合成数据
2024/9/23 7:27:58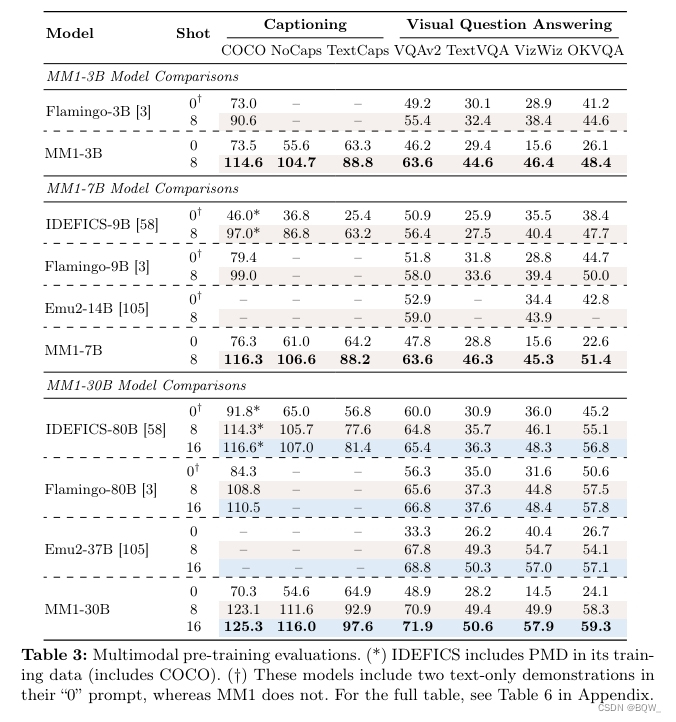
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…

【大模型理论篇】关于LLaMA 3.1 405B以及小模型的崛起
前不久,Meta开源了LLaMA 3.1 405B【1】,模型扩展了上下文长度至 128K,支持八种语言,效果非常惊艳,是首个在通用知识、可操控性、数学、工具使用和多语言翻译方面能够与最先进闭源 AI 模型媲美的公开可用模型࿰…
【极速前进】20240422:预训练RHO-1、合成数据CodecLM、网页到HTML数据集、MLLM消融实验MM1、Branch-Train-Mix
一、RHO-1:不是所有的token都是必须的
论文地址:https://arxiv.org/pdf/2404.07965.pdf
1. 不是所有token均相等:token损失值的训练动态。
使用来自OpenWebMath的15B token来持续预训练Tinyllama-1B,每1B token保存一个che…