数据可视化技术第一次实验
Tips:"分享是快乐的源泉💧,在我的博客里,不仅有知识的海洋🌊,还有满满的正能量加持💪,快来和我一起分享这份快乐吧😊!
喜欢我的博客的话,记得点个红心❤️和小关小注哦!您的支持是我创作的动力!"
pythonjupyter_notebook_7">1. 实验准备:安装python相关软件与jupyter notebook相关软件
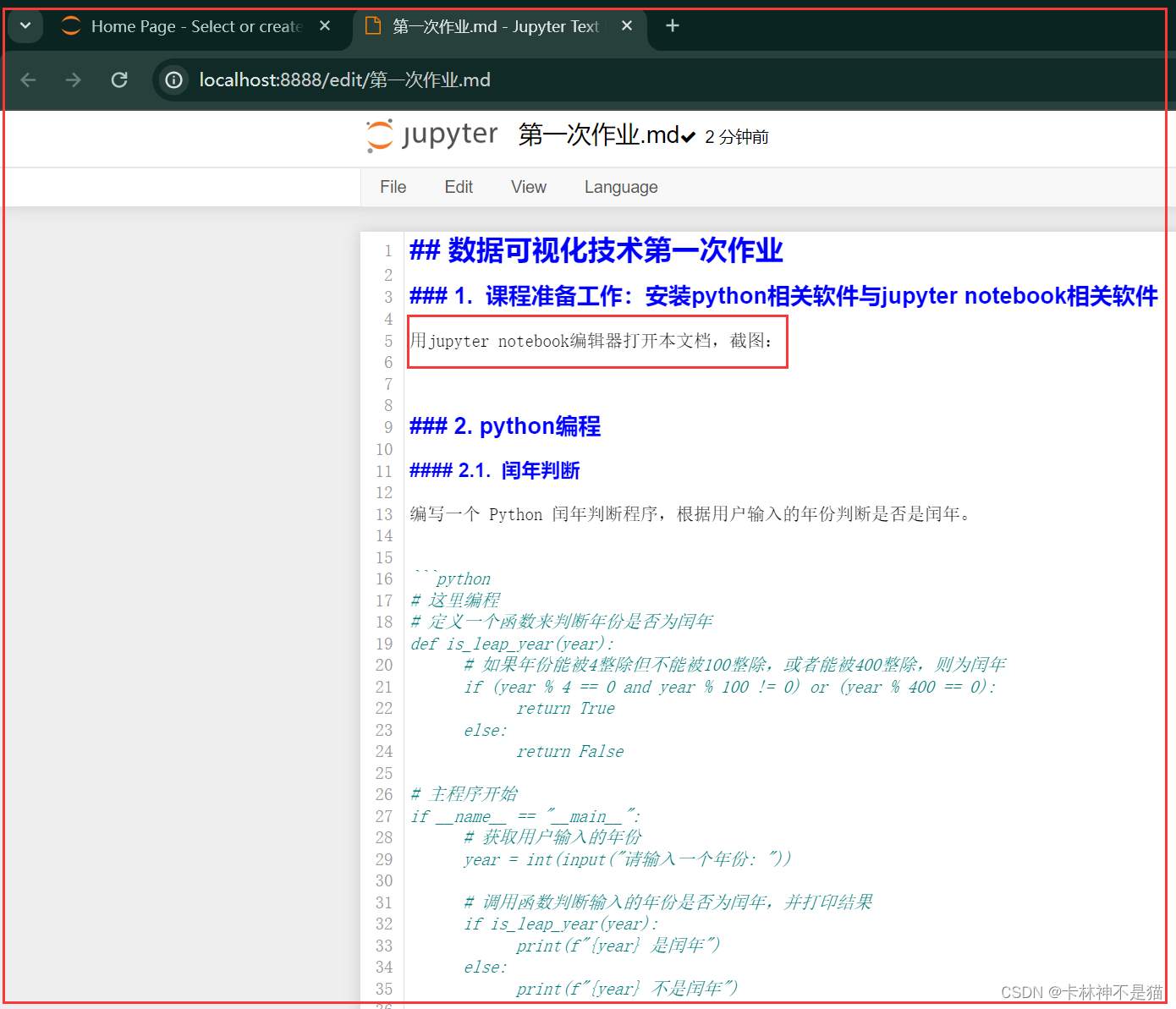
用jupyter notebook编辑器打开本文档,截图:
python_16">2. python编程
2.1. 闰年判断
编写一个 Python 闰年判断程序,根据用户输入的年份判断是否是闰年。
python"># 这里编程
# 定义一个函数来判断年份是否为闰年
def is_leap_year(year): # 如果年份能被4整除但不能被100整除,或者能被400整除,则为闰年 if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0): return True else: return False # 主程序开始
if __name__ == "__main__": # 获取用户输入的年份 year = int(input("请输入一个年份: ")) # 调用函数判断输入的年份是否为闰年,并打印结果 if is_leap_year(year): print(f"{year} 是闰年") else: print(f"{year} 不是闰年")

2.2. 统计字符
编写一个 Python 程序,根据输入的文本统计并输出其中英文字符、数字、空格和其他字符的个数。
输入格式
2008年起,中央文明办组织开展网上“我推荐我评议身边好人”活动,至今已发布“中国好人榜”150期,共有 16228 人(组)入选“中国好人”。
输出格式
在您输入的字符中,共含文字46个,数字12个,空格2个,其他字符12。
python"># 这里编程
# 定义一个函数,用于统计文本中各种字符的数量
def count_characters(text): # 初始化计数器 letter_count = 0 # 英文字符个数 digit_count = 0 # 数字个数 space_count = 0 # 空格个数 other_count = 0 # 其他字符个数 # 