SqlNode
SqlNode接口
apply()是SqlNode 接口中定义的唯一方法,该方法会根据用户传入的实参, 参数解析该SqlNode所记录的动态SQL节点,并调用DynamicContext.appendSql()方法将解析后的SQL片段追加到DynamicContext.sqlBuilder中保存。当SQL节点下的所有SqlNode 完成解析后,我们就可以从DynamicContext中获取一条动态生成的、完整的SQL语句
public interface SqlNode {boolean apply(DynamicContext context);
}SqlNode子类实现
- StaticTextSqlNode
- MixedSqlNode
- TextSqlNode
- ForeachSqlNode
- VarDeclSqlNode
- IfSqlNode
- ChooseSqlNode
- TrimSqlNode
- WhereSqlNode
- SetSqlNode
MixedSqlNode
MixedSqlNode 中使用contents 字段(List<SqlNode>类型)记录其子节点对应的SqINode对象集合,其apply()方法会循环调用contents集合中所有SqlNode 对象的apply()方法
StaticTextSqlNode
StaticTextSqlNode中使用text字段(String类型)记录了对应的非动态SQL语句节点,其apply()方法直接将text字段追加到DynamicContext.sqlBuilder字段中
TextSqlNode
TextSqlNode表示的是包含“${}”占位符的动态SQL节点。TextSqlNode.apply()方法会使用GenericTokenParser解析“${}”占位符,并直接替换成用户给定的实际参数值
IfSqlNode
SqlNode对应的动态SQL 节点是<If>节点
public class IfSqlNode implements SqlNode {// 对象用于解析<if>节点的test表达式的值private final ExpressionEvaluator evaluator;// 记录了<if>节点中的test表达式private final String test;// 记录了<if>节点的子节点private final SqlNode contents;}TrimSqlNode & WhereSqlNode & SetSqlNode
TrimSqlNode 会根据子节点的解析结果,添加或删除相应的前缀或后缀。
public class TrimSqlNode implements SqlNode {// 该<trim>节点的子节点private final SqlNode contents;// 记录了前缀字符串(为<trim>节点包裹的SQL语句添加的前级)private final String prefix;// 记录了后缀字符串(为<trim>节点包裹的SQL语句添加的后缀)private final String suffix;// 如果<trim>节点包裹的 SQL语句是空语句(经常出现在if判断为否的情况下),删除指定的前辍private final List<String> prefixesToOverride;// 如果<trim>节点包裹的 SQL语句是空语句(经常出现在if判断为否的情况下),删除指定的后缀private final List<String> suffixesToOverride;private final Configuration configuration;
}ChooseSqlNode
如果在编写动态SQL语句时需要类似Java中的switch语句的功能,可以考虑使用<choose>、<when>和<otherwise>三个标签的组合。MyBatis会将<choose>标签解析成ChooseSqlNode, <when>标签解析成 IfSqlNode,将<otherwise>标签解析成MixedSqlNode。
public class ChooseSqlNode implements SqlNode {// <otherwise>节点对应的SqlNodeprivate final SqlNode defaultSqlNode;// <when>节点对应的IfSqlNode 集合private final List<SqlNode> ifSqlNodes;}VarDeclSqlNode
VarDeclSqlNode 表示的是动态SQL语句中的<bind>节点,该节点可以从OGNL表达式中创建一个变量,并将其记录到上下文中。在VarDeclSqlNode中通过name字段记录<bind>节点的name属性值,expression字段记录<bind>节点的value属性值。
public class VarDeclSqlNode implements SqlNode {// <bind>节点的name属性值private final String name;// <bind>节点的value属性值private final String expression;
}ForEachSqlNode
在动态SQL语句中构建IN条件语句的时候,常需要对一个集合进行迭代,MyBatis提供了<foreach>标签实现该功能。在使用<foreach>标签迭代集合时,不仅可以使用集合的元素和索引值,还可以在循环开始之前或结束之后添加指定的字符串,也允许在迭代过程中添加指定的分隔符。
