL *mysql, char *csname); 如果查询成功,返回0。如果出现错误,返回非0值。 const char *mysql_character_set_name(MYSQL *mysql);
3、发送SQL指令
int mysql_real_query(MYSQL *mysql, const char *query, unsigned long length) 如果查询成功,返回0。如果出现错误,返回非0值。
4、获取查询结果
MYSQL_RES *mysql_store_result(MYSQL *mysql) 功能:将查询的全部结果读取到客户端,分配1个MYSQL_RES结构,并将结果置于该结构中。 返回值结果为NULL:语句执行出现错误,或执行的是没有结果的SQL语句,如INSERT语句。通过检查mysql_error()是否返回非空字符串,mysql_errno()是否返回非0值,或mysql_field_count()是否返回0,可以检查是否出现了错误。 返回值结果不为NULL则需要调用以下函数: my_ulonglong mysql_num_rows(MYSQL_RES *result) 功能:返回结果集中的行数。unsigned int mysql_num_fields(MYSQL_RES *result) 功能:返回结果集中的列数MYSQL_ROW mysql_fetch_row(MYSQL_RES *result) 功能:从结果集中读取一行数据void mysql_free_result(MYSQL_RES *result) 功能:释放结果集
5、受影响或检索的记录行数
unsigned long long mysql_affected_rows(MYSQL *mysql); 功能:返回上次UPDATE更改的行数,上次DELETE删除的行数,或上次INSERT语句插入的行数。对于UPDATE、DELETE或INSERT语句,可在mysql_query()后立刻调用。对于SELECT语句,mysql_affected_rows()的工作方式与mysql_num_rows()类似。 返回值:大于0的整数表明受影响或检索的行数。0表示UPDATE语句未更新记录,在查询中没有与WHERE匹配的行,或未执行查询。-1表示查询返回错误,或者,对于SELECT查询,在调用mysql_store_result()之前调用了mysql_affected_rows。由于mysql_affected_rows返回无符号值,通过比较返回值和(my_ulonglong)-1或等效的(my_ulonglong)~0,检查是否为“-1”。
6、commit提交
my_bool mysql_autocommit(MYSQL *mysql, my_bool mode) mode:为真,启用autocommit模式,为假,禁止autocommit模式。 返回值:如果成功,返回0,如果出现错误,返回非0值。 my_bool mysql_commit(MYSQL *mysql) 功能:提交当前事务。 返回值:如果成功,返回0,如果出现错误,返回非0值。
7、错误编号、原因
unsigned int mysql_errno(MYSQL *mysql) 功能:获取错误编号,如果没有错误则返回0const char *mysql_error(MYSQL *mysql) 功能:获取错误原因,如果没有错误则返回NULL
8、编译时需要添加参数
# 用的库是libmysqlclient-dev,所以编译时需要添加参数 gcc xxx.c -lmysqlclient
任务1:使用以上API实现一个mysql命令。
任务2:使用数据库实现通讯录项目。
增、删、改、查、列出,直接针对数据库进行操作。
九、高级查询
1、排重 distinct
-- 在数据表中,一个字段的值可能有多个重复的,distinct 可以排除重复数据,如果多个字段查询,那么所有查询的字段值都一样,才算重复 select distinct 字段,... from 表名; select distinct nick from chat_user;
2、算术运算符
-- select 语句查询时,可以对表中的数值字段直接进行算术运算,如果想改变运算的优先级可以使用小括号。 select 字段 + - * / % from 表名; select level/3 from chat_user;
3、where子句
-- 在where字句中可以使用关系运算符和逻辑运算符,只有条件为真的数据才会显示 select 字段 from 表名 where 条件; 关系运算符:> < >= <= = != 逻辑运算符:and or not&& || ! 可以继续使用特殊条件:between a and b <=> 判断一个范围,使用判断运算符加逻辑运算符也能达到同样的效果[a,b]。is null、is not null 判断字段值是不是为空,在数据表中空值是一种状态,而不是一个特定的值。select * from chat_user where phone is null;in (a,b,c,...) 当字段的值出现在in的范围列表中,则为真。select * from chat_user where level in (1,3,5,7,9);like "%str_" 模糊查询(Linux系统命令行中使用的通配符),字符型字段使用才合适select * from chat_user where phone like "183%";% 匹配任意多个字符_ 匹配一个字符