遍历文本中的每个字符 for char in text: # 判断字符类型并更新相应计数器 if char.isalpha(): # 如果字符是字母(英文字符) letter_count += 1 elif char.isdigit(): # 如果字符是数字 digit_count += 1 elif char.isspace(): # 如果字符是空格 space_count += 1 else: # 其他类型的字符 other_count += 1 # 返回统计结果 return letter_count, digit_count, space_count, other_count # 主程序开始
if __name__ == "__main__": # 获取用户输入的文本 text = input("请输入一段文本:") # 调用函数统计字符数量 letter_count, digit_count, space_count, other_count = count_characters(text) # 打印输出结果 print(f"在您输入的字符中,共含文字{letter_count}个,数字{digit_count}个,空格{space_count}个,其他字符{other_count}个。")

2.3. 乘法口诀
编写一个 Python 程序打印乘法口诀。
python"># 这里编程
# 乘法口诀表
for i in range(1, 10): # 外层循环控制行数 for j in range(1, i+1): # 内层循环控制列数 print(f'{j}x{i}={i*j}', end='\t') # 使用 \t 制表符分隔每个乘法表达式 print() # 换行,进入下一行的打印

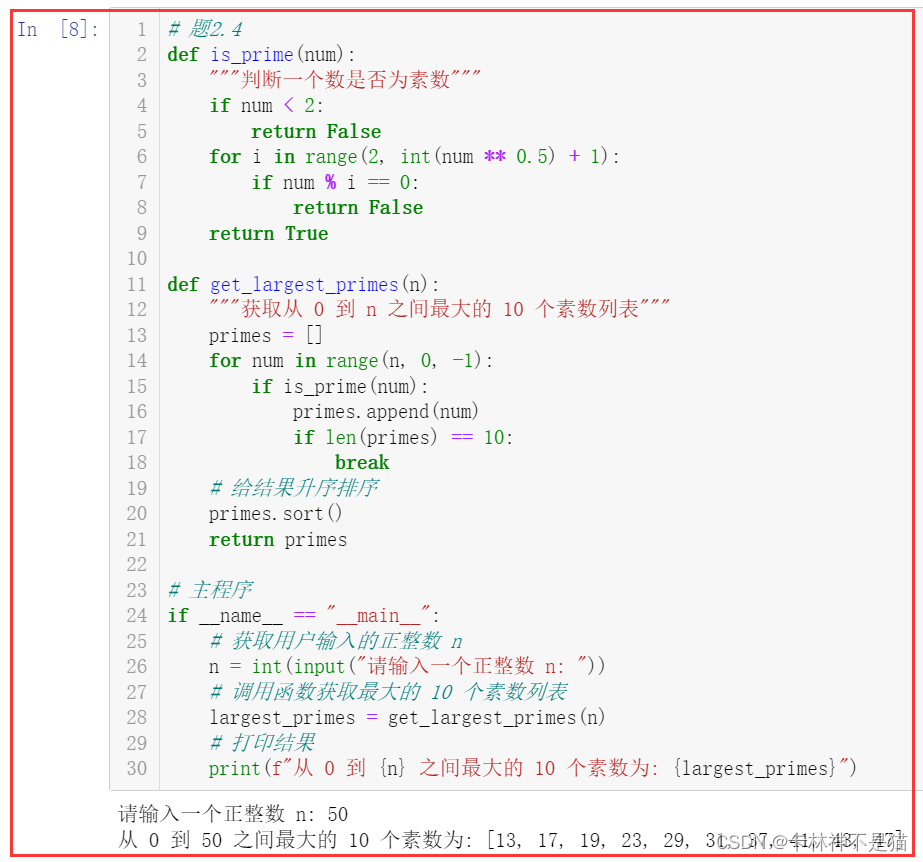
2.4. 素数列表
编写一个 Python 函数程序,获取用户输入的正整数 n,统计从 0-n 之间的最大的 10 个素数列表,以从小到大排序。
例如:输入 50 ,结果为 [13, 17, 19, 23, 29, 31, 37, 41, 43, 47]。
python"># 这里编程
