cuda
2024/9/15 17:03:59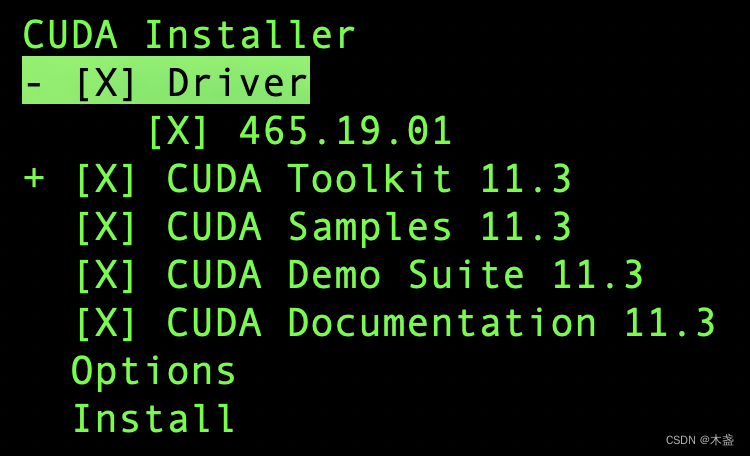
一文搞定cuda版本、显卡驱动及多CUDA版本管理
安装cuda是每个AI从业人员必经之路。网上关于cuda、显卡驱动已经相关命令很多都解释不清楚,于是本文梳理一下,既方便自己记忆,也方便小白学习。
CUDA
首先,CUDA版本,一般指cuda-toolkit,即cuda开发工具包…
![[12] 使用 CUDA 加速排序算法](/images/no-images.jpg)
[12] 使用 CUDA 加速排序算法
使用 CUDA 加速排序算法 排序算法被广泛用于计算应用中有很多排序算法,像是枚举排序或者说是秩排序、冒泡排序和归并排序,这些排序算法具有不同的(时间和空间)复杂度,因此对同一个数组来说也有不同的排序时间,对于大数组而言,可能会很耗时如果排序算法能用 CUDA 加速,则…
统计一条cuda ld指令需要经过哪些硬件单元--演示CuAssembler如何修改CUDA SASS指令
统计一条cuda ld指令需要经过哪些硬件单元--演示CuAssembler如何修改CUDA SASS指令 1.准备SASS反汇编工具CuAssembler2.仅包含ld.global.cv.f32的cuda kernel,如果不加st指令,编译器会将ld指令也优化掉。后面手动修改汇编指令删除掉st指令3.生成fatbin4.修改SASS指令,删除掉STG…

TensorRT从入门到了解(2)-学习笔记
目录 1.TensorRT的高性能部署简介2.TensorRT驾驭方案3.如何正确导出onnx4.动态batch和动态宽高的实现5.实现一个自定义插件6.关于封装7.YoloV5案例8.Retinaface案例9.高性能低耦合10.YOLOX集成参考 1.TensorRT的高性能部署简介
tensorRT,nvidia发布的dnn推理引擎&a…
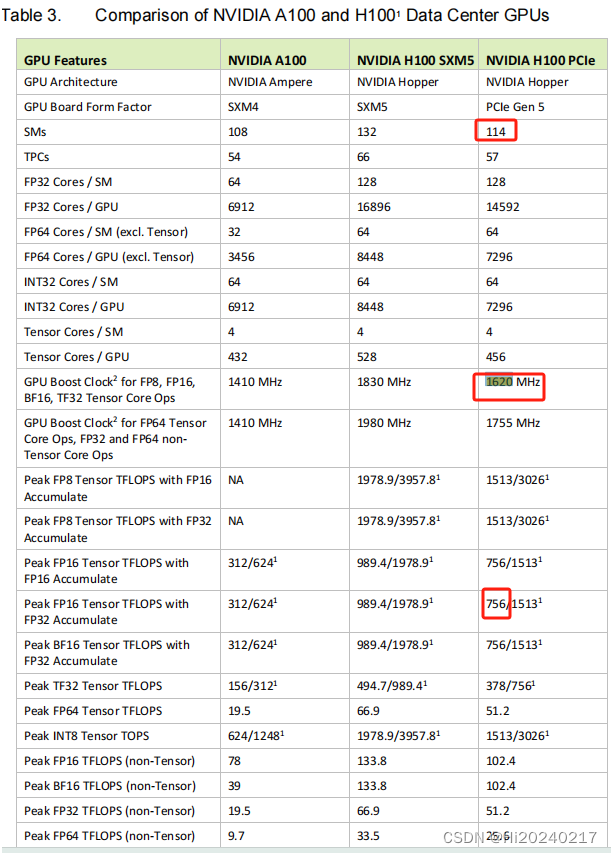
H800基础能力测试
H800基础能力测试 参考链接A100、A800、H100、H800差异H100详细规格H100 TensorCore FP16 理论算力计算公式锁频安装依赖pytorch FP16算力测试cublas FP16算力测试运行cuda-samples 本文记录了H800基础测试步骤及测试结果
参考链接
NVIDIA H100 Tensor Core GPU Architecture…
【深度学习】CUDA 和 cuDNN 的发展历程和版本特性 截止 CUDA 12.x 和 cuDNN 9.x
CUDA & cuDNN CUDA & cuDNN1. **CUDA 发展历程**2. **cuDNN 发展历程**3. **未来趋势** 写在最后 CUDA & cuDNN
CUDA(Compute Unified Device Architecture)和 cuDNN(CUDA Deep Neural Network Library)是 NVIDIA 推…

