目录
1.进程创建
fork_3">1.fork函数初识
-
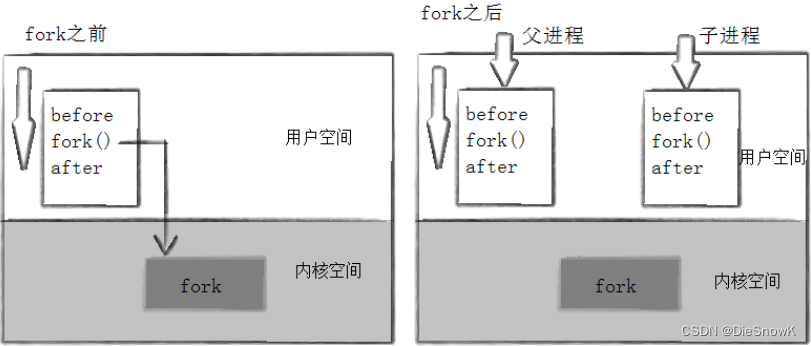
在Linux中fork函数是非常重要的函数,它从已存在进程中创建一个新进程
- 新进程为子进程,而原进程为父进程
-
进程调用fork,当控制转移到内核中的fork代码后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 必须子进程自己独有,因为进程具有独立性
- 将父进程部分数据结构内容拷贝至子进程
- 代码:都是不可被写的,只能读取,所以父子共享,没有问题
- 数据:可能被修改的,所以必须分离
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度
- 分配新的内存块和内核数据结构给子进程
-
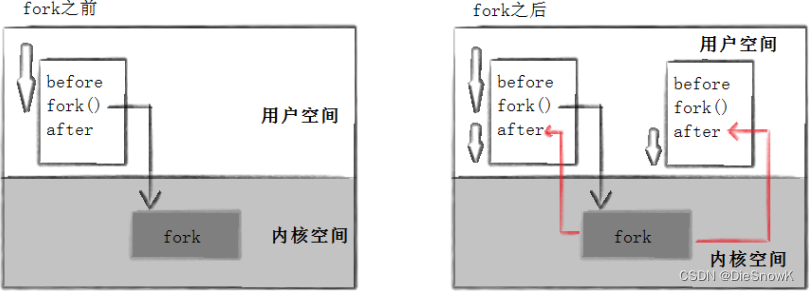
当一个进程调用fork之后,就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将可以开始它们自己的旅程
int main(void)
{pid_t pid;printf("Before: pid is %d\n", getpid());if ((pid = fork()) == -1)perror("fork()"), exit(1);printf("After:pid is %d, fork return %d\n", getpid(), pid);sleep(1);return 0;
}
运行结果
Before: pid is 43676
After:pid is 43676, fork return 43677
After:pid is 43677, fork return 0
- 进程43676先打印before消息,然后它有打印after。另一个after消息由43677打印的
- 注意到进程43677没有打印before,为什么呢?
fork_46">2.fork函数返回值
- 父进程返回的是子进程的PID
- 子进程返回0
3.写时拷贝
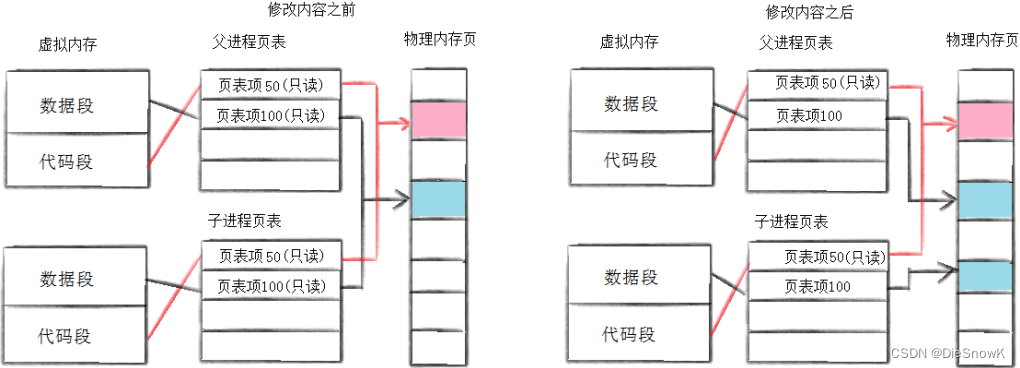
- 通常,父子代码共享,父子在不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自获得一份副本
- 为什么要这样设计呢?为什么不可以在创建进程的时候,就直接拷贝分离父子进程呢?