def is_prime(num): """判断一个数是否为素数""" if num < 2: return False for i in range(2, int(num ** 0.5) + 1): if num % i == 0: return False return True def get_largest_primes(n): """获取从 0 到 n 之间最大的 10 个素数列表""" primes = [] for num in range(n, 0, -1): if is_prime(num): primes.append(num) if len(primes) == 10: break# 给结果升序排序primes.sort()return primes # 主程序
if __name__ == "__main__": # 获取用户输入的正整数 n n = int(input("请输入一个正整数 n: ")) # 调用函数获取最大的 10 个素数列表 largest_primes = get_largest_primes(n) # 打印结果 print(f"从 0 到 {n} 之间最大的 10 个素数为: {largest_primes}")
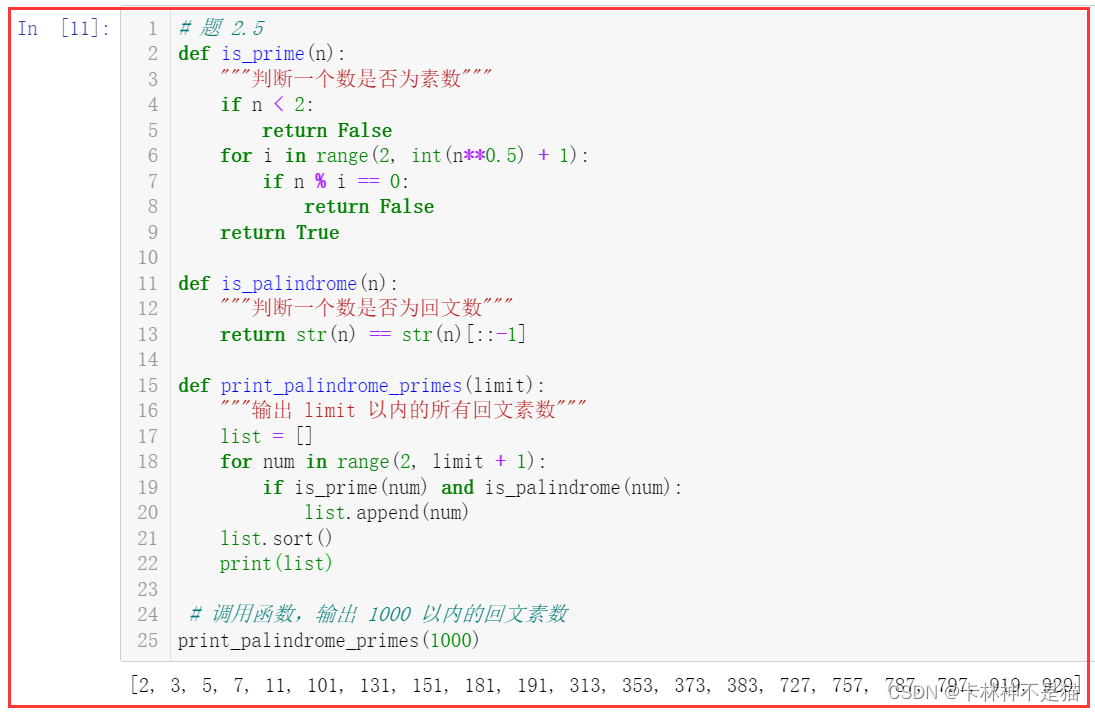
2.5. 回文素数
编写一个 Python 函数程序,输出1000以内的回文素数。
回文素数是指一个数既是素数又是回文数。例如,181,既是素数又是回文数。
python"># 这里编程
def is_prime(n): """判断一个数是否为素数""" if n < 2: return False for i in range(2, int(n**0.5) + 1): if n % i == 0: return False return True def is_palindrome(n): """判断一个数是否为回文数""" return str(n) == str(n)[::-1] def print_palindrome_primes(limit): """输出 limit 以内的所有回文素数"""list = []for num in range(2, limit + 1): if is_prime(num) and is_palindrome(num): list.append(num) list.sort()print(list)# 调用函数,输出 1000 以内的回文素数
print_palindrome_primes(1000)