注意:判断字段值是不为空,在数据表中空值是一种状态,而不是一个特定的值。
4、排序
select 字段 from 表名 order by 字段 [asc|desc];asc 升序,从小到大,默认desc 降低,从大到小 select * from chat_user order by phone; -- 注意:MySQL数据库在排序时把空值当作最小值,Oracle数据库把空值当作了最大值。 -- 排序与where子句配合: select 字段 from 表名 where 条件 order by 字段 [asc|desc]; select * from chat_user where phone is not null order by phone desc;
5、分页查询
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不如分页显示,每次显示100条。
要实现分页功能,实际上就是从结果集中显示第1~100条记录作为第1页,显示第101~200条记录作为第2页,以此类推。因此,分页实际上就是从结果集中“截取”出第M~N条记录。
select 字段 from 表名 limit <一页的记录数> offset <要跳过的记录数>; select * from chat_user limit 10 offset 0; 假设一页m条数据 select * from chat_user limit m offset (页数-1)*m;
6、连接查询(多表查询)
当需要的数据分布在不同的表中,就需要多张表连接查询,无条件的连接会产生"笛卡乐积"有海量的无效数据,需要配合where子句进行连接。
-- 班级表 create table class(class_id int,class_name char(20),teacher_id int,room_id int ); -- 教师表 create table teacher(work_id int,name char(20),sex char(1),phone char(11) ); -- 学生表 create table student(id int,name char(20), sex char(1),class_id int );
select 字段 from 表1,表2 where 表1.key = 表2.key; -- 表中的字段可能会重名,需要 表名.字段进行区分; select 表名.字段 from 表1,表2 where 表1.key = 表2.key;
根据where条件和连接结果,连接查询分为以下几种:
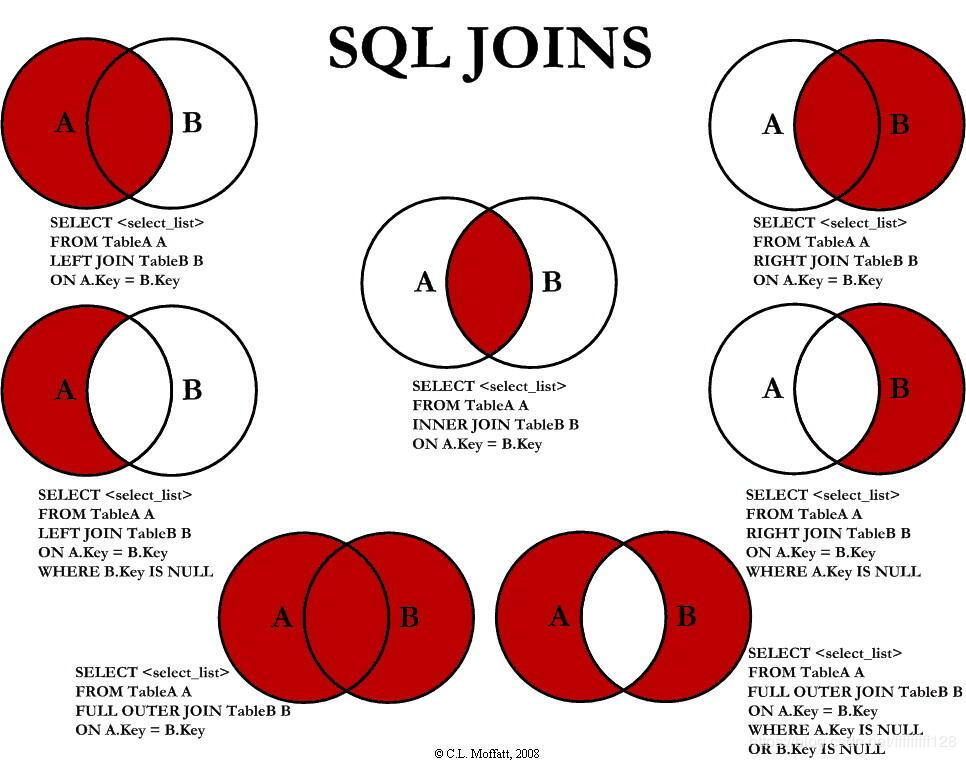
-- 内连接 查询出每班级的教师叫什么名字? select class_name,name from class,teacher where work_id = teacher_id; -- 左内连接 查询出每班级的教师叫什么名字,没有分配教师的班级也显示? select class_name,name from class left join teacher on work_id = teacher_id; -- 右内连接 查询出每班级的教师叫什么名字,没有教学任务的教师也显示? select class_name,name from class right join teacher on work_id = teacher_id; -- 左外连接 查询出没有分配教师的班级? select class_name,name from class left join teacher on work_id = teacher_id where teacher_id is null; -- 右外连接 查询出没有分配教学任务的教师? select class_name,name from class right join teacher on work_id = teacher_id where class_name is null; -- 全连接 select class_name,name from class full outer join teacher on work_id = teacher_id; select class_name,name from class left join teacher on work_id = teacher_id union select class_name,name from class right join teacher on work_id = teacher_id where class_name is null; -- 外连接 select class_name,name from class left join teacher on work_id = teacher_id where teacher_id is null union select class_name,name from class right join teacher on work_id = teacher_id where class_name is null; 全连接、外连接MySQL不支持该语法,可以使用union关键字,把左外连接、右外连接联合在一起实现外连接、全连接。左外连接 union 右外连接 = 外连接;左连接 union 右连接 = 全连接;