NVIDIA NCCL 源码学习(十四)- NVLink SHARP
背景
上节我们介绍了IB SHARP的工作原理,进一步的,英伟达在Hopper架构机器中引入了第三代NVSwitch,就像机间IB SHARP一样,机内可以通过NVSwitch执行NVLink SHARP,简称nvls,这节我们会介绍下NVLink SHARP如…
CUDA L2Cache Profing
CUDA L2Cache Profing 一.小结二.测试L2 Cache的驱逐策略三.测试Kernel执行完成后,l2Cache是否会被清 一.小结
当所有的warp都访问 2(warpcount)*32(threads)*4(bytes)的DRAM区间时,因DRAM BANK冲突,导致耗时太长开启l2 cache后,性能大幅提升推测kernel执行完之后或运行之前,L…

NVIDIA CUDA Toolkit
NVIDIA CUDA Toolkit
CUDA Toolkit 12.4 Update 1 Downloads | NVIDIA Developer CUDA Toolkit是用于CUDA开发的软件包,主要包括CUDA编译器、运行时库、GPU驱动程序和开发工具等。它允许开发者使用通用编程语言(如C、C)来利用NVIDIA GPU进行…

windows10 安装CUDA教程
如何在windows10系统上安装CUDA? 1、查看电脑的NVIDIA版本
nvidia-smi 2、官网下载所需CUDA版本 官网地址:https://developer.nvidia.com/cuda-toolkit-archive 我们所安装的CUDA版本需要小于等于本机电脑的NVIDIA版本。推荐使用迅雷下载,速度会更快哦。 3、安装步骤
![[CUDA 学习笔记] GEMM 优化: 双缓冲 (Prefetch) 和 Bank Conflict 解决](https://img-blog.csdnimg.cn/direct/8ddfa7b11ff641929062bcb301aee24f.png)
[CUDA 学习笔记] GEMM 优化: 双缓冲 (Prefetch) 和 Bank Conflict 解决
GEMM 优化: 双缓冲 (Prefetch) 和 Bank Conflict 解决
前言
本文主要是对 深入浅出GPU优化系列:GEMM优化(一) - 知乎, 深入浅出GPU优化系列:GEMM优化(二) - 知乎 以及 深入浅出GPU优化系列:GE…
NVIDIA GPU atom.global指令Profing
NVIDIA GPU atom.global指令Profing 一.小结二.输出解释三.复现过程 本文对NVIDIA GPU atom.global指令Profing,并小结
一.小结
sm atom指令的执行能力为:112 inst/cycle,每条atom warp指令会产生32个request,即3584 request/cyclelts有18个slice,每个slice处理能力为 1 requ…
问题解决:CUDA_HOME environment variable is not set.
CUDA_HOME environment variable is not set. Please set it to your CUDA install root.
Firstly, I couldn’t run “git clone gitgithub.com:facebookresearch/segment-anything-2.git” command, this give permission denied. So I used “git clone https://github.com…

C++开发基础之理解 CUDA 编译配置:`compute_XX` 和 `sm_XX` 的作用
前言
在 CUDA 编程中,确保代码能够在不同的 NVIDIA GPU 上高效运行是非常重要的。为了实现这一点,CUDA 编译器 (nvcc) 提供了多种配置选项,其中 compute_XX 和 sm_XX 是两个关键的编译选项。本文将深入探讨这两个选项的作用及其配置顺序&…
CUDA_cudaFree_释放Stream_cudaError_t 错误类型码解释
官方网站 :
CUDA Runtime API :: CUDA Toolkit Documentation
cudaFree() 说明
cudaFree() 是 CUDA 中用于释放由 cudaMalloc() 或 cudaMallocManaged() 分配的设备内存的函数。它的参数是一个指向设备内存的指针,用于指示要释放的内存块的起始地址。…

triton之语法学习
一 基本语法
1 torch中tensor的声明 x = torch.tensor([[1,2, 1, 1, 1, 1, 1, 1],[2,2,2,2,2,2,2,2]],device=cuda) 声明的时候有的时候需要指出数据的类型,不然在kernel中数据类型无法匹配 x = torch.tensor([1,2,1,1,1,1,1,1],dtype = torch.int32,device=cuda) 2 idx
id…