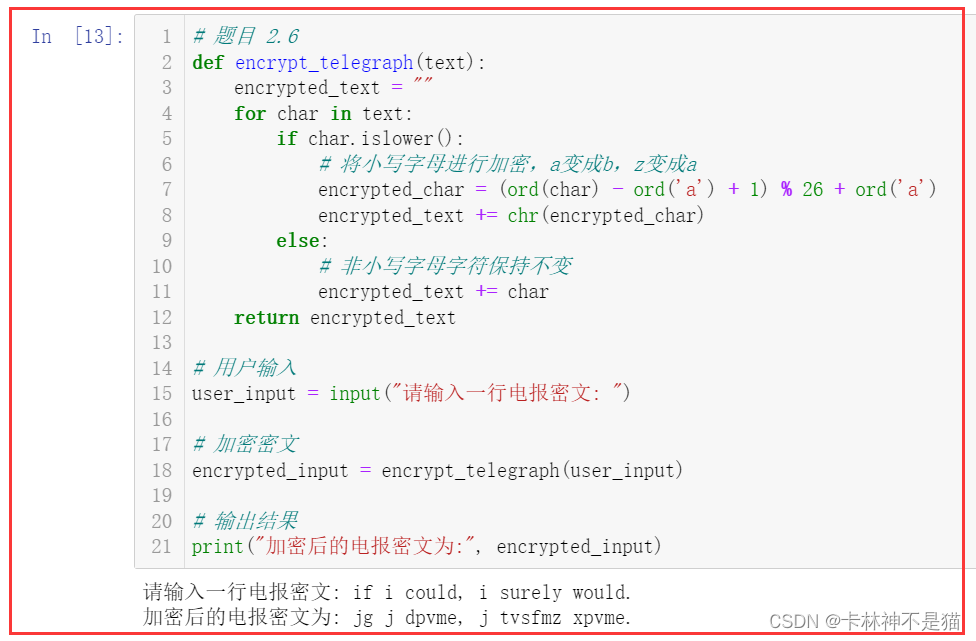
2.6. 加密电报
编写一个 Python 程序获取用户的输入的一行电报密文,将密文中的小写字母进行加密,例如 a 变成 b, z 变成a 其它字符不变。
输入格式
if i could, i surely would.
输出格式
jg j dpvme, j tvsfmz xpvme.
python"># 这里编程def encrypt_telegraph(text): encrypted_text = "" for char in text: if char.islower(): # 将小写字母进行加密,a变成b,z变成a encrypted_char = (ord(char) - ord('a') + 1) % 26 + ord('a') encrypted_text += chr(encrypted_char) else: # 非小写字母字符保持不变 encrypted_text += char return encrypted_text # 用户输入
user_input = input("请输入一行电报密文: ") # 加密密文
encrypted_input = encrypt_telegraph(user_input) # 输出结果
print("加密后的电报密文为:", encrypted_input)
2.7. 列表去重
编写一个 Python 程序,获取用户输入的列表,去除列表中重复的元素并返回一个新列表,
输入格式
[1,2,3,3,3,3,4,5]
输出格式
[1, 2, 3, 4, 5]
python"># 这里编程
# 获取用户输入的列表,字符串格式,如 '[1,2,3,3,3,3,4,5]'
user_input = input("请输入列表(格式如:[1,2,3,3,3,3,4,5]): ") # 尝试将输入的字符串转换为列表
try: input_list = eval(user_input) # 使用集合(set)来去除重复元素,并转换回列表 unique_list = list(set(input_list)) # 输出结果 print(unique_list)
except Exception as e: # 如果输入不是有效的列表格式,则打印错误信息 print(f"输入错误:{e}")

2.8. 条件求和
编写一个 Python 程序根据输入的数据和产品名称求和。