public class ForEachSqlNode implements SqlNode {public static final String ITEM_PREFIX = "__frch_";// 用于判断循环的终止条件private final ExpressionEvaluator evaluator;// 迭代的集合表达式private final String collectionExpression;// 记录了该ForeachSqlNode 节点的子节点private final SqlNode contents;// 在循环开始前要添加的字符串private final String open;// 在循环结束后要添加的字符串private final String close;// 循环过程中,每项之间的分隔符private final String separator;// index是当前迭代的次数,item的值是本次迭代的元素。若迭代集合是Map,则index是键,item是值private final String item;private final String index;// 配置对象private final Configuration configuration;
}SqlNode的解析流程
SqlNode的解析流程,主要是由XMLScriptBuilder这个类来完成的,其构造方法会调用initNodeHandlerMap这个方法,这个方法会注册很多handler,即不同的标签将会由不同的handler处理。方法明细如下 :
private void initNodeHandlerMap() {nodeHandlerMap.put("trim", new XMLScriptBuilder.TrimHandler());nodeHandlerMap.put("where", new XMLScriptBuilder.WhereHandler());nodeHandlerMap.put("set", new XMLScriptBuilder.SetHandler());nodeHandlerMap.put("foreach", new XMLScriptBuilder.ForEachHandler());nodeHandlerMap.put("if", new XMLScriptBuilder.IfHandler());nodeHandlerMap.put("choose", new XMLScriptBuilder.ChooseHandler());nodeHandlerMap.put("when", new XMLScriptBuilder.IfHandler());nodeHandlerMap.put("otherwise", new XMLScriptBuilder.OtherwiseHandler());nodeHandlerMap.put("bind", new XMLScriptBuilder.BindHandler());
}除了BindHandler,上述所有的handler的handleNode方法,都会调用parseDynamicTags()方法。即sql的解析过程,我们可以看做是parseDynamicTags()方法的递归调用过程。一个子节点解析完成,会被封装成MixedSqlNode对象。parseDynamicTags源码如下:
protected MixedSqlNode parseDynamicTags(XNode node) {List<SqlNode> contents = new ArrayList<>();NodeList children = node.getNode().getChildNodes();for (int i = 0; i < children.getLength(); i++) {XNode child = node.newXNode(children.item(i));if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {String data = child.getStringBody("");TextSqlNode textSqlNode = new TextSqlNode(data);if (textSqlNode.isDynamic()) {contents.add(textSqlNode);isDynamic = true;} else {contents.add(new StaticTextSqlNode(data));}} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628String nodeName = child.getNode().getNodeName();NodeHandler handler = nodeHandlerMap.get(nodeName);if (handler == null) {throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");}handler.handleNode(child, contents);isDynamic = true;}}return new MixedSqlNode(contents);}图示一个复杂SQL的解析结果树
<select id="listDataByCondition" resultType="map">select *from ${tableName}<where>and 1 = 1<if test="id != null or ids != null"><choose><when test="id != null">and id = #{id}</when><otherwise>and id in<foreach collection="ids" item="id" open="(" separator="," close=")">#{id}</foreach></otherwise></choose></if><if test="search != null and fieldName != null"><bind name="search" value="'%'+ search + '%' "/>and ${fieldName} like #{search}</if></where>