- 可能拷贝子进程根本就不会用到数据空间,即便是用到了,也可能只是读取
- 创建子进程,不需要将不会被访问的数据或者只会被读取的数据拷贝一份
- 但是,还必须得拷贝数据,但什么样的数据值得拷贝呢?
- 将来会被父/子进程写入的数据
- 但是,提前拷贝了,会立马使用吗?
- 一般而言,即便是OS,也无法提前知道哪些空间可能会被写入
- 综上,OS选择了"写时拷贝"技术,来进程将父子进程的数据分离
- 因为有写时拷贝的存在,所以,父子进程得以彻底分离,完成了进程独立性的技术保证
- OS为何要选择写时拷贝技术,对父子进程进行分离?
- 用的时候,再给你分配,是高效使用内存的一种表现
- OS无法在代码执行前预知哪些空间会被访问
fork_68">4.fork之后,父子进程代码共享
- 共享的代码是after之后的代码,还是所有的代码都共享呢?
- 共享的是所有的代码
- 但是执行的是fork之后的代码
fork_73">5.fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段
- 例如:父进程等待客户端请求,生成子进程来处理请求
- 一个进程要执行一个不同的程序
- 例如:子进程从fork返回后,调用exec函数
fork_79">6.fork调用失败的原因
- 系统中有太多的进程
- 实际用户的进程数超过了限制
2.进程终止
0.进程终止时,操作系统做了什么?
- 释放进程申请的相关内核数据结构和对应的数据和代码 --> 本质就是释放资源
1.进程退出场景
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码没有跑完,程序崩溃了
- main函数的返回值的意义是什么?return 0的含义是什么?为什么总是0?
- 返回给上一级进程,用来评判该进程执行结果用的,可以忽略
- 此处的0为进程的**退出码,**并不总是0
- 0:success 非0:标识的时运行的结果不正确
- 非零值有无数个,不同的非零值就可以标识不同的错误原因
- 给我们的程序在运行结束之后,结果不正确时,方便定位错误的原因细节
- 程序崩溃的时候,退出码无意义 – 一般而言退出码对应的return语句没有被执行
2.进程常见退出方法
- 可以通过echo $?查看进程退出码
- 正常终止:
- 从main函数,return 退出码
- return语句就是终止进程的
- return n等同于执行exit(n)
- 调用exit
- exit在代码的任何地方调用,都表示直接终止进程
- _exit
- 从main函数,return 退出码
- 异常退出:
- Ctrl + c,信号终止
4 _exit函数(系统接口)
void _exit(int status);
- 参数:status定义了进程的终止状态,父进程通过wait来获取该值
