DPO
2024/9/18 21:04:45
Apple LLM: 智能基础语言模型(AFM)
今天想和大家分享一下我最近在arXiv.org上看到苹果发表的一篇技术论文 Apple Intelligence Foundation Language Models (https://arxiv.org/abs/2407.21075),概述了他们的模型训练。这虽然出乎意料,但绝对是一个积极的惊喜! 这篇论文有那么多…

深入理解DPO(Direct Preference Optimization)算法
目录 1. 什么是DPO?2. Bradley-Terry模型2.1 奖励模型的训练 3. 从PPO到DPO4. DPO的简单实现5. 梯度分析Ref 1. 什么是DPO?
直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的…
深入理解DPO(Direct Preference Optimization)算法
目录 1. 什么是DPO?2. Bradley-Terry模型2.1 奖励模型的训练 3. 从PPO到DPO4. DPO的简单实现5. 梯度分析Ref 1. 什么是DPO?
直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的…
深入理解DPO(Direct Preference Optimization)算法
目录 1. 什么是DPO?2. Bradley-Terry模型2.1 奖励模型的训练 3. 从PPO到DPO4. DPO的简单实现5. 梯度分析Ref 1. 什么是DPO?
直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的…
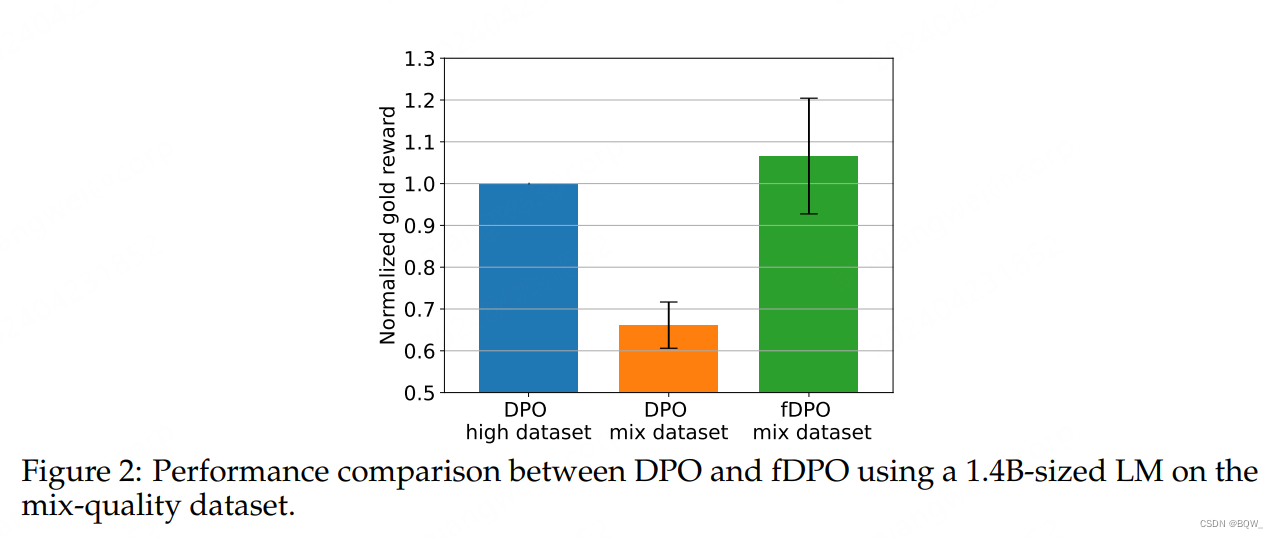
【极速前进】20240423-20240428:Phi-3、fDPO、TextSquare多模态合成数据、遵循准则而不是偏好标签、混合LoRA专家
一、Phi-3技术报告
论文地址:https://arxiv.org/pdf/2404.14219
发布了phi-3-mini,一个在3.3T token上训练的3.8B模型。在学术基准和内部测试中的效果都优于Mixtral 8*7B和GPT-3.5。此外,还发布了7B和14B模型phi-3-small和phi-3-medium。…