VLM
2024/9/14 2:00:31
视觉语言模型(VLMs)知多少?
最近这几年,自然语言处理和计算机视觉这两大领域真是突飞猛进,让机器不仅能看懂文字,还能理解图片。这两个领域的结合,催生了视觉语言模型,也就是Vision language models (VLMs) ,它们能同时处理视觉信息和…

AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.15-2024.04.25
文章目录~ 1.AutoGluon-Multimodal (AutoMM): Supercharging Multimodal AutoML with Foundation Models2.Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering3.CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pr…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.10-2024.04.15
文章目录~ 1.Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models2.Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection3.UNIAA: A Unified Multi-modal Image Aesthetic Assessment Base…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.10-2024.04.15
文章目录~ 1.Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models2.Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection3.UNIAA: A Unified Multi-modal Image Aesthetic Assessment Base…

多模态之ALBEF—先对齐后融合,利用动量蒸馏学习视觉语言模型表征,学习细节理解与论文详细阅读:Align before Fuse
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation (ALBEF)在融合之前对齐:利用动量蒸馏进行视觉与语言表示学习
Paper: arxiv.org/pdf/2107.07651.pdf
Github: https://github.com/salesforce/…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.10-2024.04.15
文章目录~ 1.Photo-Realistic Image Restoration in the Wild with Controlled Vision-Language Models2.Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection3.UNIAA: A Unified Multi-modal Image Aesthetic Assessment Base…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.25-2024.05.01
文章目录~ 1.Soft Prompt Generation for Domain Generalization2.Modeling Caption Diversity in Contrastive Vision-Language Pretraining3.Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM4.HELPER-X: A Unified Instructable Embodied Agent t…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.20-2024.05.25
文章目录~ 1.LM4LV: A Frozen Large Language Model for Low-level Vision Tasks2.Disease-informed Adaptation of Vision-Language Models3.VDGD: Mitigating LVLM Hallucinations in Cognitive Prompts by Bridging the Visual Perception Gap4.Composed Image Retrieval fo…
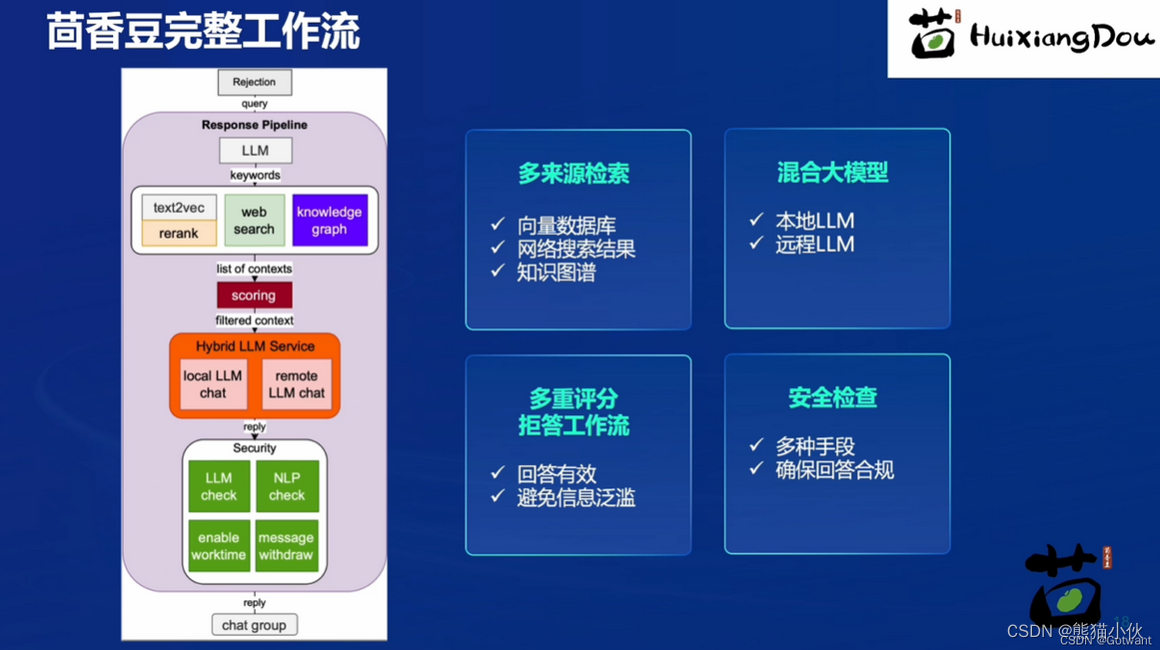
【第3节】“茴香豆“:搭建你的 RAG 智能助理
目录 1 基础知识1.1.RAG技术的概述1.2 RAG的基本结构有哪些呢?1.3 RAG 工作原理:1.4 向量数据库(Vector-DB ):1.5 RAG常见优化方法1.6RAG技术vs微调技术 2、茴香豆介绍2.1应用场景2.2 场景难点2.3 茴香豆的构建: 3 论文快读 1 基础…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.20-2024.05.25
文章目录~ 1.LM4LV: A Frozen Large Language Model for Low-level Vision Tasks2.Disease-informed Adaptation of Vision-Language Models3.VDGD: Mitigating LVLM Hallucinations in Cognitive Prompts by Bridging the Visual Perception Gap4.Composed Image Retrieval fo…
视觉语言模型(VLMs)知多少?
最近这几年,自然语言处理和计算机视觉这两大领域真是突飞猛进,让机器不仅能看懂文字,还能理解图片。这两个领域的结合,催生了视觉语言模型,也就是Vision language models (VLMs) ,它们能同时处理视觉信息和…
『大模型笔记』视觉语言模型解释
视觉语言模型解释 文章目录 一. 视觉语言模型解析1.什么是视觉语言模型?2. 开源视觉语言模型概览3. 如何找到合适的视觉语言模型MMMUMMBench4. 技术细节5.使用变压器 (transformers) 运用视觉语言模型6. 使用 TRL 微调视觉语言模型二. 参考文章一. 视觉语言模型解析
视觉语言…

本地部署 Llama-3-EvoVLM-JP-v2
本地部署 Llama-3-EvoVLM-JP-v2 0. 引言1. 关于 Llama-3-EvoVLM-JP-v22. 本地部署2-0. 克隆代码2-1. 安装依赖模块2-2. 创建 Web UI2-3.启动 Web UI2-4. 访问 Web UI 0. 引言
Sakana AI 提出了一种称为进化模型合并的方法,并使用该方法创建大规模语言模型ÿ…

MiniCPM 多模态VLM图像视频理解代码案例
参考: https://huggingface.co/openbmb/MiniCPM-V-2_6 https://github.com/OpenBMB/MiniCPM-V
效果很好,20g现场可以运行: 下载模型
export HF_ENDPOINT=https://hf-mirror.comhuggingface-cli download --resume-download --local-dir-use-symlinks False openbmb/MiniC…

「bug」nvitop ERROR: Failed to initialize curses
nvitop 作为一个优秀个 Nvidia显卡查询库,简单易用且显示信息十分丰富,相比 Nvidia-smi 更方便,简直是每个 开发人员必备的库,安装也十分方便,直接采用 pip install nvitop 即可,调用的时候也是直接在 Term…
「bug」nvitop ERROR: Failed to initialize curses
nvitop 作为一个优秀个 Nvidia显卡查询库,简单易用且显示信息十分丰富,相比 Nvidia-smi 更方便,简直是每个 开发人员必备的库,安装也十分方便,直接采用 pip install nvitop 即可,调用的时候也是直接在 Term…