个人博客地址
注:部分内容参考自GPT生成的内容
论文笔记:Order Matters(AAAI 20)
用于二进制代码相似性检测的语义感知神经网络
论文:《Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection》(AAAI 2020)
笔记参考:AAAI-20论文解读:基于图神经网络的二进制代码分析 | 腾讯科恩实验室官方博客 (tencent.com)
动机
传统方法通常使用图匹配算法,但这些方法慢且不准确。尽管基于神经网络的方法取得了进展(如Gemini),但它们每个基本块都是以人工选择特征的低维嵌入来表示的,通常不能充分捕获二进制代码的语义信息。其次,节点的顺序在表示二进制函数时起着重要作用,而以往的方法并没有设计提取节点顺序的方法。
另外,在Related Work中提到,(Zuo et al 2018) 使用的NLP模型也有缺点。他们通过修改编译器,在每个生成的汇编块中添加一个基本块特殊注释器,该注释器为每个生成的块注释一个唯一ID。这样,可以将来自同一源代码片段编译的两个基本块视为等效。获取相似块对是一个有监督的过程,不同操作系统或硬件架构需要训练不同的模型
方法
提出的模型:
模型的输入是二进制代码函数的控制流图(CFGs),其中每个块是带有中间表示的token序列。在语义感知上,模型使用BERT预训练接受CFG作为输入,并预训练token嵌入和块嵌入。在结构感知上,使用带GRU更新函数的MPNN来计算图的语义和结构嵌入 g s s g_{ss} gss。在顺序感知上,采用CFG的邻接矩阵作为输入,并使用CNN来计算图的顺序嵌入 g o g_{o} go。最后将它们连接起来,并使用一个MLP层来计算图嵌入 g f i n a l = M L P ( [ g s s , g o ] ) g_{final} =MLP([g_{ss}, g_{o}]) gfinal=MLP([gss,go])
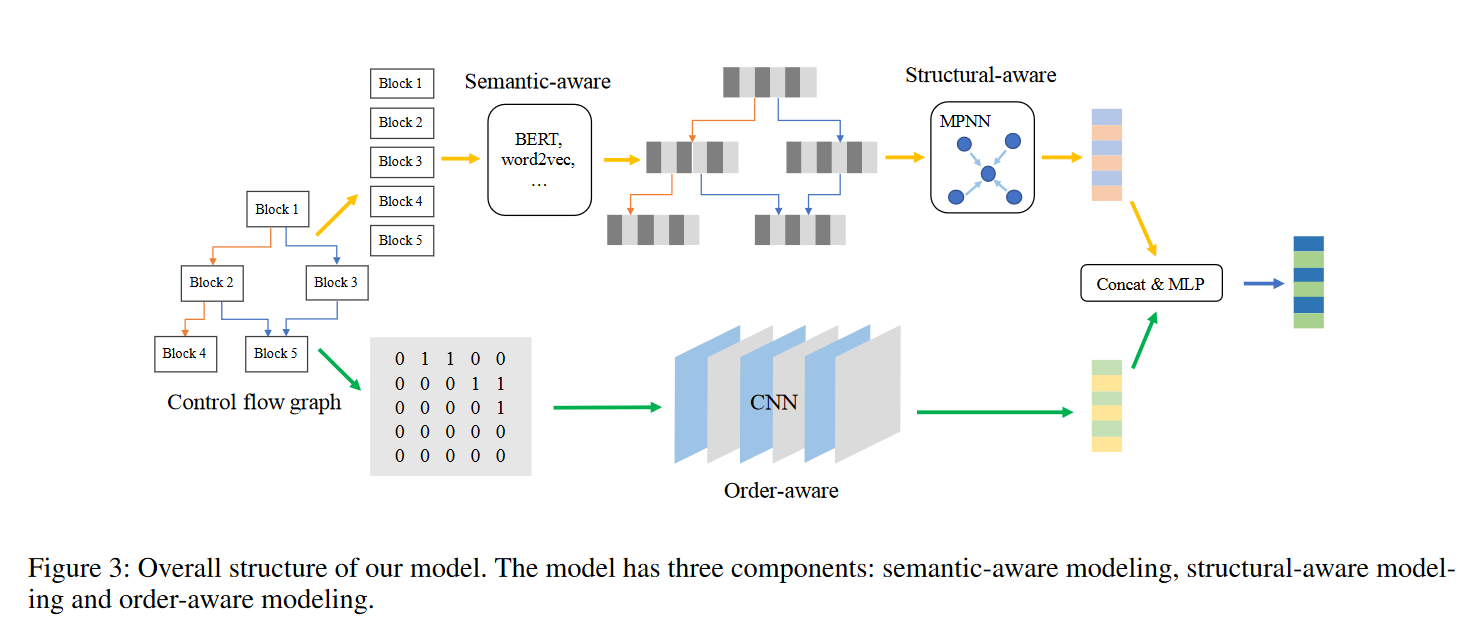
语义感知模块 (Semantic-aware Modeling)