数据
data = [
{“品名”: “橡皮擦”, “销售量”: 31},
{“品名”: “铅笔”, “销售量”: 36},
{“品名”: “毛笔”, “销售量”: 27},
{“品名”: “尺子”, “销售量”: 27},
{“品名”: “篮球”, “销售量”: 26},
{“品名”: “钢笔”, “销售量”: 22},
{“品名”: “橡皮擦”, “销售量”: 36},
{“品名”: “毛笔”, “销售量”: 31},
{“品名”: “笔记本”, “销售量”: 35},
{“品名”: “自动铅笔”, “销售量”: 38}
]
输入格式
橡皮擦
输出格式
产品:橡皮擦 的销售量为 67 个
python"># 这里编程data = [{"品名": "橡皮擦", "销售量": 31},{"品名": "铅笔", "销售量": 36},{"品名": "毛笔", "销售量": 27},{"品名": "尺子", "销售量": 27},{"品名": "篮球", "销售量": 26},{"品名": "钢笔", "销售量": 22},{"品名": "橡皮擦", "销售量": 36},{"品名": "毛笔", "销售量": 31},{"品名": "笔记本", "销售量": 35},{"品名": "自动铅笔", "销售量": 38}
]# 输入产品名称
product_name = input("请输入产品名称: ") # 初始化销售量总和为0
total_sales = 0 # 遍历数据列表,查找匹配的产品并累加销售量
for item in data: if item["品名"] == product_name: total_sales += item["销售量"] # 输出结果
print(f"产品:{product_name} 的销售量为 {total_sales} 个")

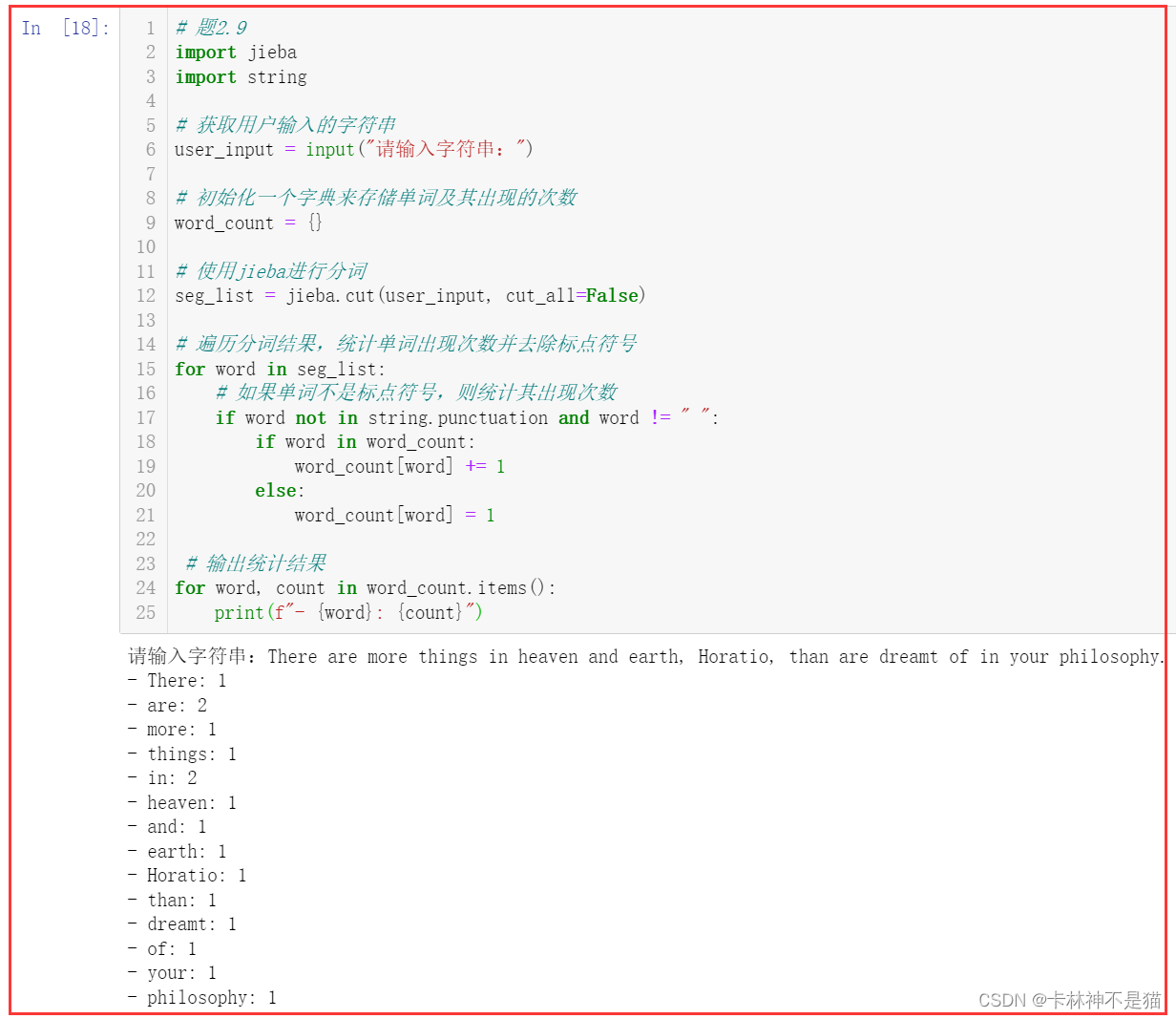
2.9. 单词统计
编写一个 Python 程序,获取用户输入的字符串,使用 jieba 库进行分词后,统计给定字符串中各单词出现的次数,去除标点符号,如"," “.” " "。
输入格式
There are more things in heaven and earth, Horatio, than are dreamt of in your philosophy.