7、取别名
在多表查询时,由于表名,在访问重名字段时语句过长,可以给表名取一个简单的别名,也可以解决一张表自连接的查询。
select 别名.字段 from 表名 as 别名; 问题:查询出每个学生的上课时的教室。 select name,room_id from class as c,student as s where c.class_id = s.class_id; select name,room_id from class as c,student as s where class.class_id = student.class_id;
8、子查询
把一个查询结果作为另一个查询语句的基础,这种查询叫子查询或嵌套查询。
-- 在SQL中可以把select的查询结果当作一张内存表。 查询出没有分配教学任务的教师,并显示它的ID? select work_id from class right join teacher on teacher_id = work_id where teacher_id is null; 查询出未分配教学任务的教师姓名、性别、手机号? select name,sex,phone from teacher where work_id in (select work_id from class right join teacher on teacher_id = work_id where teacher_id is null);
9、MySQL中的函数
-- 普通函数一条记录就会产生一个结果,而组函数一次查询只产生一个结果,这两种函数不能混用 count 计数 max 求最大 min 求最小 sum 求和 avg 求平均
MySQL 函数 | 菜鸟教程
注意:MySQL中有丰富的数据处理函数,但程序员也可以先把查询到的结果转换成相关的数据类型,再使用编程语言中的数据处理函数。
10、分组查询
把表中的数据按照标准分为不同的组。
select 分组标准或组函数处理过的数据 from 表 group by 字段; 查询出每个班级的学生数量? select class_id,count(id),max(id),min(id) from student group by class_id; 查询出每个班级的班级名,授课教师名,学生数量? select class_name,teacher.name,count(id) from class,teacher,student where work_id=teacher_id && student.class_id=class.class_id group by class_name,teacher.name; 查询出每个班级的班级ID、班级名,授课教师名,学生数量? select class.class_id,min(class_name),min(teacher.name),count(student.id) from class,teacher,student where work_id=teacher_id && student.class_id=class.class_id group by class.class_id; select class_name,teacher.name,count(id) from class left join teacher on work_id = teacher_id left join student on student.class_id=class.class_id group by class_name,teacher.name;
过虑分组后的数据:
select 分组标准或组函数处理过的数据 from 表 group by 字段 having 条件; 注意:having的条件字段必须分组标准或组函数处理过的字段。 查询出每个1004班级的班级名,授课教师名,学生数量? select class.class_id,class_name,teacher.name,count(id) from class left join teacher on work_id = teacher_id left join student on student.class_id=class.class_id group by class_name,teacher.name,class.class_id having class.class_id = 1004;