</select>@MapKey("id")
List<Map<String, Object>> listDataByCondition(Map<String, Object> map);xml解析结果树,如下所示

演示不同查询条件,SQL的拼接结果
查询1
@Test
public void listDataByCondition() {SqlSession sqlSession = sqlSessionFactory.openSession();CommentMapper mapper = sqlSession.getMapper(CommentMapper.class);Map<String, Object> map = new HashMap<>();map.put("tableName", "`comment`");map.put("id", 1);List<Map<String, Object>> data = mapper.listDataByCondition(map);System.out.println(data);
}根据上述查询传入的条件,执行相关Node的apply方法,会动态拼接上图所示①、②、③处,最终sql如下:
select * from `comment` where 1 = 1 and id = #{id}查询2
@Test
public void listDataByCondition() {SqlSession sqlSession = sqlSessionFactory.openSession();CommentMapper mapper = sqlSession.getMapper(CommentMapper.class);Map<String, Object> map = new HashMap<>();map.put("tableName", "`comment`");map.put("ids", Arrays.asList(1, 2, 3, 4));map.put("fieldName", "content");map.put("search", "百");List<Map<String, Object>> data = mapper.listDataByCondition(map);System.out.println(data);
}根据上述查询传入的条件,执行相关Node的apply方法,会动态拼接上图所示①、②、④、⑤、⑥、⑦处,最终sql如下:
select * from `comment`
WHERE 1 = 1
and id in (#{__frch_id_0},#{__frch_id_1},#{__frch_id_2},#{__frch_id_3})
and content like #{search}SqlSource
SqlSource接口
public interface SqlSource {BoundSql getBoundSql(Object parameterObject);}相关子类

- RawSqlSource : 封装xml中insert、delete、update、select、selectKey标签或java文件中@Insert、@Update、@Delete、@Select、@SelectKey注解的解析结果,并且解析结果中只存在StaticTextSqlNode (MixedSqlNode除外)
- DynamicSqlSource : 封装xml中insert、delete、update、select、selectKey标签或java文件中@Insert、@Update、@Delete、@Select、@SelectKey注解的解析结果,并且解析结果中含有除StaticTextSqlNode外的其他Node(MixedSqlNode除外)
- StaticSqlSource : RawSqlSource和DynamicSqlSource的辅助类
- ProviderSqlSource : 封装java文件中@InsertProvider、@UpdateProvider、@DeleteProvider、@SelectProvider注解的解析结果
getBoundSql
RawSqlSource
RawSqlSource会在构造方法中,直接解析原始sql。解析流程会将原始sql中占位符的名称封装成ParameterMapping对象,然后再将占位符替换成'?'。最后将解析结果赋值给内部属性sqlSource,这个sqlSource的类型是StaticSqlSource

RawSqlSource的getBoundSql()方法,交由这个内部sqlSource获取,即最终会调用StaticSqlSource的getBoundSql()方法。

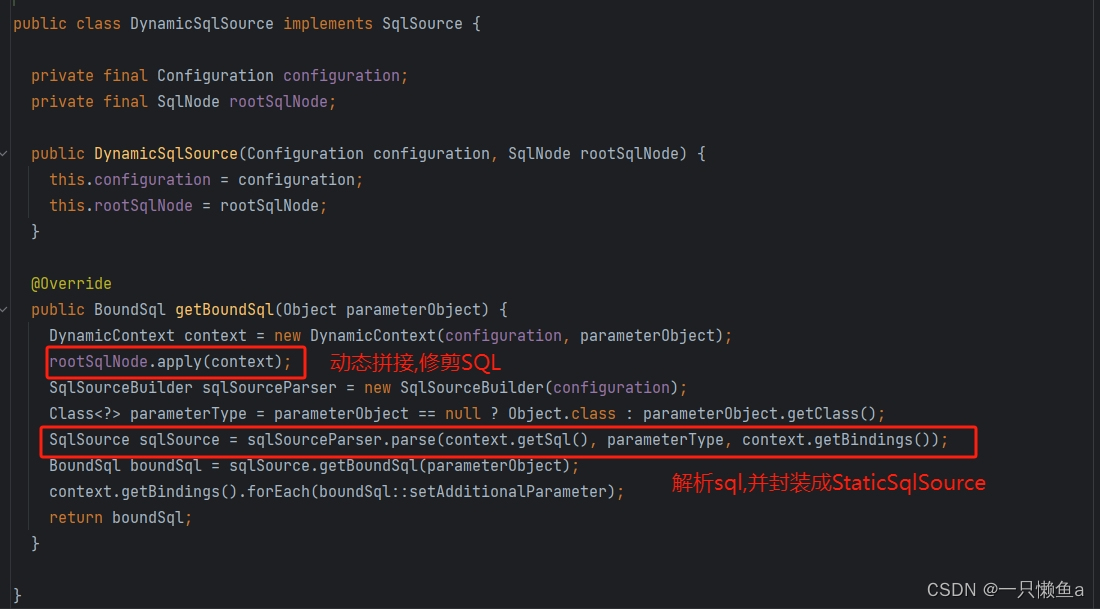
DynamicSqlSource
DynamicSqlSource的getBoundSql()方法与RawSqlSource的getBoundSql()方法大体一致。只是DynamicSqlSource的getBoundSql()方法,会在解析之前调用rootSqlNode的apply()方法。该方法会依次调用子节点的apply()方法,动态拼接、修剪sql。