输出格式
- There: 1
- are: 2
- more: 1
- things: 1
- in: 2
- heaven: 1
- and: 1
- earth: 1
- Horatio: 1
- than: 1
- dreamt: 1
- of: 1
- your: 1
- philosophy: 1
提示:使用jieba库
python"># 这里编程#在jupyter notebook中直接输入:!pip install [库名]
# !pip install jieba
import jieba
import string # 获取用户输入的字符串
user_input = input("请输入字符串:") # 初始化一个字典来存储单词及其出现的次数
word_count = {} # 使用jieba进行分词
seg_list = jieba.cut(user_input, cut_all=False) # 遍历分词结果,统计单词出现次数并去除标点符号
for word in seg_list: # 如果单词不是标点符号,则统计其出现次数 if word not in string.punctuation and word != " ": if word in word_count: word_count[word] += 1 else: word_count[word] = 1 # 输出统计结果
for word, count in word_count.items(): print(f"- {word}: {count}")
2.10. 集合操作
编写一个 Python 程序,将元组(“北京”, “上海”, “广州”, “武汉”, “成都”, “上海”, “武汉”)进行一些操作,操作要求如下:
- 删除重复元素
- 将元素 “北京” 更换为 “Beijing”
- 处理后所有元素使用sorted函数进行排序,并输出显示
city = (“北京”, “上海”, “广州”, “武汉”, “成都”, “上海”, “武汉”)
输出格式
[‘Beijing’, ‘上海’, ‘广州’, ‘成都’, ‘武汉’]
python"># 这里编程# 原始元组
city = ("北京", "上海", "广州", "武汉", "成都", "上海", "武汉") # 删除重复元素
unique_cities = tuple(set(city)) # 将元素 "北京" 更换为 "Beijing"
replaced_cities = tuple(city.replace("北京", "Beijing") if city == "北京" else city for city in unique_cities) # 排序并输出显示
sorted_cities = sorted(replaced_cities)
print(sorted_cities)

2.11. 数据脱敏
编写一个 Python 程序,将用户的个人信息进行脱敏输出,脱敏规则如下:
- 姓名:第2位修改为*,如陈建军 修改为陈*军。
- 电话:第4-7位 修改为*,如15673253514中修改为156****3514。
- 邮箱:第3-4位修改为*,如minfan@example.net 修改为mi**an@example.net。
输出格式
0.施兰 151***2817 zh**gjuan@example.net
1.陈香 145***4991 ka**juan@example.com
2.陈军 137***5682 mi**6@example.net
3.王荣 189***7401 ji**ang@example.com
4.李* 152****1019 xi**iong@example.net
5.王* 130****7835 ya**44@example.com
6.邵国 181***0903 ma**ao@example.com
7.陈* 186****1421 qi**g23@example.net
8.王* 153****8240 rg**g@example.net
9.林* 156****3514 mi**an@example.net
data = [
[‘施玉兰’, ‘15190162817’, ‘zhongjuan@example.net’],
[‘陈桂香’, ‘14570034991’, ‘kangjuan@example.com’],
[‘陈建军’, ‘13784015682’, ‘min96@example.net’],
[‘王桂荣’, ‘18934117401’, ‘jietang@example.com’],
[‘李婷’, ‘15293021019’, ‘xiaxiong@example.net’],
[‘王杨’, ‘13018567835’, ‘yang44@example.com’],
[‘邵建国’, ‘18151210903’, ‘maotao@example.com’],
[‘陈成’, ‘18604911421’, ‘qiang23@example.net’],
[‘王成’, ‘15317678240’, ‘rgong@example.net’],
[‘林婷’, ‘15673253514’, ‘minfan@example.net’]
]