复杂语句的执行顺序:
select 组函数(字段)|或分组标准from 表名where 条件 | 连接标准group by 分组标准having 过虑条件order by 排序标准; 查询出班级人数在3人以上的班级,显示班级名,班级ID,班级人数,并且对按班级人数进行排序。 select student.class_id,max(class_name),count(name) from student,class where student.class_id=class.class_idgroup by student.class_idhaving count(name) > 3order by count(name);
注意:在MySQL客户端里,使用Ctrl+B 可以格式化SQL语句。
十、设计表
1、数据库设计的三 大范式
在进行数据库设计时,制定的一些规则,称为数据库设计范式 ,遵守这些规则将创建出良好的数据库,如经常听到的数据库三大范式。
第一范式(Normal From,1NF):确保每列的原子性
如果每列都是不可再分的最小数据单元,则满足第一范式。
例如:顾客表(姓名、编号、地址、……),其中"地址"列还可以细分为国家、省、市、区等,所以按照第一次范围,地址更改为地区编号(例如身份证号的前6位)。
第二范式(Normal From,2NF):在第一范式的基础上更进一层,目标是确保表中的每列都和主键相关
如果一个关系满足第一范式,并且除了主键以外的其它列,都依赖于该主键,则满足第二范式.
例如:订单表(订单编号、产品编号、产品数量、定购日期、产品价格、……),"订单编号"为主键,"产品价格"和主键列没有直接的关系,即"产品价格"列不依赖于主键列,应删除,然后连接产品表,根据产品编号获得该项数据。
第三范式(Normal From,3NF):在第二范式的基础上更进一层,目标是确保每列都和主键列直接相关,而不是间接相关
如果一个关系满足第二范式,并且除了主键以外的其他列都只能依赖主键列,列与列之间不存在相互依赖关系,则满足第三范式。
例如:订单表(订单编号,定购日期,顾客编号,顾客姓名,……),初看该表没有问题,满足第二范式,每列都和主键列"订单编号"相关,再细看你会发现"顾客姓名"和"顾客编号"相关,为了满足第三范式,应去掉"顾客姓名"列,放入客户表中。
总结:字段不可再分,字段跟主键都有关系,字段与主键有强直接关系,遵循这三范式能让数据库中的表更灵活、强大、节约存储空间,但并不能保证查询速度最快,所以在实际开发过程中会突破三范式,牺牲存储空间以达到速度最优。
2、约束
约束是对数据和表的限制,可以提高表中数据的准确性和可靠性,一般在创建表、修改表时使用(在已有数据的情况下,修改表的约束不一定能成功)。
约束的分类:
not null 非空,字段的数据不能为空 unique 唯一,字段的数据不能重复 primary key 主键(非空且唯一) foreign key 外键依赖,B表某个字段值必须在A表中的某个字段出现过 default 默认值,给字段设置完默认值后,当插入数据不提供该字段的数据值,数据库自动填充默认值 check 检查,设置一个条件判断,当数据不满足条件时插入失败,但MySQL数据库不支持 drop table teacher; create table teacher(work_id int primary key,name char(20) not null,sex char NULL default 'w',enter_time timestamp NULL default CURRENT_TIMESTAMP ); drop table class; create table class(class_id int primary key,class_name char(20) not null,enter_time timestamp NULL default CURRENT_TIMESTAMPteacher_id int,room_id int unique not null ); -- 一般在创建表的时候设置外键,先建父表,再建子表: create table 父表(字段名 类型 primary key, ); create table 子表(...foreign key(字段) REFERENCES 父表(字段) ); drop table student;
约束的设置方式:
-- 创建表时设置: create table 表名(字段名 类型 约束, ); -- 修改表时设置: alter table 表名 modify 字段 类型 约束;
外键约束:
一张表(子表)的值引用自另一张表(父表),被引用的字段必须具备唯一性,子表中的外键字段的值必须来自父表或者是null值。