使用BERT进行预训练,包括四个任务:掩码语言模型任务(MLM)、邻接节点预测任务(ANP)、块内图任务(BIG)和图分类任务(GC)。这些任务帮助模型提取CFG的token级别、块级别和图级别的语义信息。
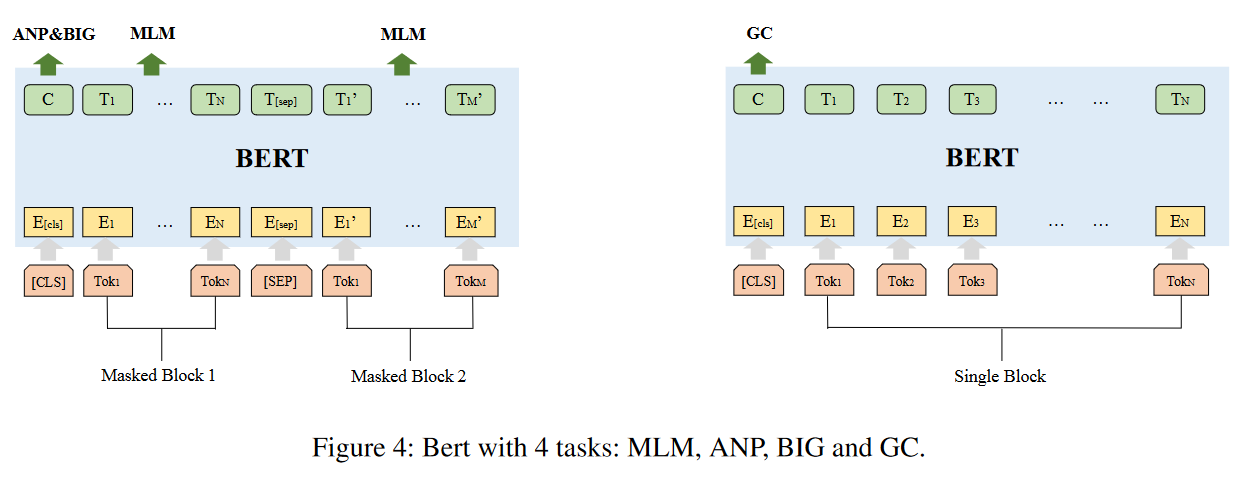
- 掩码语言模型任务(MLM):通过在输入层掩盖token并在输出层预测它们来提取块内的语义信息。这是一个自监督任务,模型在训练过程中某些token会被隐藏,模型必须基于其他token提供的上下文来预测缺失的token。
- 邻接节点预测任务(ANP):因为块的信息不仅与块本身的内容相关,还与其邻近的块相关,ANP任务旨在让模型学习这种邻接信息。它涉及提取图中所有相邻块对,并在同一图中随机抽样多个块对,以预测它们是否相邻。
- 图内块任务(BIG):与ANP类似,BIG任务旨在帮助模型判断两个节点是否存在于同一图中。它涉及随机抽样可能在同一图中或不在同一图中的块对,并预测它们的关系。这有助于模型理解块与整个图之间的关系。
- 图分类任务(GC):使模型能够基于不同平台、架构或优化选项来分类块,特别是在不同编译条件下。GC任务要求模型区分由于这些不同条件而产生的图和块信息的差异。
结构感知模块 (Structural-aware Modeling)
使用消息传递神经网络(MPNN)结合GRU(门控循环单元)更新函数,以提取CFG的全图语义和结构嵌入(the whole graph semantic & structural embedding) g s s g_{ss} gss。
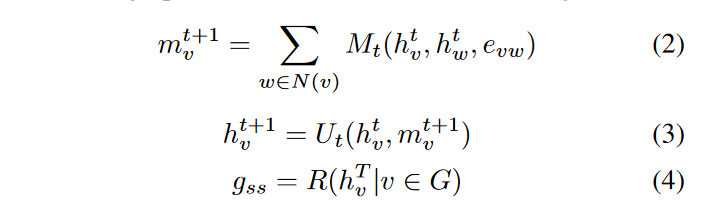
-
消息传递(Message Passing)
- 公式(2)表示的是消息传递阶段。对于图中的每个节点v,它计算了节点v在时间t+1的消息 m v t + 1 m^{t+1}_v mvt+1。这个消息是通过聚合节点v的所有邻居节点w的信息(使用消息函数M)来得到的。这里, h v t h^t_v hvt和 h w t h^t_w hwt分别代表节点v和它的邻居节点w在时间t的嵌入,而 e v w e_{vw} evw是节点v和w之间边的特征。
- 公式(5)中,论文使用了多层感知机(Multi-Layer Perceptron, MLP)对邻居节点w的嵌入 h w t h^t_w hwt进行处理。
