模型下载和加载
在模型中使用lamma2时,如果不对模型结构进行改造,那么直接调用Transformers定义的lamma模型即可:
参考官方教程:https://huggingface.co/docs/transformers/model_doc/llama2
from transformers import LlamaForCausalLM, LlamaTokenizertokenizer = LlamaTokenizer.from_pretrained("/output/path")
model = LlamaForCausalLM.from_pretrained("/output/path")
这里使用的LlamaForCausalLM时Transformers写的一个用于文本生成的模型
我们在下载Lamma2模型的权重时,填写申请表格一出现 'China' 网页就没了,是不是不让中国用户使用lamma2了啊?
所以只能通过其他手段下载模型权重了,下载后的目录长这样:
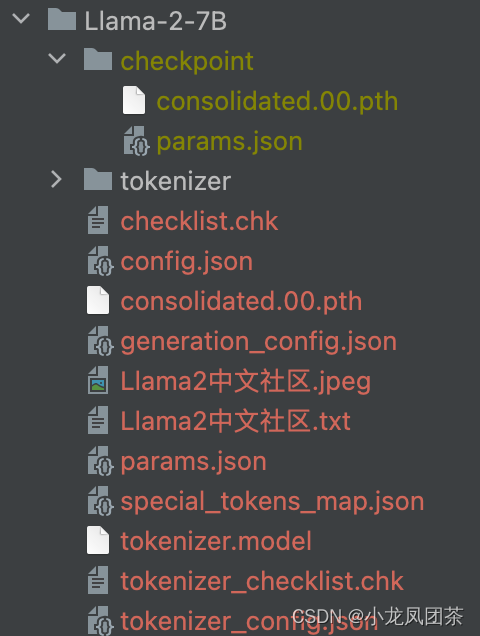
Transformer不能直接加载这个模型,按照官方教程转换为hf格式
python src/transformers/models/llama/convert_llama_weights_to_hf.py \--input_dir /path/to/downloaded/Llama-2-7B --model_size 7B --output_dir /output/path这里的convert_llama_weights_to_hf.py脚本需要在这里下载
这时候再用 /output/path就可以使用 from_pretrained(/output/path)加载预训练模型了
但是:
Loading LLaMA model does not use GPU memory neither offload folder
模型被加载到了CPU,没有使用GPU 内存啊,我们在加载模型时要添加一些参数:
lamma_model = LlamaForCausalLM.from_pretrained("/output/path",device_map="auto",torch_dtype=torch.float16)这样模型就会自动加载到GPU中了
模型批量生成
在对批量文本进行处理时,会用到 pad_token 对较短序列进行充填,但是lamma原始模型是没有pad_token的,所以需要:
lamma_tokenizer.add_special_tokens({'pad_token': '[PAD]'})lamma_model = LlamaForCausalLM.from_pretrained(lamma_model,device_map="auto",torch_dtype=torch.float16)
lamma_model.resize_token_embeddings(len(self.lamma_tokenizer))这里在tokenizer添加了一个pad_token,相比于原始的len(tokenizer)会➕1,并且将model的token_embeddings的大小增加1
否则,就会出现如下报错
CUDA error: device-side assert triggered
还有一个注意点是:
使用lamma model进行推理时(forward):其参数 input_ids 和 inputs_embeds 必须有一个为None,源码是这样的:
if input_ids is not None and inputs_embeds is not None:raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")改造模型结构
我们下载Transformer中lamma模型源码,在其基础上修改模型结构即可,常用的模型还是 LlamaForCausalLM

![[Unity]打包Android后xxx方法丢失。](/images/no-images.jpg)
![BUUCTF---misc---[SWPU2019]我有一只马里奥](https://img-blog.csdnimg.cn/direct/51422879f14b4a2e92837bd8d59042f0.png)