今天给大家介绍一篇最新的大模型+时间序列预测工作,由康涅狄格大学发表,提出了一种将时间序列在隐空间和NLP大模型对齐,并利用隐空间prompt提升时间序列预测效果的方法。

论文标题:S2IP-LLM: Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting
下载地址:https://arxiv.org/pdf/2403.05798v1.pdf
1
问题背景
大模型在时间序列上的应用越来越多,主要分为两类:第一类使用各类时间序列数据训练一个时间序列领域自己的大模型;第二类直接使用NLP领域训练好的文本大模型应用到时间序列中。由于时间序列不同于图像、文本,不同数据集的输入格式不同、分布不同,且存在distribution shift等问题,导致使用所有时间序列数据训练统一的模型比较困难。因此,越来越多的工作开始尝试如何直接使用NLP大模型解决时间序列相关问题。
本文的聚焦点也在第二种方法,即使用NLP大模型解决时间序列问题。现有的方法很多采用对时间序列的描述作为prompt,但是这种信息并不是所有时间序列数据集都有。并且现有的基于patch的时间序列数据处理方法,也无法完全保存时间序列数据本身的所有信息。
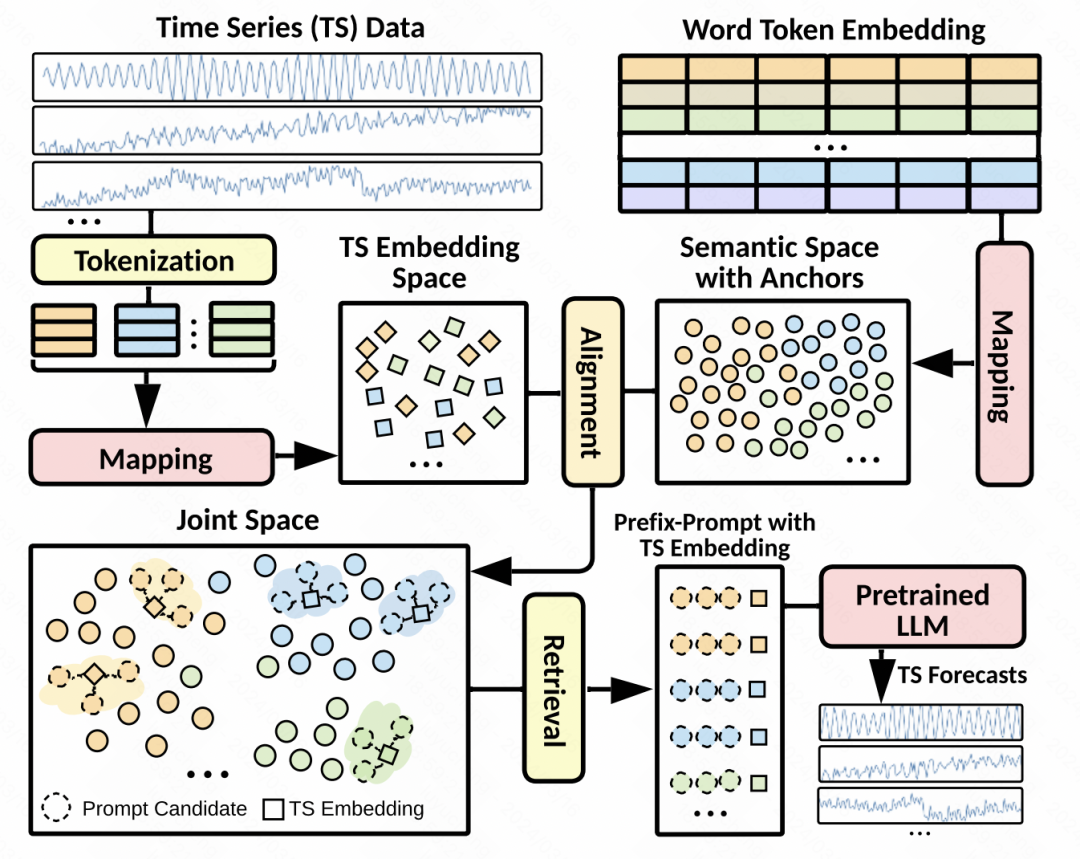