python"># 这里编程def desensitize_data(data): desensitized_data = [] for record in data: name, phone, email = record # 脱敏姓名:第2位修改为* desensitized_name = name[0] + '*' + name[2:] # 脱敏电话:第4-7位修改为* desensitized_phone = phone[:3] + '****' + phone[-4:] # 脱敏邮箱:第3-4位修改为* desensitized_email = email[:2] + '**' + email[4:] desensitized_record = [desensitized_name, desensitized_phone, desensitized_email] desensitized_data.append(desensitized_record) return desensitized_data # 输入数据
data = [ ['施玉兰', '15190162817', 'zhongjuan@example.net'], ['陈桂香', '14570034991', 'kangjuan@example.com'], ['陈建军', '13784015682', 'min96@example.net'], ['王桂荣', '18934117401', 'jietang@example.com'], ['李婷', '15293021019', 'xiaxiong@example.net'], ['王杨', '13018567835', 'yang44@example.com'], ['邵建国', '18151210903', 'maotao@example.com'], ['陈成', '18604911421', 'qiang23@example.net'], ['王成', '15317678240', 'rgong@example.net'], ['林婷', '15673253514', 'minfan@example.net']
] # 脱敏处理并输出
desensitized_data = desensitize_data(data)
for index, record in enumerate(desensitized_data): print(f"{index+1}.{record[0]} {record[1]} {record[2]}")
2.12. 判断IP地址合法性
互联网上的每台计算机都有一个独一无二的编号,称为IP地址,每个合法的IP地址由’.‘分隔开的4个数字组成,每个数字的取值范围是0-255。 现在用户输入一个字符串 s (不含空白符,不含前导0,如001直接输入1),请你判断 s 是否为合法IP,若是,输出’Yes’,否则输出’No’。 如用户输入为202.114.88.10, 则输出Yes; 当用户输入202.114.88,则输出No。
输入格式
一个字符串
输出格式
输出’Yes’或’No’
示例
输入:255.255.255.0
输出:Yes
python"># 这里编程
def is_valid_ip(ip): # 分割IP地址的四个部分 parts = ip.split('.') # 检查是否有4个部分 if len(parts) != 4: return 'No' # 遍历每个部分并检查其是否合法 for part in parts: # 检查是否为整数且值在0-255之间 if not part.isdigit() or int(part) < 0 or int(part) > 255: return 'No' # 如果所有部分都合法,则返回'Yes' return 'Yes' # 测试函数
ip_address = input("输入:")
print("输出:", is_valid_ip(ip_address))

2.13. 采用lambda匿名函数比较两个数的大小,返回较大的数
python"># 这里编程
# 定义lambda函数
compare_numbers = lambda x, y: x if x > y else y # 测试lambda函数
num1 = 5
num2 = 10
result = compare_numbers(num1, num2)
print(result) # 输出: 10

2.14. 采用lambda累加函数
编写一个函数实现从 1 到 N 共 N 个数的累加
python"># 这里编程# 定义lambda函数,虽然这里其实并不需要lambda,因为sum和range已经足够
accumulate = lambda N: sum(range(1, N + 1)) # 测试函数
N = 10
result = accumulate(N)
print(f"从1累加到{N}的和是: {result}")

2.15. 请写一个函数 equals ,该函数参数为任意数量的数字,请在函数中统计出这些参数数字中重复的数字有多少个
比如 :
equals(3, 4, 3, 4, 1, 6, 2)
输出为:
- 数字 3 出现了 2 次
- 数字 4 出现了 2 次
- 数字 1 出现了 1 次
- 数字 6 出现了 1 次
- 数字 2 出现了 1 次
python"># 这里编程def equals(*args): # 使用字典来记录每个数字出现的次数 counts = {} # 遍历传入的参数 for num in args: # 如果数字已经在字典中,增加其计数 if num in counts: counts[num] += 1 # 如果数字不在字典中,初始化其计数为1 else: counts[num] = 1 # 输出每个数字及其出现的次数 for num, count in counts.items(): print(f"- 数字 {num} 出现了 {count} 次") # 调用函数并传入参数
equals(3, 4, 3, 4, 1, 6, 2)

2.16. 递归函数 猴子吃桃
猴子第1天摘了一堆桃子吃了一半又多一个,第2天吃了剩下的一半又多一个,…,第10天早上时发现只有1个桃子了。问第1天摘了多少?