-
更新(Update)
-
公式(3)表示的是更新阶段。在这一步中,节点v的新嵌入 h v t + 1 h^{t+1}_v hvt+1是通过更新函数U,结合节点v在时间t的嵌入和它在时间t+1收到的消息来计算的。
-
公式(6)说明了论文中的更新函数是通过GRU实现的,GRU考虑了节点的历史信息 h v t h^t_v hvt和新的消息 m v t + 1 m^{t+1}_v mvt+1,来学习图的时序信息。
-
-
读出(Readout)
- 公式(4)定义了读出函数R,它计算 g s s g_{ss} gss。这是通过对图中所有节点v的最终嵌入 h v T h^T_v hvT进行聚合来实现的。
- 公式(7)中,读出函数是通过对所有节点的初始嵌入 h v 0 h^0_v hv0和最终嵌入 h v T h^T_v hvT使用多层感知机(MLP)并进行求和来实现的。这里 h v 0 h^0_v hv0是由BERT预训练得到的初始块嵌入。
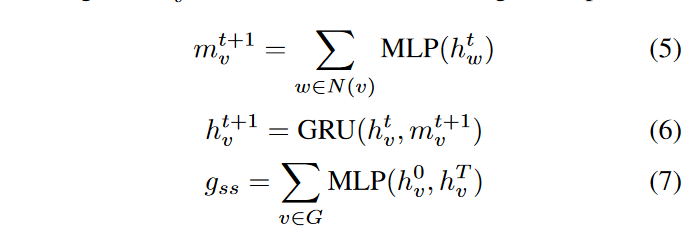
顺序感知模块 (Order-aware Modeling)
通过卷积神经网络(CNN)处理邻接矩阵,以提取CFG节点的顺序信息。
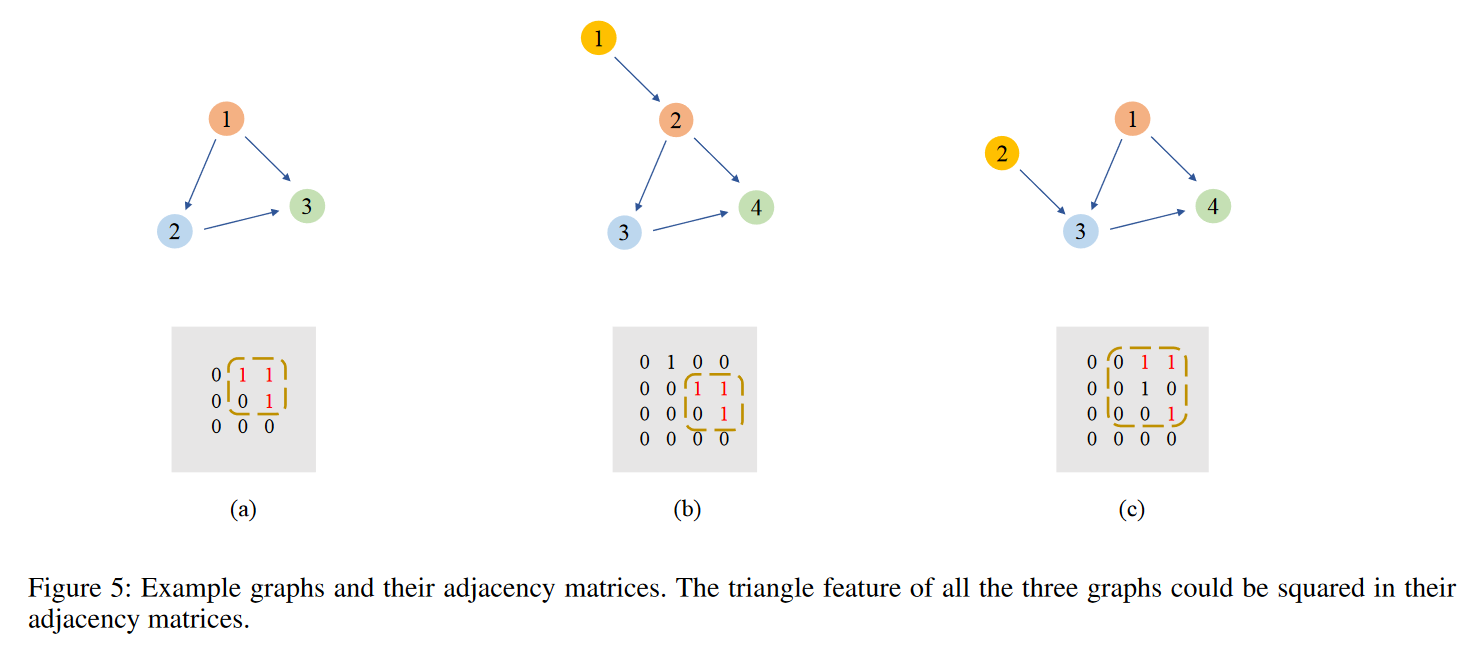
如图,CNN能捕获从(a)到(b)的变化信息,当 CNN 看到大量训练数据时,它具有平移不变性(translation invariance)
对于(b)->©,与图像放缩类似,在看到足够多的训练数据后,CNN 也可以学习这种伸缩不变性(scale invariance)。
由于二进制代码函数在不同平台上编译时节点顺序通常不会大改变,CNN能够处理由此引起的添加、删除或交换节点等小变化,优势如下:
- 使用CNN直接在邻接矩阵上的操作相比于传统的图特征提取算法要快得多。
- CNN可以处理不同大小的输入,这允许模型处理不同大小的图而无需预处理,如填充或裁剪。