基于上述问题,这篇文章提出了一种新的建模方法,核心建模思路,一方面将时间序列通过tokenize处理后映射成embedding,另一方面将这些时间序列空间的表征对齐到大模型中的word embedding上。通过这种方式,让时间序列的预测过程中,可以找到对齐的word embedding相关的信息作为prompt,提升预测效果。
2
实现方法
下面从数据处理、隐空间对齐、模型细节等3个方面介绍一下这篇工作的实现方法。
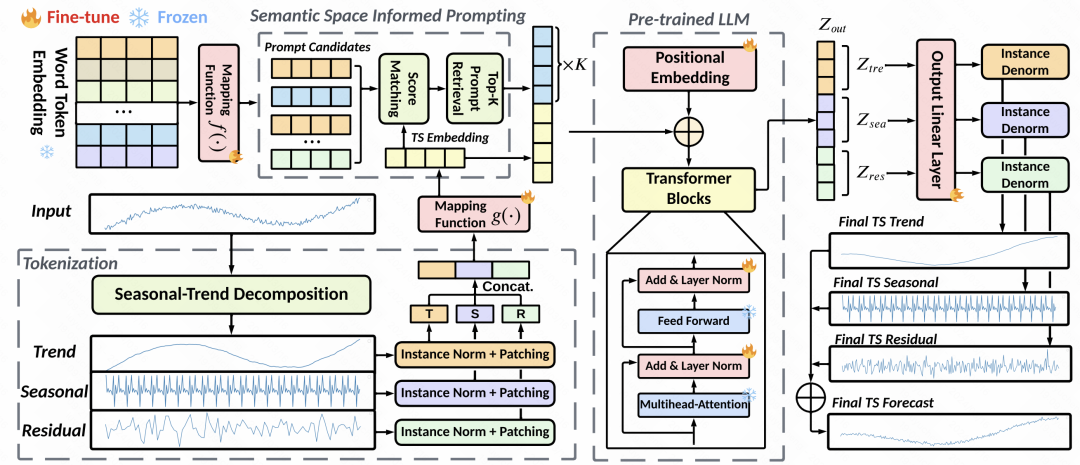
数据处理:由于时间序列的distribution shift等问题,本文对输入序列做了一步趋势项季节项分解。每个分解后的时间序列,都单独做标准化,然后分割成有重叠的patch。每一组patch对应趋势项patch、季节项patch、残差patch,将这3组patch拼接到一起,输入到MLP中,得到每组patch的基础embedding表征。
隐空间对齐:这是本文中最核心的一步。Prompt的设计对大模型的效果影响很大,而时间序列的prompt又难以设计。因此本文提出,将时间序列的patch表征和大模型的word embedding在隐空间对齐,然后检索出topK的word embedding,作为隐式的prompt。具体做法为,使用上一步生成的patch embedding,和语言模型中的word embedding计算余弦相似度,选择topK的word embedding,再将这些word embedding作为prompt,拼接到时间序列patch embedding的前方。由于大模型word embedding大多,为了减少计算量,先对word embedding做了一步映射,映射到数量很少的聚类中心上。
