20年RAG刚提出时的论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,也算是RAG的开山之作之一了。
摘要:检索增强生成(RAG)方法结合了预训练语言模型与基于检索的非参数化记忆,通过端到端训练提升知识密集型NLP任务的性能。RAG模型在多个任务上展现卓越成果,解决了传统模型的知识访问、操作及更新难题,为NLP领域带来新启示。
引言
在自然语言处理(NLP)领域,大型预训练语言模型已经在各种下游任务中取得了显著的成果。然而,这些模型在处理知识密集型任务时,如开放域问答(QA)和事实验证,仍然存在局限性。这些模型虽然能够存储大量事实知识,但在精确操作和检索这些知识方面能力有限。此外,为模型的决策提供出处(provenance)以及更新其世界知识仍然是开放的研究问题。本文提出了一种名为检索增强生成(Retrieval-Augmented Generation, RAG)的方法,旨在通过结合预训练的参数化记忆和非参数化记忆来提升模型在知识密集型任务上的性能。
方法背景与动机
传统的预训练语言模型,如BERT和GPT,虽然在许多NLP任务上表现出色,但在需要外部知识的任务中,它们的性能受限于其参数化的知识库。这些模型无法轻松扩展或修改其记忆,也难以提供对其预测的洞察,有时甚至会产生“幻觉”。为了解决这些问题,研究者们提出了结合参数化记忆(如预训练的语言模型)和非参数化记忆(基于检索的记忆)的混合模型。
在知识密集型自然语言处理任务中,传统的预训练语言模型面临以下几个主要问题:
- 知识访问与操作限制:尽管预训练模型能够存储大量知识,但它们在精确访问和操作这些知识方面存在局限,尤其是在需要复杂推理和外部知识验证的任务中。
- 缺乏可解释性:预训练模型往往被视为“黑箱”,难以提供对其决策过程的清晰解释,这在需要高度可靠性的任务中尤为突出。
- 知识更新困难:预训练模型通常难以适应新信息或纠正错误知识,因为它们的参数化知识库一旦固定,就很难进行修改或扩展。
- 生成内容的幻觉问题:在没有足够外部知识支持的情况下,模型可能会生成与事实不符的内容,即所谓的“幻觉”。