使用具有 3 个残差块的 11 层 Resnet,所有的feature map大小均为3*3,最后使用最大池化层来计算图的顺序嵌入 g o = M a x p o o l i n g ( R e s n e t ( A ) ) g_o = Maxpooling(Resnet(A)) go=Maxpooling(Resnet(A))
效果
数据集:
-
任务1是跨平台二进制代码检测,目的是确认相同的源代码在不同平台上编译成的CFG是否具有较高的相似性得分。
- 与Gemini模型类似,使用孪生网络(siamese network)来减少损失,并使用余弦距离来计算图的相似性。
-
任务2是图分类,对图嵌入进行优化选项分类
- 使用softmax函数并选择交叉熵作为损失函数
由于模型具有三个组成部分:语义感知、结构感知和顺序感知,因此进行了不同的实验来找出每个部分的效果。
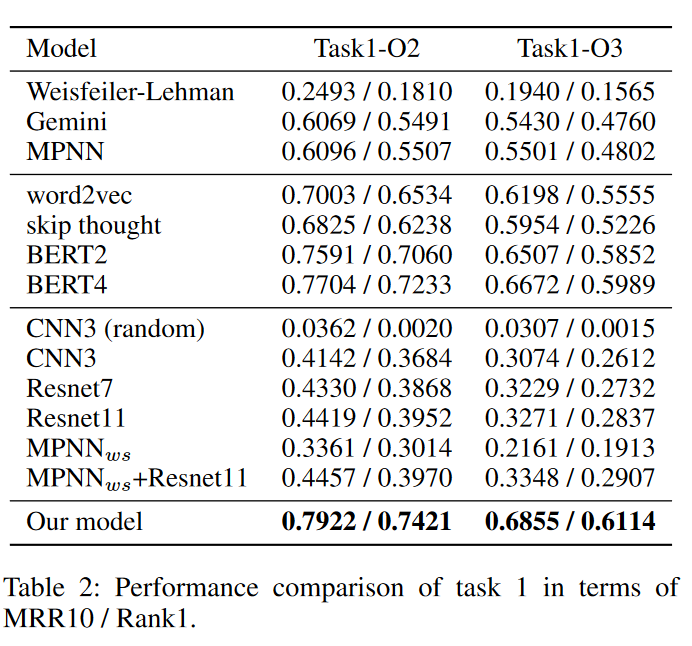
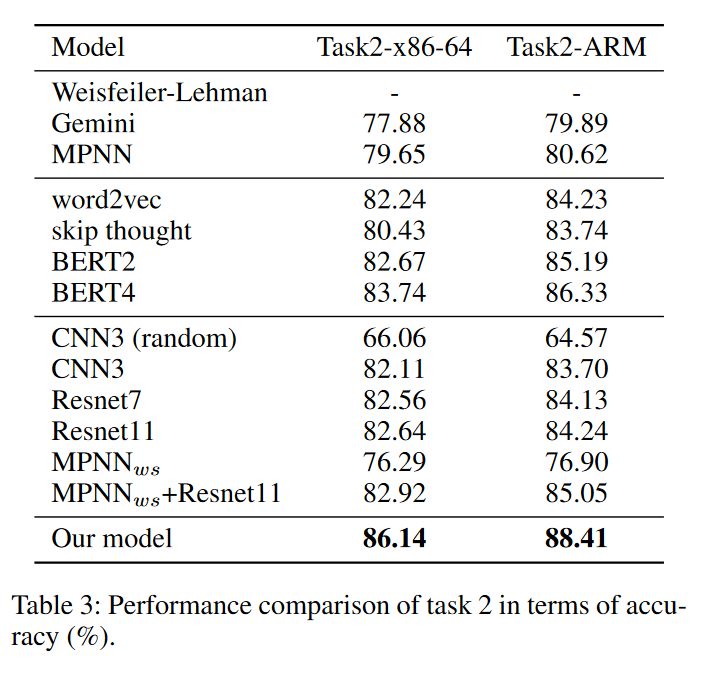
表中:
第一个分块是整体模型,包括graph kernel,Gemini以及MPNN模型。
第二个分块是语义感知模块的对比实验,分别使用了word2vec[5],skip thought[6],以及BERT,其中BERT2是指原始BERT论文中的两个task(即MLM和ANP),BERT4是指在此基础上加入两个graph-level task(BIG和GC)。
第三个分块是对顺序感知模块的对比实验,基础CNN模型使用3层CNN以及7、11层的Resnet,CNN_random是对训练集中控制流图的节点顺序随机打乱再进行训练,MPNN_ws是去除控制流图节点中的语义信息(所有block向量设为相同的值)再用MPNN训练。
最后是本文的最终模型,即BERT (4 tasks) + MPNN + 11layer Resnet。
MPNN (即加上结构感知模块)在所有数据集上都优于 Gemini,这是因为 GRU 更新函数可以存储更多信息,因此在所有其他模型中都使用 MPNN。
基于NLP的块预训练特征比手动特征好得多,并且顺序感知模块在两个任务上也有很好的结果。
在跨平台二进制代码检测任务中,语义信息比顺序信息更有用。不同的CFG可能具有相似的节点顺序,因此仅使用节点顺序信息是不够的。
最后,最终模型优于所有其他模型。
分开观察各个模块的有效性:

“语义感知(Semantic-aware)”:
- 表中的第二块显示,BERT模型的性能优于word2vec和skip thought模型。这是因为BERT在预训练过程中不仅考虑了块级别的预测,还包括了token级别的预测,并且双向Transformer结构能够提取更多有用的信息。
- 当BERT模型加入了BIG和GC两个图级任务后,性能有了1%到2%的提升,表明引入图级任务对预训练是有益的。
- 图6展示了4个控制流图(CFG)的块嵌入可视化,使用K-means算法将预训练后的块嵌入分成四个类别,每个类别用不同颜色表示。从图中可以观察到,同一控制流图中的块倾向于拥有相同的颜色,而不同控制流图的主要颜色也不同。
“顺序感知(Order-aware)”:
- 表中的第三块显示,基于CNN的模型在两个任务上都取得了良好的效果,其中11层的Resnet略优于3层的CNN和7层的Resnet。
- 与不含语义信息的MPNN(MPNN_ws)相比,基于CNN的模型表现出更好的性能。
- 节点顺序被随机打乱后,CNN的效果显著下降,这证明CNN模型确实能够学习到图的节点顺序信息。
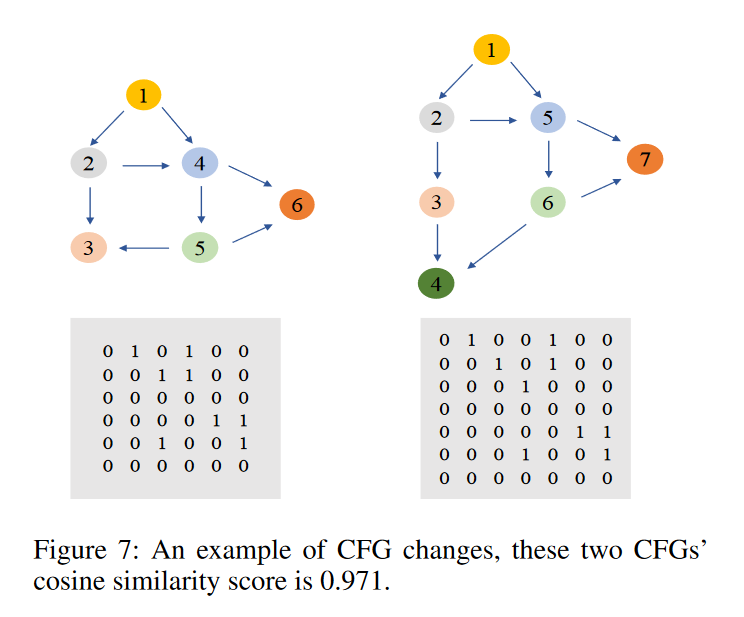
- 图7展示了两个由相同源代码编译而成的CFG变化的例子,尽管左图的节点3在右图中被分成了节点3和4,但其他节点的顺序和边的连接方式保持不变。通过CNN模型的计算,这两个CFG的余弦相似度为0.971,并且在整个平台中的代码检测排名中位列第一。这意味着CNN模型能够从邻接矩阵中有效提取控制流图的节点顺序信息,与假设相符。
结论
这篇论文提出了一个新颖的二进制代码图学习框架,包含了语义感知组件、结构感知组件和顺序感知组件。作者观察到,语义信息和节点顺序信息对于表示控制流图(CFGs)都非常重要。为了捕捉语义特征,作者提出了针对CFGs块的BERT预训练,包括两个原始任务MLM和ANP,以及两个额外的图级任务BIG和GC。然后作者使用MPNN来提取结构信息。作者进一步提出了一个基于CNN的模型来捕捉节点顺序信息。作者在两个任务上使用了四个数据集进行了实验,实验结果表明本文提出的模型超越了当时最先进的方法。
附:部分基础概念解释