python"># 这里编程
# 从第10天开始回溯
peaches = 1 # 第10天早上的桃子数量 # 逆向操作,计算第1天的桃子数量
for day in range(9, 0, -1): peaches = (peaches + 1) * 2 # 根据题目,前一天晚上的桃子数量是 (当前桃子数量 + 1) * 2 # 输出第1天摘的桃子数量
print(f"第1天猴子摘了 {peaches} 个桃子。")

2.17. 递归函数 汉诺塔
汉诺塔:汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具。大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着64片黄金圆盘。大梵天命令婆罗门把圆盘从下面开始按大小顺序重新摆放在另一根柱子上。并且规定,在小圆盘上不能放大圆盘,在三根柱子之间一次只能移动一个圆盘。
柱子编号为a, b, c,将所有圆盘从a移到c可以描述为: 如果a只有一个圆盘,可以直接移动到c; 如果a有N个圆盘,可以看成a有1个圆盘(底盘) + (N-1)个圆盘,首先需要把 (N-1) 个圆盘移动到 b,然后,将 a的最后一个圆盘移动到c,再将b的(N-1)个圆盘移动到c。
请编写一个函数move(n, a, b, c) ,给定输入 n, a, b, c,打印出移动的步骤:
例如,输入 move(2, ‘A’, ‘B’, ‘C’),打印出: A –> B A –> C B –> C
python"># 这里编程def move(n, a, b, c): if n == 1: print(f"{a} --> {c}") return move(n-1, a, c, b) # 将上面n-1个圆盘从a通过c移动到b print(f"{a} --> {c}") # 将最底下的圆盘从a移动到c move(n-1, b, a, c) # 将b上的n-1个圆盘通过a移动到c # 示例调用
move(2, 'A', 'B', 'C')
2.18. random库 模拟洗牌
函数 random.shuffle(x) 可以将一个序列 x 的顺序打乱。
很多人喜欢玩扑克牌,现有一手好牌,牌及顺序为:[‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘10’, ‘J’, ‘Q’, ‘K’, ‘A’],请输入一个整数 n做为随机数种子,使用shuffle(x) 函数将牌序打乱,输出一个新的牌序。
示例
输入:5
输出:[‘4’, ‘5’, ‘K’, ‘Q’, ‘A’, ‘3’, ‘8’, ‘9’, ‘2’, ‘10’, ‘7’, ‘6’, ‘J’]
python"># 这里编程import random # 定义初始牌序
cards = ['2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K', 'A'] # 输入随机数种子
n = int(input("请输入一个整数 n 作为随机数种子: ")) # 使用输入的整数 n 作为随机数种子
random.seed(n) # 打乱牌序
random.shuffle(cards) # 输出新的牌序
print(cards)

2.19. random库生成快递自提柜取件码
很多校园都放置了大量的快递自提柜,放入快递时生成一个取件码发给用户,用户凭取件码自行提取货物。
取件码的字符包括:数字0-9和字母A、B、C、D、E、F、G、H、I、J。每次从以上字符串 'ABCDEFGHIJ0123456789’中随机取一个字符,重复6次, 生成一个形如“9I16A4”的取件码,各字符的使用次数无限制。随机数种子 n由用户输入。
输入:5
输出:9I16A4
python"># 这里编程
import random
import string # 定义取件码的字符集
char_set = 'ABCDEFGHIJ0123456789' # 用户输入随机数种子
n = int(input("请输入一个整数 n 作为随机数种子: ")) # 使用输入的整数 n 作为随机数种子
random.seed(n) # 生成一个取件码
pickup_code = ''.join(random.choice(char_set) for _ in range(6)) # 输出取件码
print(pickup_code)

2.20. 模拟生成微软序列号
微软产品一般都一个25位的序列号,是用来区分每份微软产品的产品序列号。
产品序列号由五组被“-”分隔开,由字母数字混合编制的字符串组成,每组字符串是由五个字符串组成。
如: 36XJE-86JVF-MTY62-7Q97Q-6BWJ2 每个字符是取自于以下24个字母及数字之中的一个: B C E F G H J K M P Q R T V W X Y 2 3 4 6 7 8 9 采用这24个字符的原因是为了避免混淆相似的字母和数字,如I 和1,O 和0等,避免产生不必要的麻烦。
随机数种子函数语法为:random.seed(n)
本题要求应用random.choice()方法每次获得一个随机字符!!!
输入格式
在2行中各输入一个正整数:
第1个整数代表要生成的序列号的个数
第2个正整数代表随机数种子
输出格式
指定个数的序列号
示例
输入:
2
10
输出:
3CVX3-BJWXM-6HCYX-QEK9R-CVG4R
TVP7M-WH7P7-RGWKW-4TC3B-KGJP2
python"># 这里编程
import random
import string # 定义字符集
str1 = 'BCEFGHJKMPQRTVWXY2346789' # 输入序列号个数和随机数种子
n = int(input("请输入序列号个数: "))
s = int(input("请输入随机数种子: ")) # 设置随机数种子
random.seed(s) # 生成一个序列号
def generate_serial_number(): # 使用列表推导式和join方法生成序列号的主体部分 serial_body = ''.join(random.choice(str1) for _ in range(20)) # 使用format方法格式化字符串,插入破折号 serial_number = '-'.join(serial_body[i:i+5] for i in range(0, 20, 5)) return serial_number # 生成并打印指定个数的序列号
for _ in range(n): print(generate_serial_number())