big data
2024/9/18 12:39:22
SparkSQL---简介及RDD V.S DataFrame V.S Dataset编程模型详解
一、SparkSQL简介
SparkSQL,就是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块。SparkSQL的前身不叫SparkSQL,而叫Shark,最开始的时候底层代码优化,sql的解析、执行引擎等等完全基于Hive,总之Sha…

MaxWell实时监控Mysql并把数据写入到Kafka主题中
配置mysql
启用MySQL Binlog MySQL服务器的Binlog默认是未开启的,如需进行同步,需要先进行开启
修改MySQL配置文件/etc/my.cnf
sudo vim/etc/my.cof
增加如下配置 注:MySQL Binlog模式
Statement-based:基于语句,…

【Kafka】分区与复制机制:解锁高性能与容错的密钥
🐇明明跟你说过:个人主页
🏅个人专栏:《大数据前沿:技术与应用并进》🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、kafka简介
2、kafka使用场景
二、Kafka消息可…
SparkSQL---简介及RDD V.S DataFrame V.S Dataset编程模型详解
一、SparkSQL简介
SparkSQL,就是Spark生态体系中的构建在SparkCore基础之上的一个基于SQL的计算模块。SparkSQL的前身不叫SparkSQL,而叫Shark,最开始的时候底层代码优化,sql的解析、执行引擎等等完全基于Hive,总之Sha…
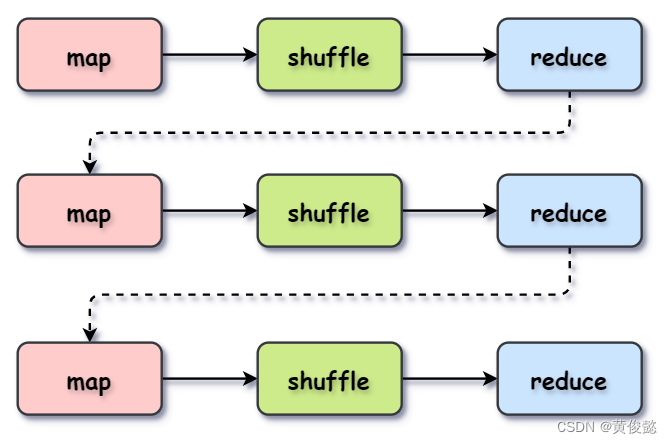
【图解大数据技术】Spark
【图解大数据技术】Spark Spark简介RDDSpark示例Spark运行原理整体流程DAG 与 stage 为什么Spark比MapReduce快? Spark简介
Spark与MapReduce一样,也是大数据计算框架。Spark相比MapReduce拥有更快的执行速度和更低的编程复杂度。
Spark包括以下几个模…
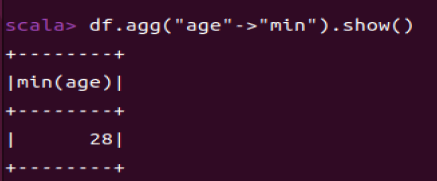
Spark SQL编程初级实践
参考链接
Spark编程: Spark SQL基本操作 2020.11.01_df.agg("age"->"avg")-CSDN博客
RDD编程初级实践-CSDN博客
Spark和Hadoop的安装-CSDN博客
1. Spark SQL基本操作
{ "id":1 , "name":" Ella" , "age":…

大数据开发如何快速进阶
目录 1. 个人经验与心得分享1.1 试错的价值与机会把握1.2 投入产出比的考量1.3 刻意练习与技能提升1.4 目标设定与职业规划1.5 自我驱动与成长1.6 第一性原理的应用 2. 大数据开发领域的挑战与机遇2.1 技术革新的挑战2.2 数据治理的难题2.3 人才短缺的问题2.4 投入产出比的考量…