由于是第一次精读深度学习相关的技术论文,我翻看了很多基础概念
MLM和NSP
MLM(Masked language model)和NSP(next sentence prediction)是BERT模型中两个重要的训练任务,它们共同帮助BERT学习理解语言的深层次结构和关系。以下是对这两个任务的具体介绍:
掩码语言模型任务(MLM)
- 目的:MLM旨在使模型能够更好地理解语言本身的规律和结构。它通过在文本中随机掩盖一些单词(即使用特殊的“[MASK]”标记替换),然后要求模型预测这些掩盖单词的原始值来实现。
- 训练过程:在训练时,BERT模型会尝试根据上下文中的其他单词来猜测被掩盖的单词是什么。例如,在句子“The cat sat on the [MASK]”中,模型需要预测被掩盖的词是“mat”。
- 作用:这种训练方式使得BERT能够有效地学习单词的上下文关系和语义信息,从而更好地理解语言。
下一个句子预测任务(NSP)
- 目的:NSP的目标是使模型能够理解句子之间的关系。这对于很多NLP任务(如问答系统、自然语言推理等)至关重要。
- 训练过程:在训练时,模型被给予一对句子,并需要判断第二个句子是否在原文中紧跟在第一个句子之后。训练集由两种类型的句子对组成:一种是真实的相邻句子对,另一种是随机组合的非相邻句子对。
- 作用:通过这种方式,BERT学习理解句子之间的逻辑和关系,增强对文本的整体理解能力。
消息传递神经网络(MPNN)
消息传递神经网络(Message Passing Neural Network)是一类图神经网络,它通过在图的节点之间交换信息来学习节点的表示。它们基于以下步骤工作:
- 消息传递:每个节点接收其邻居节点的信息,并根据这些信息生成“消息”。
- 聚合:将所有接收到的消息聚合成单个表示,这可以通过不同的函数实现,如求和、求平均或更复杂的操作。
- 更新:使用聚合的信息来更新节点的状态。
MPNN的核心思想是通过迭代这些步骤来精炼每个节点的表示,从而捕捉图的结构特征和节点之间的关系。
门控循环单元(GRU)
GRU(gated recurrent unit)是循环神经网络(RNN)的一种变体,用于处理序列数据。与传统的RNN相比,GRU通过引入门控机制来解决梯度消失和梯度爆炸的问题,使得网络能够捕捉长距离依赖关系。GRU包含两个门:
- 更新门:决定状态信息应该如何更新。
- 重置门:决定过去的状态信息在计算新状态时应保留多少。
在每个时间步,GRU可以选择保留旧状态的信息并融入新输入的信息,这使得它在处理具有复杂依赖结构的数据时非常有效。
多层感知机 (MLP)
- 定义:多层感知机是一种基础的人工神经网络,由一个输入层、若干隐藏层和一个输出层组成。每一层由多个神经元组成,相邻层之间的神经元通过权重连接。
- 功能:MLP主要用于分类和回归问题,能够识别和建模输入数据中的非线性关系。
- 工作原理:在MLP中,数据从输入层进入,每个神经元对输入进行加权求和,再加上一个偏置项,最后通过激活函数进行非线性转换。这个过程在每个隐藏层中重复进行,直到输出层。在输出层,数据被转换为最终的输出格式(如分类标签或回归值)。
卷积神经网络 (CNN)
- 定义:卷积神经网络是一种深度学习网络,特别适用于处理具有网格结构的数据,如图像(2D网格)和声音(1D网格)。
- 功能:CNN广泛应用于图像和视频识别、图像分类、医学图像分析、自然语言处理等领域。
- 工作原理:CNN通过一系列卷积层、池化层和全连接层处理数据。卷积层使用卷积核提取空间特征,池化层(如最大池化)则减小特征维度并提供一定程度的位置不变性。最后,全连接层将提取的特征用于分类或回归任务。
最大池化 (MaxPooling)
- 定义:最大池化是一种池化操作,常在卷积神经网络中使用,用于减小特征图的空间尺寸。
- 功能:最大池化通过降低参数数量和计算量来减少过拟合,同时保持重要特征。
- 工作原理:最大池化通过在输入特征图的不同区域上应用一个固定大小的窗口,并从每个窗口中选择最大值来实现。这样做可以提取最显著的特征,并且对小的位置变化保持不变性。
残差网络 (ResNet)
- 定义:ResNet是一种深度卷积神经网络,通过引入残差学习框架来易于优化,并能够构建更深的网络。
- 功能:ResNet在图像识别、分类和其他计算机视觉任务中表现优异。
- 工作原理:在ResNet中,残差块的引入允许输入跳过一些层。每个残差块学习输入和输出的残差(差异),而不是直接学习输出。这帮助网络学习恒等映射,解决了深层网络中的梯度消失问题。