RAG方法的动机是将预训练的序列到序列(seq2seq)模型与非参数化的密集向量索引(例如Wikipedia)相结合,通过预训练的神经检索器访问这些索引。这种方法允许模型在生成语言时利用外部知识源,从而提高在知识密集型任务上的表现。
方法详解
针对上述问题,RAG模型提出了以下解决方案:
- 检索增强的生成模型:RAG通过结合预训练的seq2seq模型(参数化记忆)和基于Wikipedia的密集向量索引(非参数化记忆),增强了模型对知识的访问和操作能力。
- 端到端训练:RAG模型通过端到端训练的方式,使得检索器和生成器能够共同学习如何最有效地利用外部知识源,而无需额外的检索监督。
- 知识源的动态更新:RAG模型的非参数化记忆允许通过替换文档索引来更新模型的知识,而无需重新训练整个模型。
- 生成内容的准确性提升:RAG模型在生成文本时,可以利用检索到的具体文档内容,从而减少幻觉的发生,并提高生成内容的准确性和事实性。
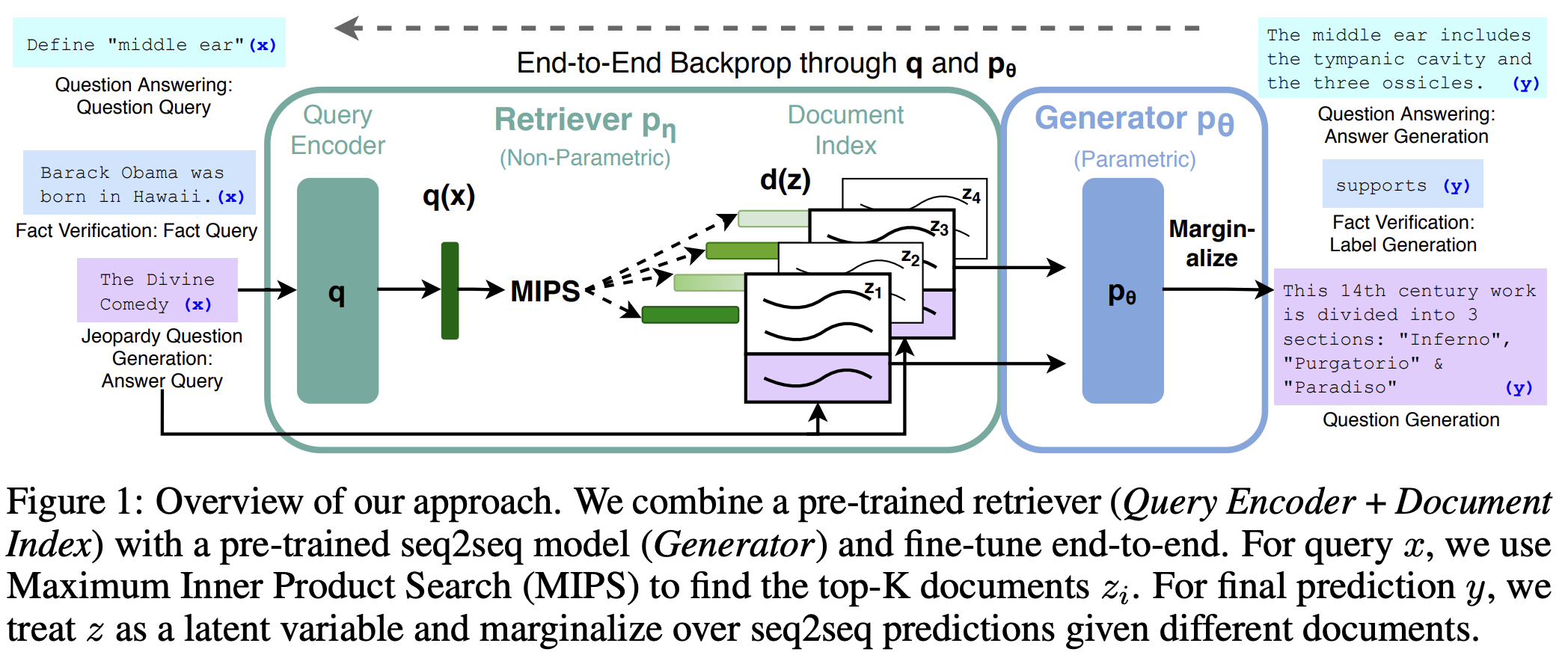
RAG模型的核心是结合了两种类型的内存:参数化内存和非参数化内存。参数化内存是一个预训练的seq2seq模型,而非参数化内存则是一个由Wikipedia文章组成的密集向量索引。以下是RAG方法的关键步骤:
- 预训练的检索器(DPR):使用Dense Passage Retriever(DPR)作为检索组件,它基于BERTBASE文档编码器和查询编码器生成文档的密集表示。
- 预训练的生成器(BART):使用BART-large作为生成组件,它是一个预训练的seq2seq变换器,具有400M参数。
- 端到端训练:通过最小化目标序列的负对数似然来联合训练检索器和生成器,不需要直接监督检索到的文档。
- 解码策略:在测试时,RAG-Sequence和RAG-Token需要不同的解码方法来近似最大似然生成序列。
- 检索增强:对于查询x,使用最大内积搜索(MIPS)找到前K个文档,然后将这些文档作为生成目标序列y的上下文。
实验分析
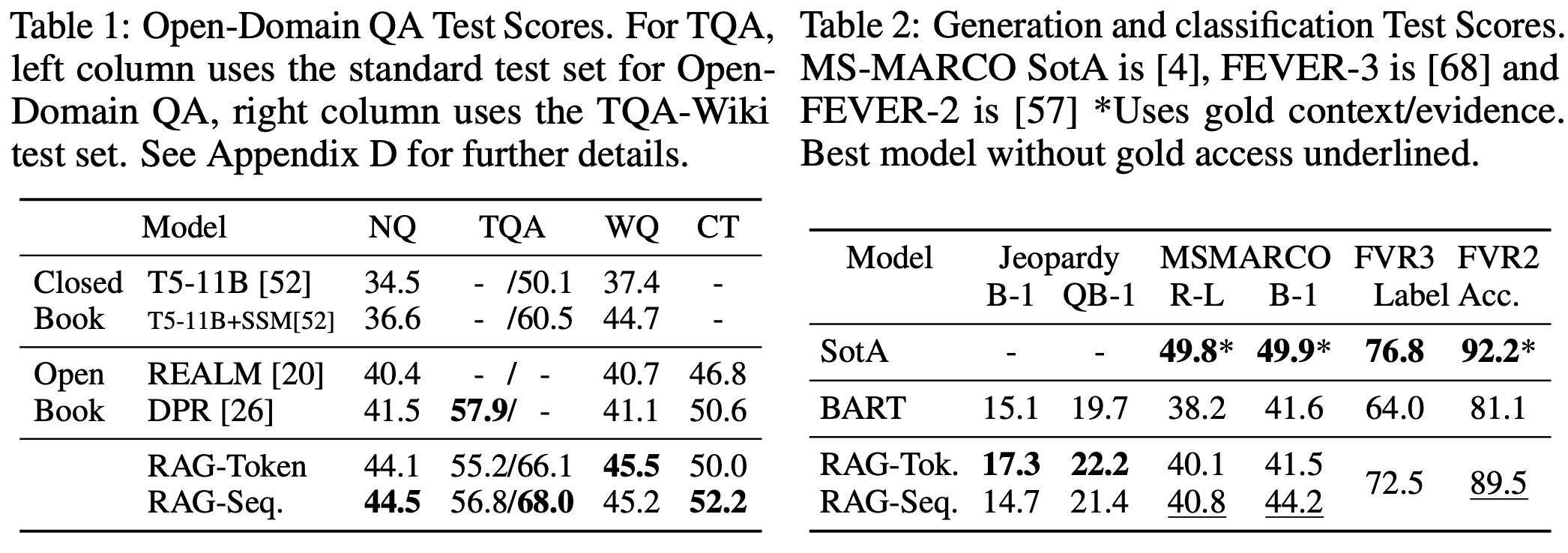
RAG模型在多个知识密集型任务上的实验结果表明:
- 性能提升:RAG在开放域QA任务上取得了最先进的结果,显示出比纯参数化seq2seq模型更强的性能。