- **说明:虽然status是int,但是仅有低8位可以被父进程所用。所以_exit(-1)时,在终端执行$?**发现返回值是255
4.exit函数(库函数)
void exit(int status);
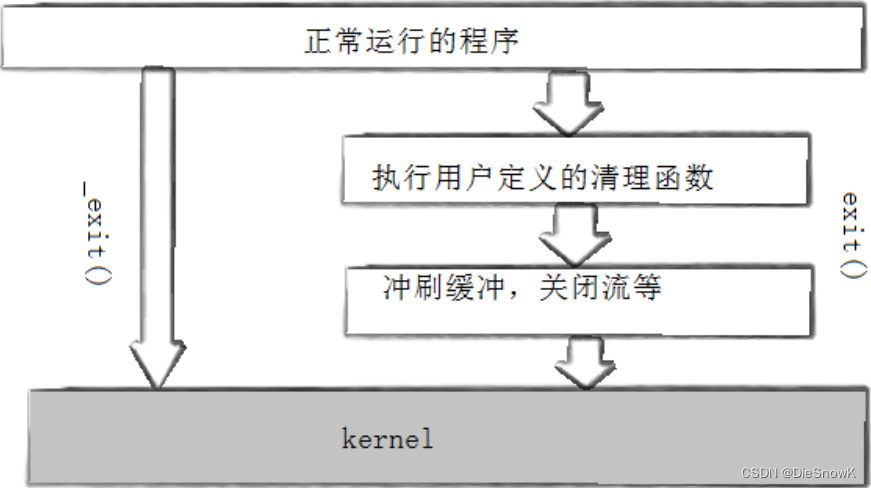
- exit最后也会调用**_exit**(库函数封装系统接口)**,**但在调用之前,还做了其他工作:
- 执行用户通过atexit或on_exit定义的清理函数
- 关闭所有打开的流,所有的缓存数据均被写入
- 调用_exit
int main()
{printf("hello");exit(0);
}// 运行结果:hello
int main()
{printf("hello");_exit(0);
}// 运行结果:(空)
3.进程等待
1.进程等待必要性
- 子进程退出,父进程若不管不顾,就可能造成"僵尸进程"的问题,进而造成内存泄漏
- 另外,进程一旦变成僵尸状态,那就刀枪不入,"杀人不眨眼"的kill -9 也无能为力
- 因为谁也没有办法杀死一个已经死去的进程
- 最后,父进程派给子进程的任务完成的如何,我们需要知道
- 如:子进程运行完成,结果对还是不对, 或者是否正常退出
- 父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
2.进程等待的方法
- wait:
pid_t wait(int *status);- 返回值:成功返回被等待进程pid,失败返回-1
- 参数:输出型参数,获取子进程退出状态,不关心则可以设置成为NULL
- waitpid:
pid_t waitpid(pid_t pid, int *status, int options);- 返回值:
- 收集到的子进程的进程ID
- 等待成功&&子进程退出
- 如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0
- 等待成功&&子进程未退出
- 如果调用中出错,则返回**-1**
- 收集到的子进程的进程ID
- 参数:
- pid:
- Pid=-1,等待任一个子进程 --> 与wait等效
- Pid>0,等待其进程ID与pid相等的子进程
- status:
- WIFEXITED(status):若为正常终止子进程返回的状态,则为真(查看进程是否是正常退出)
- WEXITSTATUS(status):若WIFEXITED非零,提取子进程退出码(查看进程的退出码)
- options:
- WNOHANG:让父进程非阻塞等待
- 若pid指定的子进程没有结束,则waitpid()函数返回0
- 默认为0,表示阻塞等待
- WNOHANG:让父进程非阻塞等待
- pid:
- 返回值:
- 注意:
- 如果子进程已经退出,调用wait/waitpid时,wait/waitpid会立即返回,并且释放资源,获得子进程退出信息
- 如果在任意时刻调用wait/waitpid,子进程存在且正常运行,则进程可能阻塞
- 如果不存在该子进程,则立即出错返回
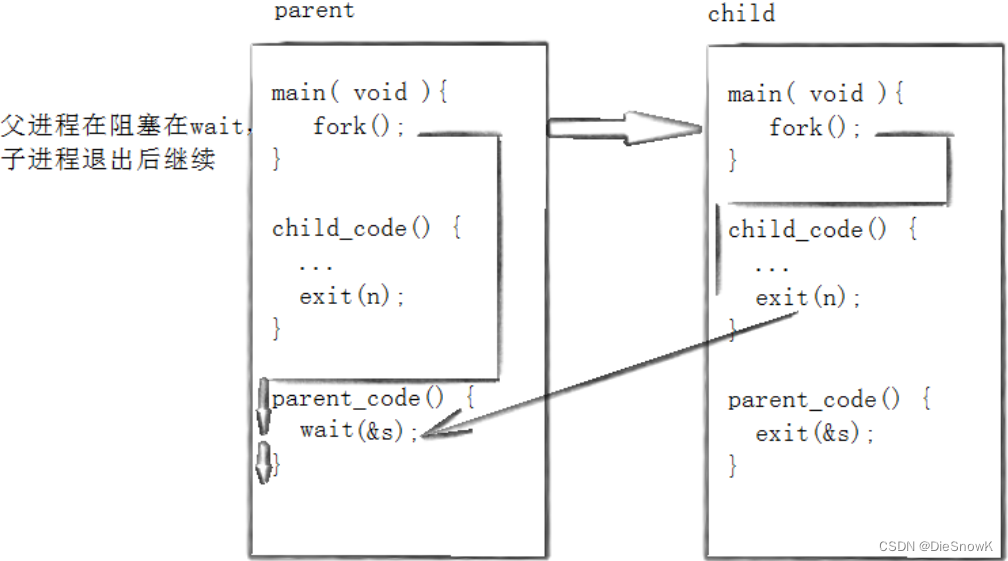
3.获取子进程status
-
wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充
- 如果传递NULL,表示不关心子进程的退出状态信息
- 否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程
-
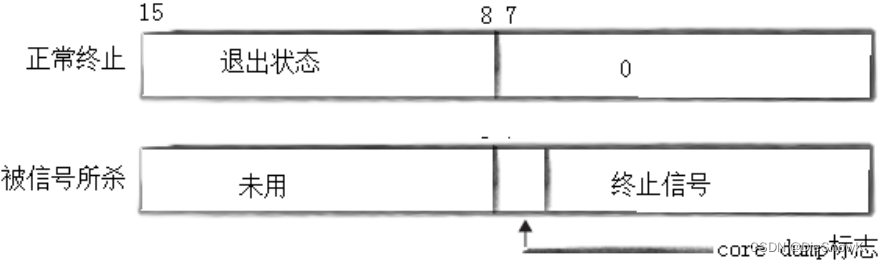
status****不能简单的当作整形来看待,可以当作位图来看待(只研究status低16比特位)
- 次低8位,表示子进程退出的退出码
- 最低7位,表示进程收到的信号
- 第8位,core dump标志
-
由此,可知:
- 进程异常退出或者崩溃,本质是操作系统杀掉了进程
- 操作系统如何杀掉进程的呢?
- 本质是通过发送信号的方式
- 程序异常,不光光是内部代码有问题,也可能是外力直接杀掉
- 子进程跑完了吗? --> 不能确定
4.思考问题
- 父进程为什么要用wait/waitpid函数拿子进程的退出结果?直接全局变量不行吗?
- 进程具有独立性,数据会进行写时拷贝,父进程无法拿到子进程修改过的数据
- 并且,信号无法通过全局变量拿到
- 既然进程是具有独立性的,进程退出码也是子进程的数据,父进程为什么能拿到?wait/waitpid究竟干了什么?
- 僵尸进程:至少要保留该进程的PCB信息
- task_struct里面保留了任何进程退出时的退出结果信息
- 本质就是读取子进程的task_struct结构
- wait/wait有权利拿task_struct里面的数据么?task_struct是内核数据结构对象
- wait/waitpid是系统调用,操作系统当然可以访问内核数据
- 僵尸进程:至少要保留该进程的PCB信息
4.进程程序替换
0.为什么要创建一个新的子进程?
- 为了不影响父进程
- 想让父进程聚焦在读取数据,解析数据,指派进程执行代码的功能
- 如果不创建,那么替换的进程只能是父进程,如果创建了,替换的进程就是子进程,而不影响父进程
1.替换原理
- 用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支)
- 但如果子进程想执行一个全新的程序,该怎么办?
- 子进程往往要调用一种exec函数以执行另一个程序
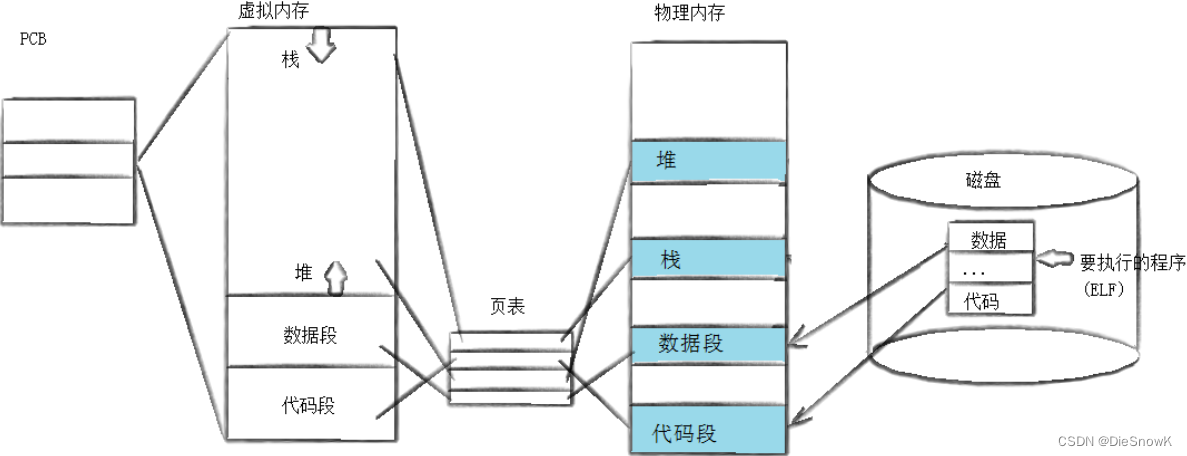