-- 一般在创建表的时候设置外键,先建父表,再建子表: create table 父表(字段名 类型 primary key, ); create table 子表(...foreign key(字段) REFERENCES 父表(字段) ); -- 也可以后期添加(一般不建议使用): alter table 子表 add foreign key(子表字段) REFERENCES 父表(父表字段); -- 班级表 父表 drop table class; create table class(class_id int primary key,name char(20) unique not null);-- 学生表 子表 drop table student; create table student(student_id int primary key,name char(20) unique not null,class_id int, foreign key(class_id) REFERENCES class(class_id))
插入数据:
先插入父表数据,再插入子表数据。
更新或删除数据:
默认情况下:
删除父表数据时:先删除子表数据,再删除父表数据。
更新父表数据时:父表插入新数据,修改子表数据,再删除父表中数据。
设置级联删除,级联更新:
on delete cascade 级联删除,删除父表时,子表中的数据会一起删除
on update cascade 级联更新,更新父表时,子表中的数据会一起删除
注意:级联删除、更新必须在创建子表时设置才有效。
create table student(student_id int primary key,name char(20) unique not null,class_id int, foreign key(class_id) REFERENCES class(class_id) on delete cascade on update cascade );
3、自动增长的字段
这种字段可以不用手动插入值,由系统提供默认的序列值,但必须满足以下要求:
1、只有主键才能设置
2、必须是数值型字段
3、一张表最多只能设置一个
设置方法:
-- 创建表时设置 create table 表名(字段 类型 primary key auto_increment, ); -- 修改表时设置 alter table 表名 modify 字段 类型 primary key auto_increment; alter table student modify id int primary key auto_increment;
初始值和步长:
alter table 表名 auto_increment = 初始值; set auto_increment_increment = value 设置步长; -- 也可以通过第一次手动插入数据设置初始值
4、索引
索引是一种提高查询速度的技术,如果把数据库看作字典,那么索引就是字典的目录。
创建索引:
create table 表名(...index [索引名] (字段,) ); -- 注意:创建的索引字段是经常在SQL语句的where字句条件上
添加索引:
alter table 表名 add index [索引名] (字段名);
查看索引:
show index from 表名; -- 注意:MySQL数据库会自动对表进行优化,主键、非空且唯一的字段会自动优化成索引。
删除索引:
drop index 索引名 on 表名;
索引的优点和缺点:
1、能大大提高数据库的查询速度。
2、但索引的本质其实也是硬盘地址的表,里面存储着字段数据所在的硬盘位置,创建索引需要额外的存储空间,是典型用空间换取时间。
3、而且使用索引虽然提高了查询速度,但会降低插入、更新、删除数据的速度。
4、MySQL数据库会自动为主键创建索引,所有在MySQL数据库中不建议主动创建索引。
5、视图
视图是一张虚拟的表,它本身并不包含数据,而是作为一个select语句保存在数据库中。
如果设计表时遵循了三大范式,我们的数据库中会有很多张表(零散),查询数据时会有很多连接查询,SQL语句就需要写的非常长,非常麻烦。
视图就是把常用的连接查询语句存储到数据库中。
创建视图:
create view 视图名 [字段名] as <select语句>; create view class_view as select * from class,student where class.class_id = student.class_id;
查看视图:
desc 视图名;
删除视图:
drop view 视图名;
使用视图的优、缺点:
1、可以只展现基本表的部分数据,不用关心基本表的结构;
2、使用视图的用户只能访问被允许访问的数据,对数据库权限的管理只能精细到某张表,但使用视图可以管理某些列的某些行,可以大大提高数据的安全性。
3、视图创建完成后,可以删除、添加列,而视图不受影响。
4、速度慢,无法修改视图中的数据,只能读。
十、扩展
1、导出数据(备份)
mysqldump -uroot -p123456 -hlocalhost testDB > testDB.sql
2、导入数据(恢复)
-- 登录数据库 mysql -utest -p mysql> use testDB; -- 把备份的数据导入到当前数据库 mysql> source /home/sunll/testDB.sql
3、SQL 注入
4、存储引擎

