模型细节:在模型细节上,使用GPT2作为语言模型部分,除了position embedding和layer normalization部分的参数外,其余的都冻结住。优化目标除了MSE外,还引入patch embedding和检索出的topK cluster embedding的相似度作为约束,要求二者之间的距离越小越好。最终的预测结果,也是
3
实验效果
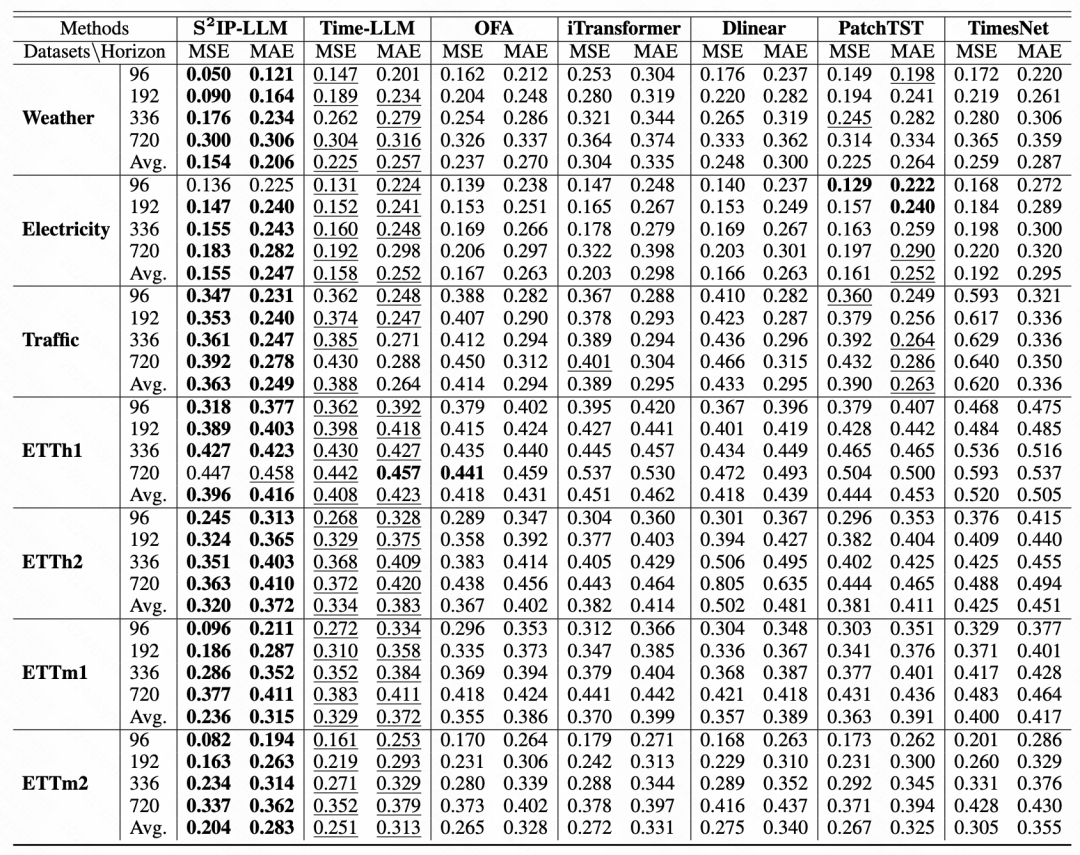
文中对比了和一些时间序列大模型、iTransformer、PatchTST等SOTA模型的效果,在大部分数据集的不同时间窗口的预测中都取得了比较好的效果提升。
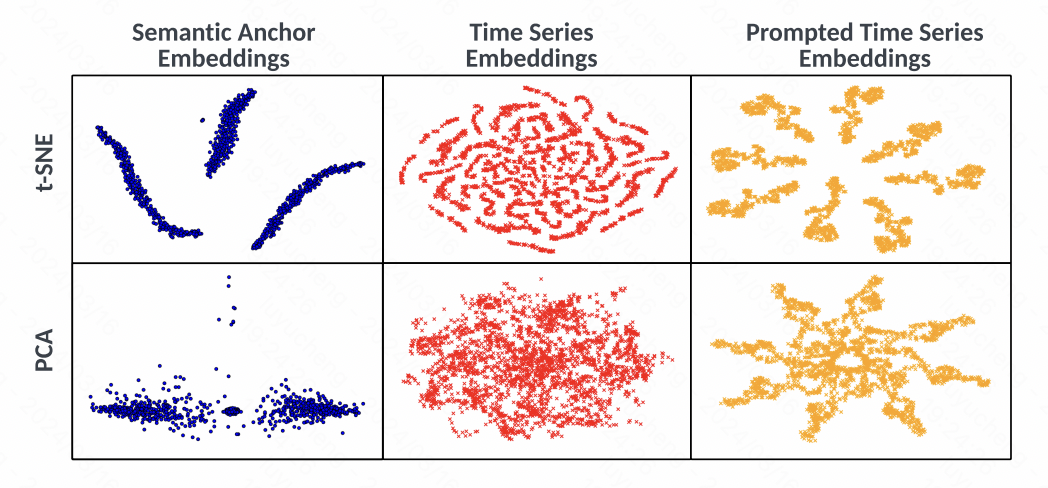
同时,文中也通过t-SNE可视化分析了embedding,从图中可以看出,时间序列的embedding在对齐之前并没有明显的类簇现象,而通过prompt生成的embedding有明显的类簇变化,说明本文提出的方法有效的利用文本和时间序列的空间对齐,以及相应的prompt,提升时间序列表征的质量。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。