- 当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行
- 将新的磁盘上的程序加载到内存,并和当前进程的页表,重新建立映射
- 调用exec并不创建新进程,所以调用exec前后该进程的id并未改变
- 当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行
2.替换函数
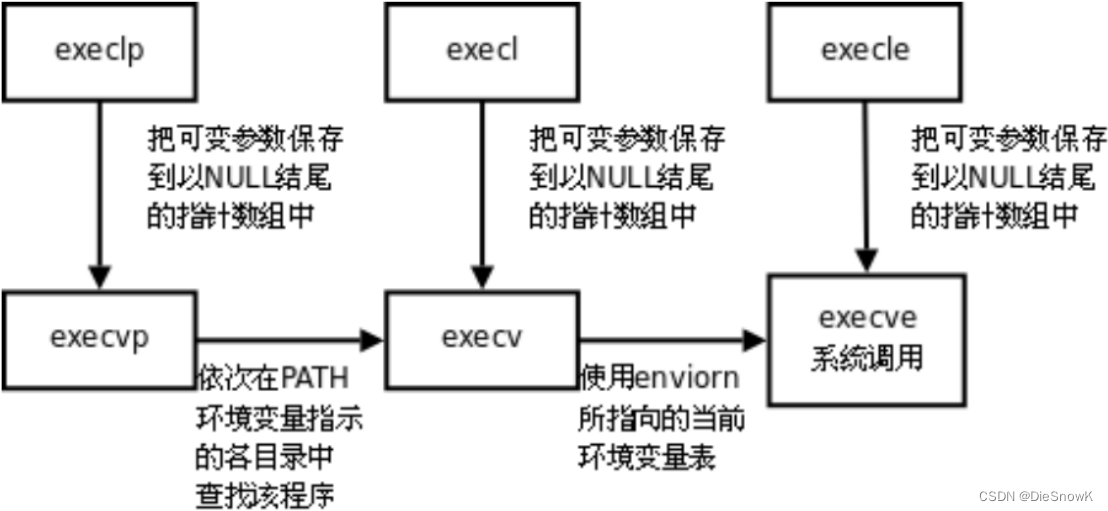
- 有六种以exec开头的函数,统称exec函数
- exec*:功能其实就是加载器的底层接口
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char *const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execve(const char *path, char *const argv[], char *const envp[]);
- 可变参数列表部分/环境变量,最后一个参数必须是NULL,标识参数传递完毕
- 这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回
- 如果调用出错则返回-1
- 所以exec函数只有出错的返回值而没有成功的返回值
- 命名理解:
- l(list) : 表示参数采用列表
- v(vector) : 参数用数组
- p(path) : 有p自动搜索环境变量PATH
- 在环境变量PATH中查找要执行的程序
- e(env) : 表示自己维护环境变量
- 注意:传参时,第一个参数都应该和要替换的程序名一样
| 函数名 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
|---|---|---|---|
| execl | 列表 | 不是 | 是 |
| execlp | 列表 | 是 | 是 |
| execle | 列表 | 不是 | 不是,须自己配置环境变量 |
| execv | 数组 | 不是 | 是 |
| execvp | 数组 | 是 | 是 |
| execve | 数组 | 不是 | 不是,须自己配置环境变量 |
- 事实上,只有execve是真正的系统调用,其它五个函数最终都调用execve
3.思考问题
- 加载新程序之前,父子的数据和和代码的关系 --> 代码共享,数据写时拷贝
- 当子进程加载新程序的时候,不就是一种"写入"么,代码要不要写时拷贝,将父子的代码分离?
- 必须分离
- 父子进程在代码和数据上就彻底分开了
- 当子进程加载新程序的时候,不就是一种"写入"么,代码要不要写时拷贝,将父子的代码分离?