微软Access之后,惊现国产新式数据处理软件,风头正盛
“excel使用高手,比不上Access入门新手”这一观点在IT界广为流传,凸显了Access的独特地位。 尽管Access与Excel在操作界面上有着诸多相似之处,但Access自1992年诞生以来,就承载着80后一代的深厚情感。在那个时代,CCED、…
4款黑科技软件,其中三款功能过于强大,被误认为是外国佬开发的
国人对国产软件的刻板印象往往是“捆绑安装、弹窗广告、高昂收费”,这使得许多优秀的国产软件如同明珠蒙尘,鲜为人知。甚至有些软件的功能之强大,以至于常被人们误以为是出自外国佬开发,这实在是令人遗憾的事情。
1、VeryCapture…
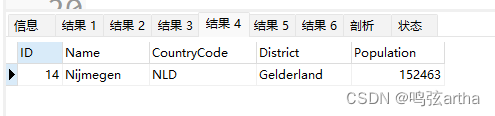
MySQL——变量的定义与使用
新建链接,自带world数据库,里面自带city表格。
DQL
# MySQL变量的定义与使用
#1、不允许数字作为开头
#2、只能用_或$符号,不允许使用其他符号
#3、不允许使用关键字或保留字
set userName小可爱;
select userName;
#标识符只影响当前查询#…
良心无广的4款软件,每一款都逆天好用,且用且珍惜
闲话少说,直上干货!
清浊
清浊是一款异常强大的国产手机清理应用,其设计理念崇尚简洁,用户界面清晰明快,且无任何弹窗广告干扰。更难能可贵的是,这款应用提供全程免费服务,功能多样࿰…

开源之夏「万元奖金」同学~你的开源任务包已送达,请查收!
Hi~同学 ! 想和技术大牛一起参与 开源贡献 吗? 更深入地了解数据库的设计思想 、工作原理 、最佳实践 ,构建第一个基于PostgreSQL并兼容Oracle的开源数据库。 你的代码,你的思想,将直接影响到成千上万的用户体验 。 加入我们&…

家具的温柔拥抱 -- 缓冲器,每一次开关是爱的表达
在日常生活中,每一次与家具的互动是一种情感的交流。家具缓冲器,就像是家具给予我们的一次次温柔拥抱,它们默默地工作着,让每一次开关动作充满了爱意与关怀。这些看似微不足道的细节,其实蕴含着对家居生活的无限热爱。…

入门指南 | Datavines 安装部署篇
摘要:本文主要介绍基于源码部署 Datavines 和执行检查作业,内容主要分为以下几个部分: 平台介绍快速部署运行数据质量检查作业 Datavines 的目标是成为更好的数据可观测性领域的开源项目,为更多的用户去解决元数据管理和数据质量管…
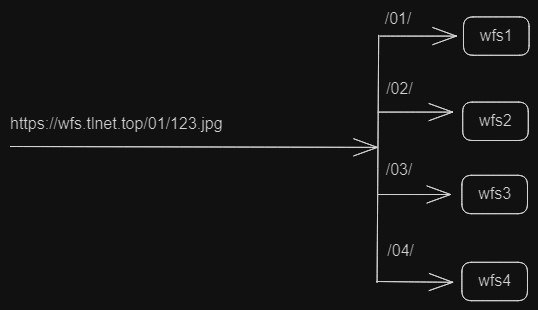
如何部署 wfs 分布式服务
说明: wfs是海量小文件存储系统。wfs1.x不直接支持分布式存储,但为了应对大规模部署和高可用需求,推荐采用如Nginx这样的负载均衡服务,通过合理的资源配置和定位策略,可以在逻辑上模拟出类似分布式的效果。也就是说&am…

Big Data 流处理框架 Flink
Big Data 流处理框架 Flink 什么是 FlinkFlink 的主要特性典型应用场景 Amazon Elastic MapReduce (EMR) VS Flink架构和运行时环境实时处理能力开发和编程模型操作和管理应用场景总结 Flink 支持的数据源Flink 如何消费 AWS SQS 数据源自定义 Source FunctionFlink Connector …