MoE
2024/9/23 3:33:59
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…

详解Mixtral-8x7B背后的MoE!
高端的模型往往只需最朴素的发布方式。 这个来自欧洲的大模型团队在12月8日以一条磁力链接的方式发布了Mixtral-8x7B,这是一种具有开放权重的**「高质量稀疏专家混合模型」**(SMoE)。
该模型在大多数基准测试中都优于Llama2-70B,相比之下推理速度快了6倍,同时在大多数标准基…

TASK-CUSTOMIZEDMASKED AUTOENCODERVIA MIXTURE OF CLUSTER-CONDITIONAL EXPERTS
发表于:ICLR 2023 notable top 25%(相当于spotlight) 推荐指数: #paper/⭐⭐⭐ 论文链接: Task-customized Masked Autoencoder via Mixture of Cluster-conditional Experts | OpenReview poster链接:ICLR 2023 Task-customized Masked Auto…

【大模型理论篇】Mixture of Experts(混合专家模型, MOE)
1. MoE的特点及为什么会出现MoE
1.1 MoE特点 Mixture of Experts(MoE,专家混合)【1】架构是一种神经网络架构,旨在通过有效分配计算负载来扩展模型规模。MoE架构通过在推理和训练过程中仅使用部分“专家”(子模型&am…
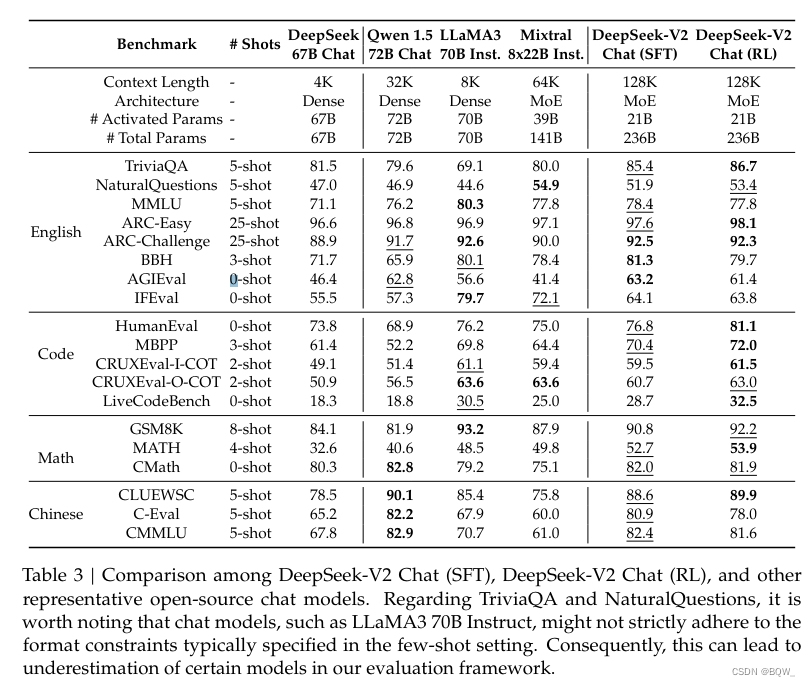
【自然语言处理】【大模型】DeepSeek-V2论文解析
论文地址:https://arxiv.org/pdf/2405.04434 相关博客 【自然语言处理】【大模型】DeepSeek-V2论文解析 【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM 【自然语言处理】BitNet b1.58:1bit LLM时代 【自然语言处理】【长文本…
【大模型理论篇】Mixture of Experts(混合专家模型, MOE)
1. MoE的特点及为什么会出现MoE
1.1 MoE特点 Mixture of Experts(MoE,专家混合)【1】架构是一种神经网络架构,旨在通过有效分配计算负载来扩展模型规模。MoE架构通过在推理和训练过程中仅使用部分“专家”(子模型&am…

Mixture of Experts with Attention论文解读
注意这篇论文没有代码,文章所谓的注意力是加性注意力,找scaled dot-product的伙计可以避坑了,但还是有值得学习的地方。 score是啥? 这个score标量怎么计算得到,请假设一下x和z的值,计算演示一下 expert是…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…

MoE专家模块Demo
文章目录 前言一、MoE原理与设计原则二、构建完整transformers与MoE集成模块三、专家模块定义四、路由门控模块五、稀疏MoE集成模块六、完整MoE的Demo 前言
随着MoE越来越火热,MoE本质就是将Transformer中的FFN层替换成了MoE-layer,其中每个MoE-Layer由…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…