- 生成内容的改善:在语言生成任务中,RAG生成的文本比基线模型更具体、多样且事实性更强。
- 知识更新的灵活性:通过替换非参数化记忆的索引,RAG能够适应世界知识的变化,显示出良好的适应性和灵活性。
- 可解释性的提高:尽管RAG模型的可解释性仍有待提高,但非参数化记忆的使用使得模型的决策过程更加透明,因为可以检查和验证检索到的文档。
RAG模型通过检索增强的方法,有效地解决了传统预训练语言模型在知识密集型任务中面临的挑战,提高了任务性能和生成内容的质量。然而,如何进一步提高模型的可解释性和减少训练成本,仍然是未来研究需要关注的方向。

研究者们在多个知识密集型NLP任务上对RAG模型进行了评估,包括开放域QA、抽象问答生成、Jeopardy问题生成和事实验证(FEVER)。实验结果显示,RAG模型在开放域QA任务上取得了最先进的结果,并且在语言生成任务中生成了更具体、多样和事实性更强的文本。
创新点
RAG模型的主要创新点在于:
- 混合内存架构:结合了参数化和非参数化记忆,使得模型能够利用外部知识源。
- 端到端训练:通过联合训练检索器和生成器,无需额外的检索监督。
- 灵活的检索机制:能够根据不同的输入动态检索相关信息,提高了模型的适应性和准确性。
- 实时知识更新:非参数化记忆的索引可以轻松替换,以适应世界知识的变化。
不足与挑战
尽管RAG模型在多个任务上取得了显著的成果,但仍存在一些挑战和不足:
- 检索崩溃:在某些任务中,检索器可能会“崩溃”,忽略输入的变化,导致生成器学习忽略检索到的文档。
- 训练成本:虽然不需要直接监督检索到的文档,但训练过程仍然需要大量的计算资源。
- 知识源的局限性:模型的性能受限于外部知识源的质量和覆盖范围。
- 解释性:虽然非参数化记忆提供了一定程度的可解释性,但模型的决策过程仍然不够透明。
结语
RAG模型通过结合参数化和非参数化记忆,为知识密集型NLP任务提供了一种新的解决方案。它在多个任务上的表现证明了这种方法的有效性,同时也为未来的研究提供了新的方向,特别是在如何更有效地结合参数化和非参数化记忆方面。尽管存在一些挑战,但RAG模型无疑为NLP领域带来了新的启示和可能性。